延續上一章節,當我們用 requests 取得網站內容後,
就可以使用 BeautifulSoup 來解析網頁資料!
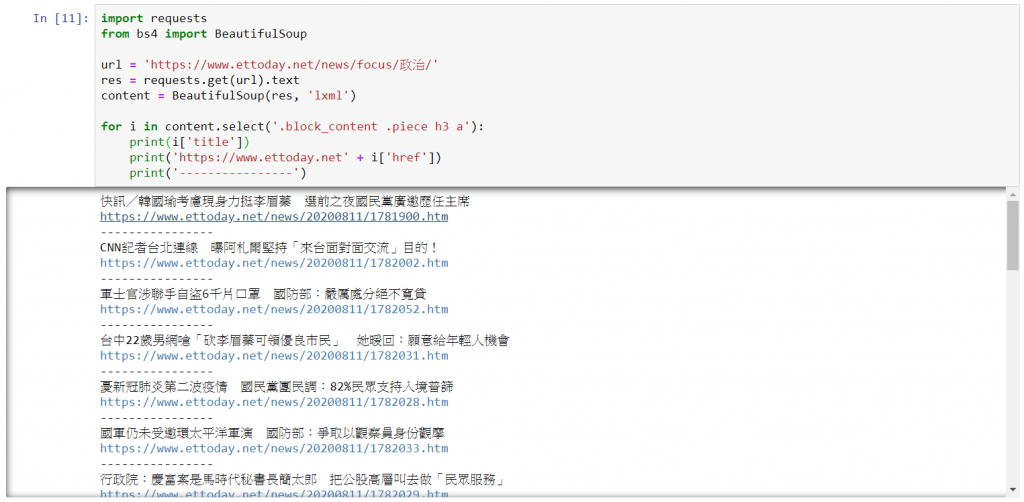
<div class="block_content">,<div class="piece clearfix">、<h3>、最後出現在 <a> 中。
程式碼:
import requests
from bs4 import BeautifulSoup
url = 'https://www.ettoday.net/news/focus/政治/'
res = requests.get(url).text
content = BeautifulSoup(res, 'lxml')
for i in content.select('.block_content .piece h3 a'):
print(i['title'])
print('https://www.ettoday.net' + i['href'])
print('----------------')
新聞中的內文均包在 <div class="story" itemprop="articleBody">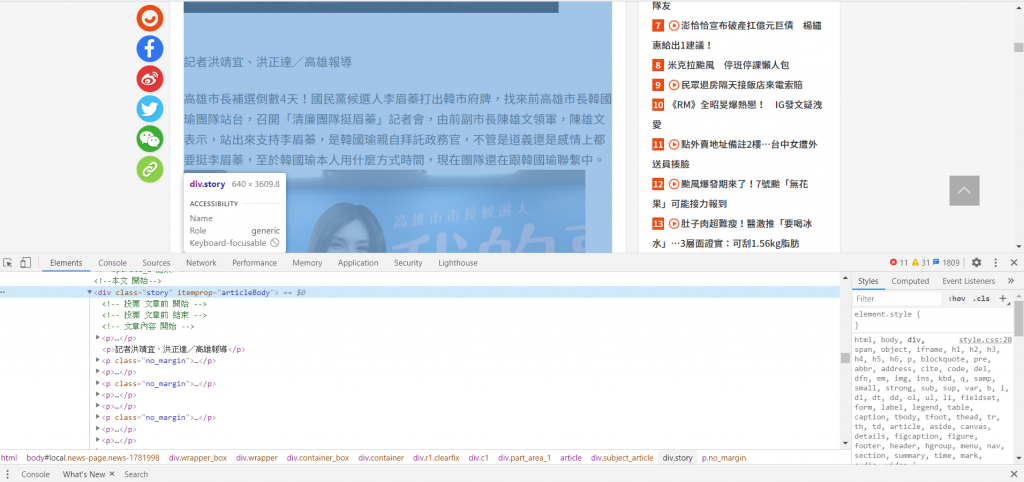
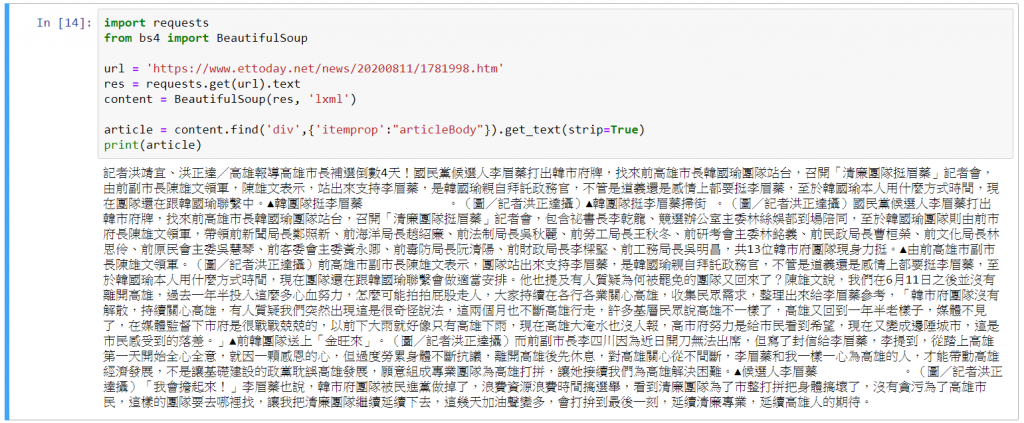
程式碼:
import requests
from bs4 import BeautifulSoup
url = 'https://www.ettoday.net/news/20200811/1781998.htm'
res = requests.get(url).text
content = BeautifulSoup(res, 'lxml')
article = content.find('div',{'itemprop':"articleBody"}).get_text(strip=True)
print(article)
 wesley41616
wesley41616
