產生 Large Size 的 Zip 壓縮檔時,如果將檔案寫入 MemoryStream,容易超出記憶體限制,引發 System.OutOfMemoryException 例外狀況。
這時可以將寫入目標,由記憶體改成網路串流 OutputStream,就能避免此問題,由於 .NET 版本眾多,這邊做個統整,紀錄一下自己的實驗心得。
首先是 MVC5 的寫法,新增 PushStreamResult 包裝 FileResult。
public class PushStreamResult : FileResult
{
private readonly Action<Stream> stream;
public PushStreamResult(string fileName, string contentType, Action<Stream> stream)
: base(contentType)
{
this.stream = stream;
this.FileDownloadName = fileName;
}
protected override void WriteFile(HttpResponseBase response)
{
response.Buffer = false;
stream(response.OutputStream);
}
}
參考文章:
https://stackoverflow.com/questions/943122/writing-to-output-stream-from-action
public ActionResult Zip()
{
var funcZIP = (Action<Stream>)((stream) =>
{
using (var archive = new ZipArchive(stream, ZipArchiveMode.Create))
{
for (var i = 0; i < 1000; i++)
{
var zipEntry = archive.CreateEntry($@"aaa{i}.pdf", CompressionLevel.Fastest);
using (var zipStream = zipEntry.Open())
{
var bytes = System.IO.File.ReadAllBytes(@"D:\專案\aaa.pdf");
zipStream.Write(bytes, 0, bytes.Length);
}
}
}
});
return new PushStreamResult("aaa.zip", "application/zip",
stream => funcZIP(new ZipWrapStream(stream)));
}
※ ZipWrapStream
由於 OutputStream 的Position屬性是不可讀的,所以需要重新包裝才能讓 ZipArchive 使用。(程式放在文章下方)
成功壓縮 1000 個 PDF 檔案。
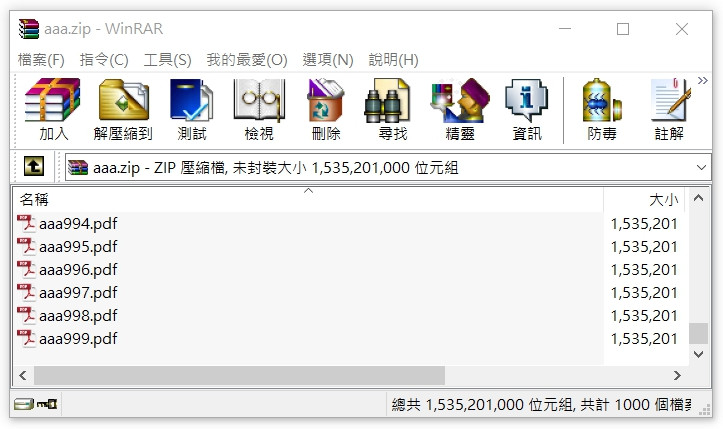
不過如果中間發生例外狀況,雖然檔案可以成功下載,但裡面的 PDF 是缺少的,且檔案會被加入錯誤訊息。
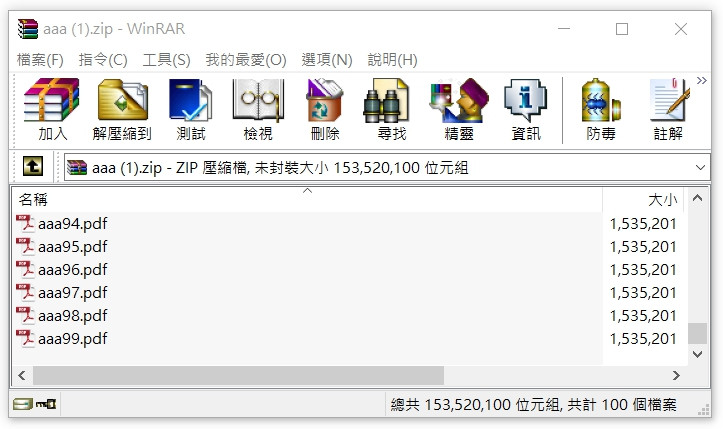
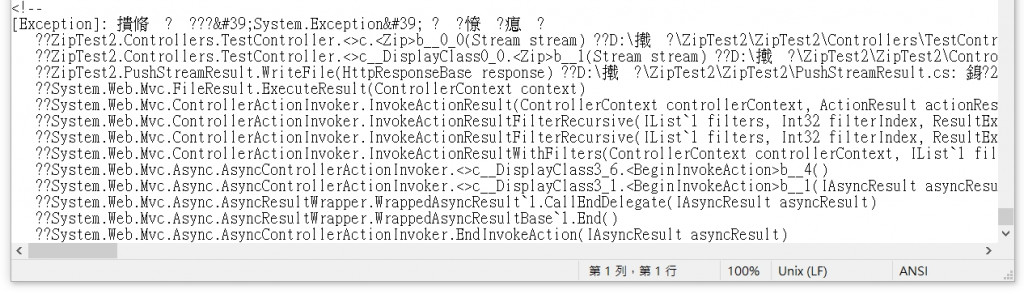
想到 Web API 有現成的 PushStreamContent 可以使用,不知道能不能解決 PDF 檔案缺失的問題。
public HttpResponseMessage Zip()
{
var funcZIP = (Action<Stream>)((stream) =>
{
using (var archive = new ZipArchive(stream, ZipArchiveMode.Create))
{
for (var i = 0; i < 1000; i++)
{
if (i == 100)
throw new Exception();
var zipEntry = archive.CreateEntry($@"aaa{i}.pdf", CompressionLevel.Fastest);
using (var zipStream = zipEntry.Open())
{
var bytes = System.IO.File.ReadAllBytes(@"D:\專案\aaa.pdf");
zipStream.Write(bytes, 0, bytes.Length);
}
}
}
});
var response = new HttpResponseMessage(HttpStatusCode.OK);
response.Content = new PushStreamContent((stream, content, transport) =>
{
funcZIP(new ZipWrapStream(stream));
stream.Close();
});
response.Content.Headers.ContentDisposition = new ContentDispositionHeaderValue("attachment");
response.Content.Headers.ContentType = new MediaTypeHeaderValue("application/zip");
response.Content.Headers.ContentDisposition.FileName = "aaa.zip";
return response;
}
使用 Web API 就不會缺檔了,會直接出現網路錯誤。 

.NET Core 和 MVC5 一樣沒有內建功能可以用,需要自己包裝 FileResult。
public class FileCallbackResult : FileResult
{
private readonly Func<Stream, ActionContext, Task> callback;
public FileCallbackResult(string fileName, string contentType, Func<Stream, ActionContext, Task> callback)
: base(contentType)
{
this.callback = callback;
this.FileDownloadName = fileName;
}
public override Task ExecuteResultAsync(ActionContext context)
{
var executor = new FileCallbackResultExecutor(context.HttpContext.RequestServices.GetRequiredService<ILoggerFactory>());
return executor.ExecuteAsync(context, this);
}
private sealed class FileCallbackResultExecutor : FileResultExecutorBase
{
public FileCallbackResultExecutor(ILoggerFactory loggerFactory)
: base(CreateLogger<FileCallbackResultExecutor>(loggerFactory))
{
}
public Task ExecuteAsync(ActionContext context, FileCallbackResult result)
{
SetHeadersAndLog(context, result, null, false);
return result.callback(context.HttpContext.Response.Body, context);
}
}
}
參考文章:
https://stackoverflow.com/questions/42771409/how-to-stream-with-asp-net-core
public ActionResult Zip()
{
return new FileCallbackResult("aaa.zip", "application/zip", async (stream, _) =>
{
using (var archive = new ZipArchive(new ZipWrapStream(stream), ZipArchiveMode.Create))
{
for (var i = 0; i < 1000; i++)
{
if (i == 100)
throw new Exception();
var zipEntry = archive.CreateEntry($@"aaa{i}.pdf", CompressionLevel.Fastest);
using (var zipStream = zipEntry.Open())
{
var bytes = await System.IO.File.ReadAllBytesAsync(@"D:\專案\aaa.pdf");
await zipStream.WriteAsync(bytes, 0, bytes.Length);
}
}
}
stream.Close();
});
}
一樣會有缺檔案的問題。
Webform 也測看看。
public void ProcessRequest(HttpContext context)
{
var funcZIP = (Action<Stream>)((stream) =>
{
using (var archive = new ZipArchive(stream, ZipArchiveMode.Create, true))
{
for (var i = 0; i < 1000; i++)
{
if (i == 100)
throw new Exception();
var zipEntry = archive.CreateEntry($@"aaa{i}.pdf", CompressionLevel.Fastest);
using (var zipStream = zipEntry.Open())
{
var bytes = System.IO.File.ReadAllBytes(@"D:\專案\aaa.pdf");
zipStream.Write(bytes, 0, bytes.Length);
}
}
}
});
HttpContext.Current.Response.BufferOutput = false;
HttpContext.Current.Response.Clear();
HttpContext.Current.Response.ContentType = System.Net.Mime.MediaTypeNames.Application.Zip;
HttpContext.Current.Response.AddHeader("content-disposition", "attachment; filename=" + HttpContext.Current.Server.UrlEncode("aaa.zip"));
funcZIP(new ZipWrapStream(HttpContext.Current.Response.OutputStream));
HttpContext.Current.Response.Flush();
HttpContext.Current.Response.Close();
HttpContext.Current.Response.End();
}
一樣會缺檔,看來只要是寫入 OutputStream 都會。
除了 Web API 之外,其他三種方法出現 Exception 都會導致 Zip 缺檔和損毀,目前還沒有解決辦法,所以如果可以盡量使用 Web API 處理會比較好。
發現使用 Request.Abort() 可以中斷連線,讓瀏覽器下載出錯,這樣就不會有缺檔和損毀的問題。
不過 .NET Core 已經沒有 Request.Abort(),而是改成 HttpContext.Abort(),但這個方法不會真正中斷連線,檔案還是會下載成功,所以目前無解。

除了 .NET Core 不建議使用外,其他版本都可以安心使用,修改後的程式如下。
public class PushStreamResult : FileResult
{
private readonly Action<Stream> stream;
public PushStreamResult(string fileName, string contentType, Action<Stream> stream)
: base(contentType)
{
this.stream = stream;
this.FileDownloadName = fileName;
}
public override void ExecuteResult(ControllerContext context)
{
try
{
base.ExecuteResult(context);
}
catch(Exception)
{
context.HttpContext.Request.Abort();
throw;
}
}
protected override void WriteFile(HttpResponseBase response)
{
response.Buffer = false;
stream(response.OutputStream);
}
}
public void ProcessRequest(HttpContext context)
{
var funcZIP = (Action<Stream>)((stream) =>
{
using (var archive = new ZipArchive(stream, ZipArchiveMode.Create, true))
{
for (var i = 0; i < 1000; i++)
{
if (i == 100)
throw new Exception();
var zipEntry = archive.CreateEntry($@"aaa{i}.pdf", CompressionLevel.Fastest);
using (var zipStream = zipEntry.Open())
{
var bytes = System.IO.File.ReadAllBytes(@"D:\專案\aaa.pdf");
zipStream.Write(bytes, 0, bytes.Length);
}
}
}
});
HttpContext.Current.Response.BufferOutput = false;
HttpContext.Current.Response.Clear();
HttpContext.Current.Response.ContentType = System.Net.Mime.MediaTypeNames.Application.Zip;
HttpContext.Current.Response.AddHeader("content-disposition", "attachment; filename=" + HttpContext.Current.Server.UrlEncode("aaa.zip"));
try
{
funcZIP(new ZipWrapStream(HttpContext.Current.Response.OutputStream));
}
catch(Exception)
{
HttpContext.Current.Request.Abort();
throw;
}
HttpContext.Current.Response.Flush();
HttpContext.Current.Response.Close();
HttpContext.Current.Response.End();
}
由於 OutputStream 的 Position 是不可讀取的,但 ZipArchive 需要這個屬性,所以需要另外包裝 Stream 類別。
public class ZipWrapStream : Stream
{
private readonly Stream stream;
private long position = 0;
public ZipWrapStream(Stream stream)
{
this.stream = stream;
}
public override bool CanSeek { get { return false; } }
public override bool CanWrite { get { return true; } }
public override long Position
{
get { return position; }
set { throw new NotImplementedException(); }
}
public override bool CanRead { get { throw new NotImplementedException(); } }
public override long Length { get { throw new NotImplementedException(); } }
public override void Flush()
{
stream.Flush();
}
public override int Read(byte[] buffer, int offset, int count)
{
throw new NotImplementedException();
}
public override long Seek(long offset, SeekOrigin origin)
{
throw new NotImplementedException();
}
public override void SetLength(long value)
{
throw new NotImplementedException();
}
public override void Write(byte[] buffer, int offset, int count)
{
position += count;
stream.Write(buffer, offset, count);
}
}
整理好文,讚!
另外想詢問 , 大大為何有需要大檔案放 RAM 的需求呢 ?
我這邊做 ZIP 放 RAM 通常是不想用到 IO , 並且會另外限制大小不能超過 100MB
假如是大檔案,我這邊作法會建立檔案,讓 nginx 代理下載文件 , 可以避免這問題
感謝!! 
大大為何有需要大檔案放 RAM 的需求呢 ?
我這邊做 ZIP 放 RAM 通常是不想用到 IO
主要是產生 Zip 需要提供一個串流讓他寫入,一般常用的會是 MemoryStream
var stream = new MemoryStream();
using (var archive = new ZipArchive(stream, ZipArchiveMode.Create))
然後 Action 就可以直接回傳
return File(stream.ToArray(), "application/zip");
恩...其實就是不想用到 IO,哈哈哈
用到 IO 就需要去清理過期的檔案,有點麻煩
假如是大檔案,我這邊作法會建立檔案,讓 nginx 代理下載文件
這個不錯,不過我想問這個方法會需要寫程式來清理垃圾檔案嗎?
研究這個其實是我比較偏好檔案不落地,盡量不要用到檔案串流
使用上 MemoryStream > OutputStream > FileStream
了解
 小碼農米爾
小碼農米爾
