記錄學習內容。
主要是看網路上的文章和影片,做些紀錄。
內容可能有錯誤。
拿一些中文、英文、數字,試試看Tesseract :
黑底白字辨識不到: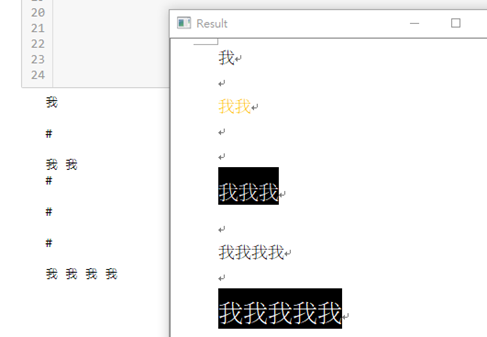
不知道為什麼,增加一行就辨識不到了: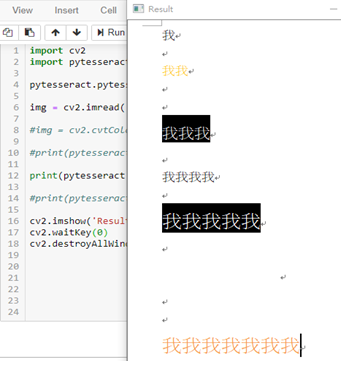
中文辨識,可以辨識到數字和英文: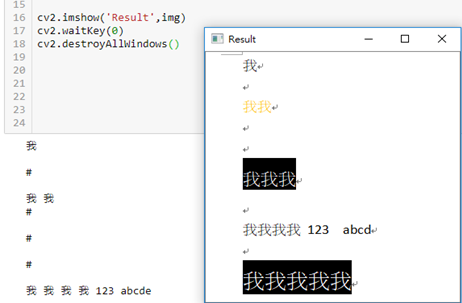
結果:
如果用英文辨識中文會變成這樣:
網址部分變準 :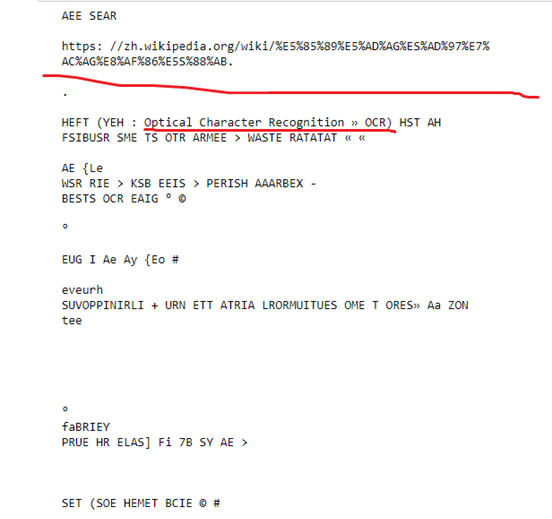
然後文章有說,如果中英文辨識,要自己訓練中英文:
print(pytesseract.image_to_string(img, lang="chi_tra+eng"))
看起來確實比較奇怪: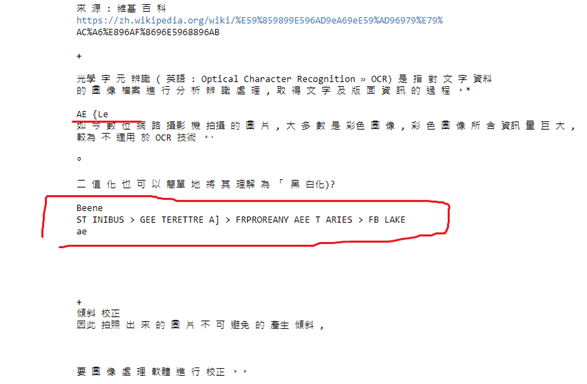
大概花了3秒
內容: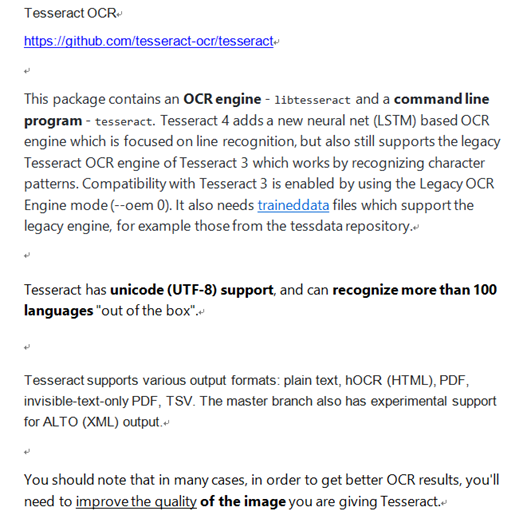
結果: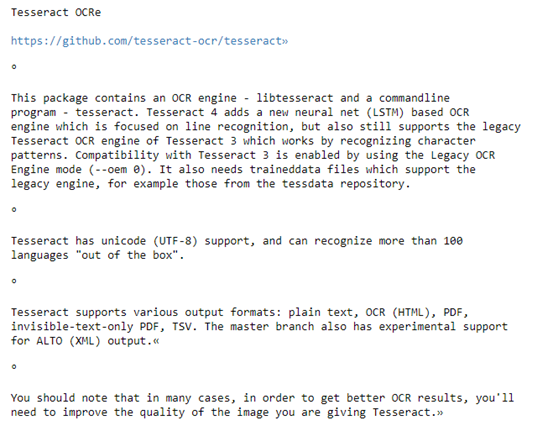
如果用中文辨識英文:
print(pytesseract.image_to_string(img, lang="chi_tra"))
大概花了7秒 。
所以根據語言不同,辨識時間會不同,中文花的時間比較久。
結果:用中文辨識英文,真的比較不准:
來試試看常見的幾種格式:
日期、時間、車牌、身分證 :
結果: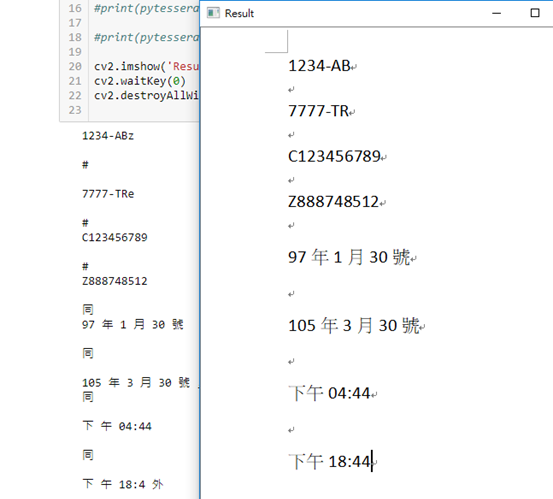
上網找一些車牌測試:
不太準。
上網找一些身分證測試:
黑底白字蠻準的 。 紅底的不太準。
然後繼續練習這部教學:
Text Detection with OpenCV in Python | OCR using Tesseract (2020)
教學裡的程式內容:
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = "C:\\Program Files\\Tesseract-OCR\\tesseract.exe"
img = cv2.imread('test.png')
print(pytesseract.image_to_string(img, lang="chi_tra"))
print(pytesseract.image_to_string(img, lang="chi_tra+eng"))
print(pytesseract.image_to_string(img))
hImg,wImg,_ = img.shape
#1格1格的字 pytesseract.image_to_boxes
'''
boxes = pytesseract.image_to_boxes(img)
for b in boxes.splitlines():
b = b.split()
#print(b)
x,y,w,h = int(b[1]),int(b[2]),int(b[3]),int(b[4])
cv2.rectangle(img,(x,hImg-y),(w,hImg-h),(0,0,255),3)
cv2.putText(img,b[0],(w,hImg-y+25),cv2.FONT_HERSHEY_COMPLEX,1,(50,50,255),2)
'''
# 1個單字
boxes = pytesseract.image_to_data(img)
for x,b in enumerate(boxes.splitlines()):
if x!=0:
b = b.split()
#print(b)
if len(b) == 12:
x,y,w,h = int(b[6]),int(b[7]),int(b[8]),int(b[9])
cv2.rectangle(img,(x,y),(w+x,h+y),(0,0,255),3)
cv2.putText(img,b[11],(x,y),cv2.FONT_HERSHEY_COMPLEX,1,(50,50,255),2)
# 只選擇數字
'''
cong = r'--oem 3 --psm 6 outputbase digits'
boxes = pytesseract.image_to_data(img,config=cong)
for x,b in enumerate(boxes.splitlines()):
if x!=0:
b = b.split()
#print(b)
if len(b) == 12:
x,y,w,h = int(b[6]),int(b[7]),int(b[8]),int(b[9])
cv2.rectangle(img,(x,y),(w+x,h+y),(0,0,255),3)
cv2.putText(img,b[11],(x,y),cv2.FONT_HERSHEY_COMPLEX,1,(50,50,255),2)
'''
cv2.imshow('Result',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
限定識別的文字,辨識效果可能更好:
Day26-聽過 OCR 嗎? 實作看看吧 -- pytesseract
https://ithelp.ithome.com.tw/articles/10227263
tesseract如何限定识别的文字
https://my.oschina.net/u/2396236/blog/1621590
搭配opencv:
【沒錢ps,我用OpenCV!】Day 18 - 進階修圖5,運用 OpenCV 做圖片二值化,產生黑白的圖片吧!cv2.threshold 各種選擇參數大全
https://ithelp.ithome.com.tw/articles/10246927


 iThome鐵人賽
iThome鐵人賽