看了其他同主題的鐵人賽文章,果然有經驗的人就是不一樣。
坦白說,看了 Elastic Stack 雲端的各項整合選項,我有點嚇到,很多都能在商業上直接發生利益。
不過煩惱的是,一般個人使用者在學習中,總不可能因此就架上好幾個伺服器吧。
只好自己先想法子先成 JSON 檔來學習。
由於個人平常的工作主要是接觸/熟悉關聯式資料庫(MySQL/Oracle/PostgreSQL/SQL Server/SQLite),所以對於 JSON 平常主要是使用者而非製作者。
這次 Elastic Stack 雲端服務要求上傳 JSON 格式,是 "Newline-delimited JSON"。
在這次 R 程式碼的處理中,遇到一些之前不清楚而一直鬼打牆的地方,後來總算搞定。
目前 elastic 在 Github 上面共有 413 個 repos,而在 Github 提供的API 一次最多回傳100筆資料。
所以簡單寫一個小迴圈,只需5次就可以全數將資料捉回;此次做為示例,所以批次輸出5個JSON 檔案。
看過網路上其他文章對於 Elastic Stack 的介紹,熟悉資料庫的朋友應該可以猜得出來,到時候,我們可以將這5個JSON放在一起集中觀察。
library(jsonlite)
for (i in 1:5) {
elastic_dataframe <- fromJSON(paste0("https://api.github.com/users/elastic/repos?per_page=100&page=", i))
stream_out(elastic_dataframe, file(paste0("elastic_json", i, ".json")))
}
今天就讓我們先上傳其中第一個檔案吧!
首先在雲端管理介面首頁中 https://cloud.elastic.co/home 點選 Quick link 底下的 Kibana , 就會帶出新的頁面;然後我們點選其中的 "Upload data from log file",再將我們的 elastic_json1.json 丟上去。
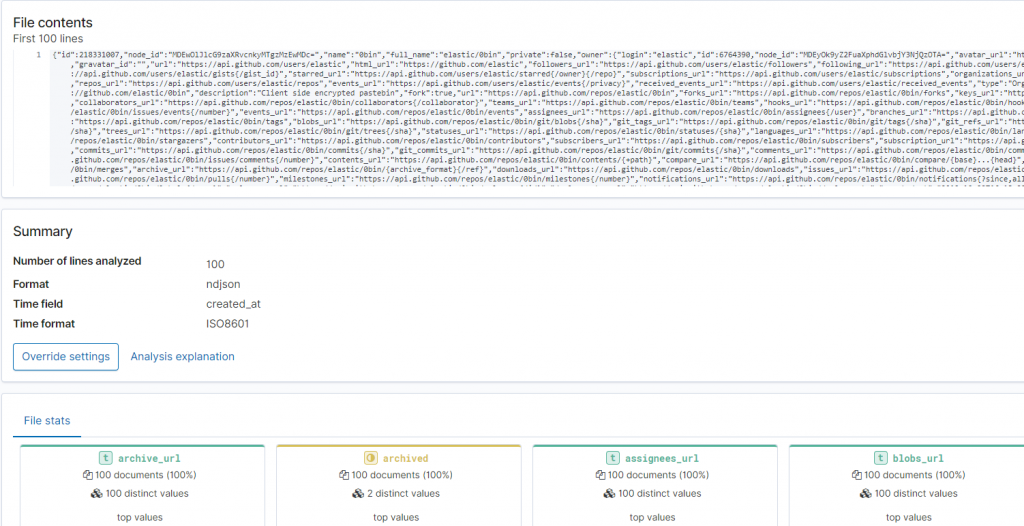
我們可以發現 Elastic Stack 會像很 BI 工具一樣,快速的告訴你目前上傳的這筆資料中,有那些特徵值。例如有多少的 True 或是 Flase。由於今天臨時想找筆資料上傳,所以先以 elastic 本家在 Github 上的 Repos 為主。這幾天會再思考一下,有什麼樣的資料集是手邊可以捉取,又可以方便上傳。
總之,這是第2天。
有機會的話,我也會想把今天簡單的幾行程式碼轉成 Python Code ;我想 Python 對於 Newline-delimited JSON 格式的產出,應該更為強大吧!

