經過昨天使用 Web GUI介面,快速匯入第一個JSON檔後。在 Elastic Stack on Cluod 的網頁中,翻來翻去,就是找不到新增第2個JSON資料的選項。後來查詢網路文件後,發現需要透過API才可以直接將第2個JSON檔案直接追加在第1個JSON檔案之後。想想也是,Elastic是企業級的應用,在實務狀況中,如果每天有新資料需要被匯入,不可能一直透過人機互動方式進行資料的CURD,必然是透過程式的方式進行。
查閱了一下文件,Elastic提供了好多的API,各司其職;今天就先簡單一點,瞭解如何透過 API 進行資料的查詢 (Query)。而在進行資料的查閱前,就先讓我們以關聯式資料庫的術語,來觸類旁通,瞭解 Elastic Search 中的各式術語。
Index 索引:
想像成是關聯式資料庫的Database。
在昨天上傳第一個 JSON 檔時,Elastic Stack on Cluod要求我為 Index 進行命名。我命名為:"elastic_json"。這缺乏想像力所導致的爛命名... 後續我可以再實作更改Index名稱,平常在公司一定不能這樣亂玩。
Fields 欄位:
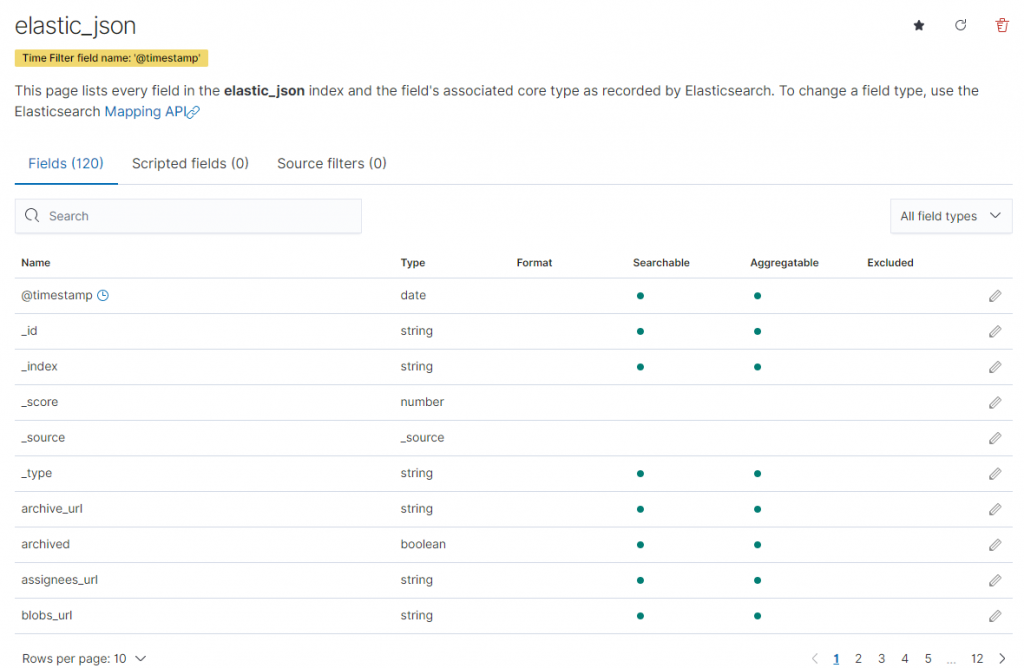
Fields:想像成是關聯式資料庫的Columns。舉例來說:昨天上傳的資料,總計有120個Fields。也像關聯式資料庫一樣,不同的Columns會有不同的資料型別。像有的資料可能是整數、日期時間、或是文字。而此處是直接由Elastic Stack on Cluod進行判斷,而資料型別自然是可以再視實際狀況進行修正
有了這最簡單的認識後,就可以開始進行 API 的查詢。如果我們今天想要查詢 elastic 在 Github 中,星星數大於2000的 repos 有幾個呢? 如果是在資料式資料庫,我們可能會這樣進行查詢
Select * from elastic_json where stargazers_count > 2000;
我們直接透過網頁上的 API Console 進行查詢
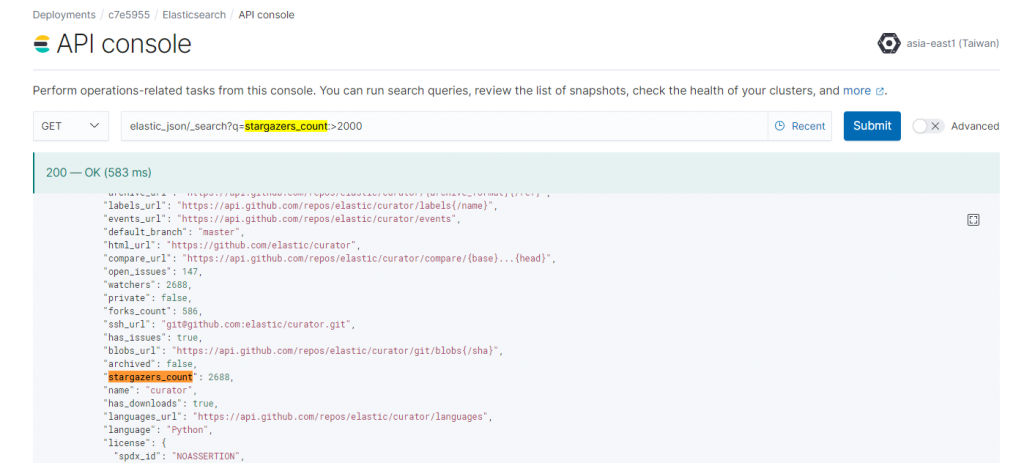
此處可以看到,過濾條件 stargazers_count > 2000 的API寫作方式。
另外在 SQL 有時我們只需要聚合值,像是資料的筆數:
Select count(*) from elastic_json where stargazers_count > 2000;
而在此處,就可以直接透過 API 回傳的資料進行判讀,星星數大於2000的有2筆資料
"total": {
"relation": "eq",
"value": 2
},
"max_score": 1
}
官方的API文件,非常詳細。
不過對於初學者來說,可以先參考這個網頁的實例介紹進行學習 https://dzone.com/articles/23-useful-elasticsearch-example-queries 以免心生挫折...
這是我第一次學習 ElasticSearch 很多在關聯式資料庫的概念無法直接適用,需要時間進行調整。畢竟鐵人賽可是足足有30天,相信接下來一定可以把每天學習結果,由點連接成線!

