對於一般人來說,Elastic Search最迷人的應該就是 NoSQL 的特性了吧。
不像一般傳統資料庫,只能依照事先定義好的 Schema 上傳資料。
可以直接將 R 的 list 資料上傳。如果對於 list 不熟的朋友,其實可以想成 JSON 格式,基本上也是類似 key : Value 這種型式,可以很靈活的進行資料的儲存。
在下面簡單的例子中,以上傳2筆資料做為示例。
第1筆資料是屬於 Tom,他的興趣有 Cook、Beer.
第2筆資料是屬於 小明,他的興趣有 "漫畫" , "電影","閱讀","音樂",同時也有居住區域與手機號碼資訊。
library("elastic")
x <- connect(
host = "aaa123.asia-east1.gcp.elastic-cloud.com",
path = "",
user = "elastic",
pwd = "aaa123",
port = 9243,
transport_schema = "https"
)
# Connect OK!
list_data <- list(
list(name="Tom", hobby = list("Cook" , "Beer") ) ,
list(name="小明", hobby = list("漫畫" , "電影","閱讀","音樂"), address="台北市大安區",
mobile ="0912546781")
)
docs_bulk(x , list_data , "list_data")
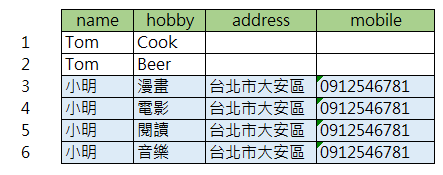
如果不使用 list 這種彈性的資料結構,以一般資料庫的表現形式會如下所示:
會發現有許多資訊是重覆被紀錄,當然可以再藉由一些資料正規化的方式進行處理。
但在實務中,你的確很難去要求使用者的興趣只能是單選,只能限制在幾個以下,所以依據不同的情境使用不同的資料庫就顯得特別重要。
同樣的,在此處我們試著找看看,興趣是 "漫畫"的有那些人。
利用昨天的 POST 進行中文字的查詢,ElasticSearch 很快地就將答案揭露,的確"小明"也在其中!



 iThome鐵人賽
iThome鐵人賽