最近因為美國平權運動的興起,所以在 R 中廣被做為示範案例的資料集 iris 有一些爭議。
因為蒐集整理 iris 的學者,在平權上有些爭議空間,所以有人提出其他的示範資料做為教學或練習資料視覺化使用。
好吧,直接上 code,一切就是這樣的簡單
# 因為這些企鵝資料並非是預設的資料集,所以要事先安裝一切哦
# install.packages("palmerpenguins")
library(palmerpenguins)
# Connect OK!
x <- connect(
host = "111.asia-east1.gcp.elastic-cloud.com",
path = "",
user = "elastic",
pwd = "111",
port = 9243,
transport_schema = "https"
)
docs_bulk(x, penguins, "df_penguins")
在這邊我特別在 index 的命名前面加上了前置詞 df_。一方面代表這是 data.frame 的資料結構,另一方面是為了等一下在網頁端上的指定設定時比較方便。
接下來讓我們到 Kibana 介面中,去尋找 "Use Elasticsearch data" : "Connect to your Elasticsearch index"。因為在上一個動作中,我們只是把資料給放到 ElasticSearch 中,這時候還沒有與 Kibana 進行連接。
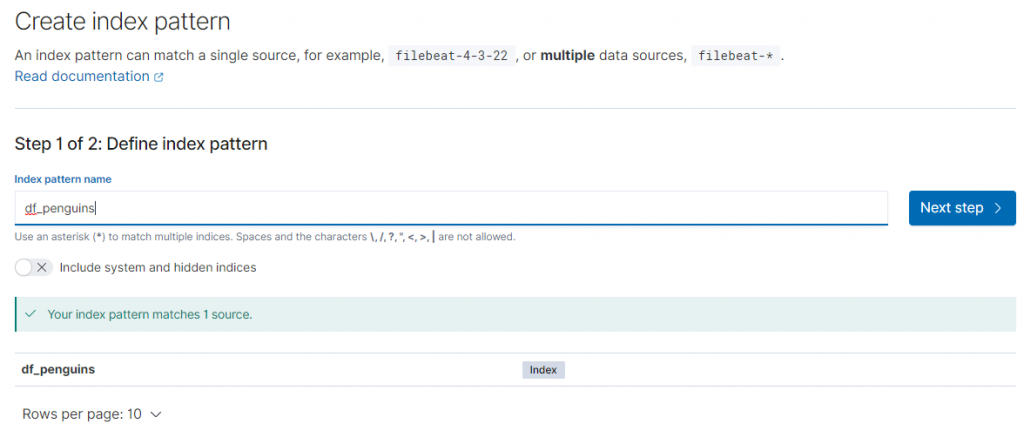
然後點選 Canvas 中,再點選"Create workpad"

我會建議直接使用 Canvas;因為 Canvas 中有直接提供 XY 散布圖;如果是 Visualzaion 的選項中,我找不到類似XY 散布圖的選項。
新增一個新的元件,此處我們選擇 Bubble Chart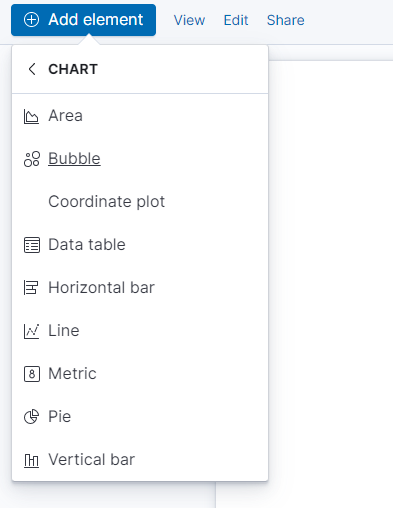
預設的資料源,是 Demo 資料,此處我們要改成我們自己的企鵝資料,所以要再點選 "ElasticSearch Docs"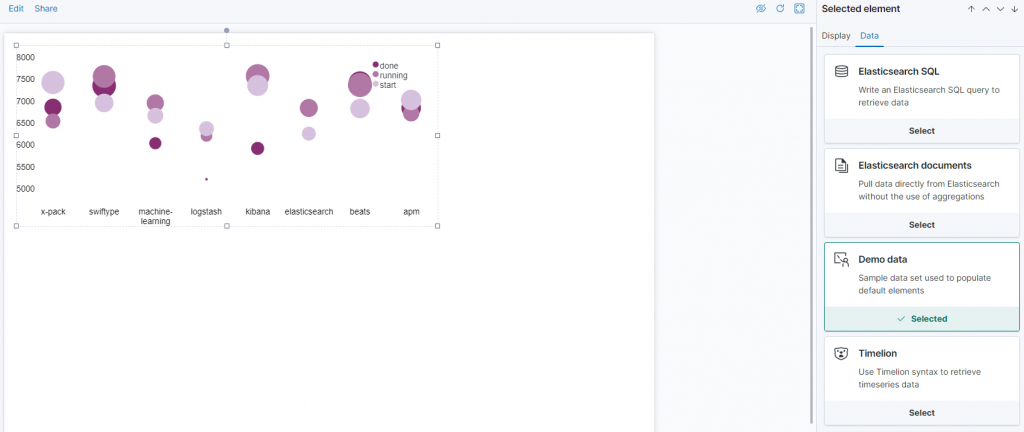
接下來就是選擇欄位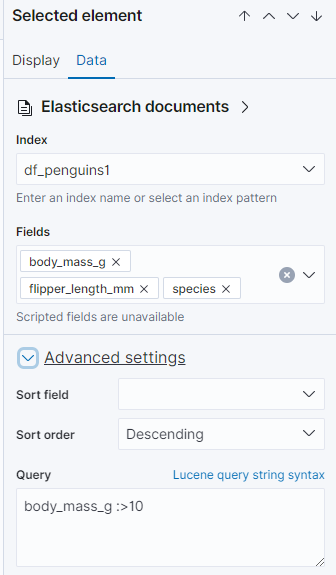
設定 X 值 Y值 與顏色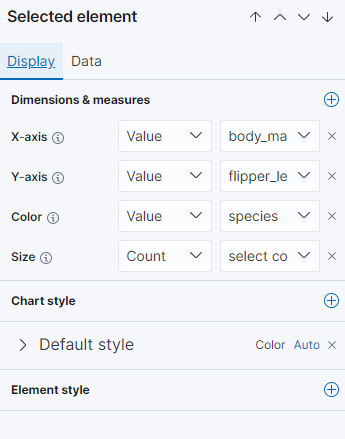
此處要注意的一個小地方,因為這個範例資料集中,有一筆資料的企鵝的資料有空值。
也就是下圖中的最後一筆資料,而在上傳後,Kibana 直接將這空值視為 0。
所以有些人一開始畫出來的圖,可能長得像是這個樣子:
會發現因為左下角的一筆異常資料,導致整個圖形顯示異常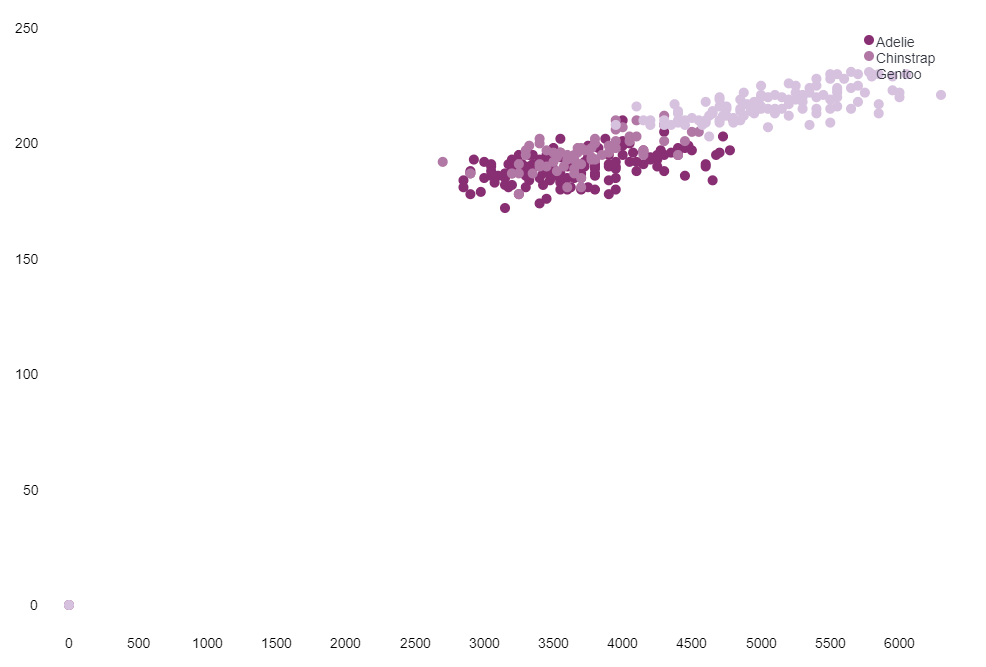
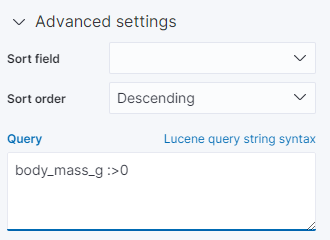
這時候,我們需要事先將這筆資料過濾掉:
所以我們需要在 Data 的 Advanced Setting 中再加上: body_mass_g :>0 ;
"今晚,我想要來點企鵝的資料視覺化" 的圖形就這樣生成囉
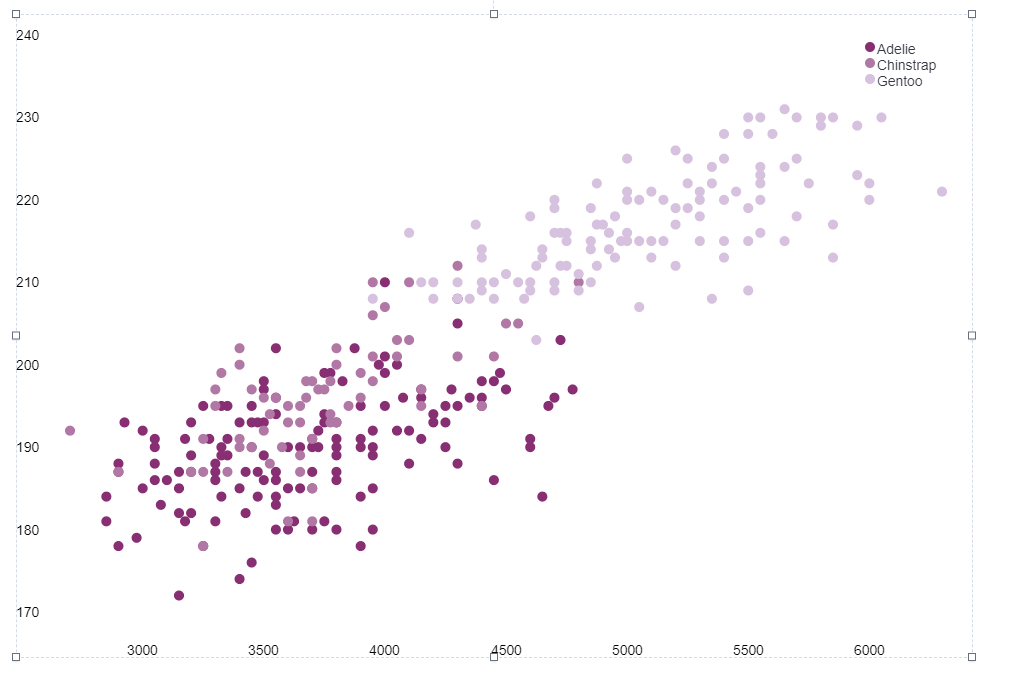
我覺得 Kibana 有多套視覺化的選項,容易造成初學者的試誤成本過高;不過在介面的設計上,的確是很簡潔有力。尤其是在過濾資料時,可以直接使用 "欄位:條件" 進行各種進階篩選。這會有利於在進行資料探索時的開發效率。
好囉~ 這就是第一張的 Kibana 。後續我會再試著再去繪製各種不同的圖形,來體會 ElasticSearch 團隊的設計理念。


 iThome鐵人賽
iThome鐵人賽