機器學習其實沒有想像中的那麼玄,他只是利用一個簡單或複雜的數學模型來模擬實際的情況。簡單來說,當我們看到下面這張左圖時,我們就會想我們該用什麼樣的方式來預測未來趨勢呢?如果說,我們決定用直線來模擬,那這條直線該有什麼限制呢?如果有了限制,我們需要怎麼讓機器學習?
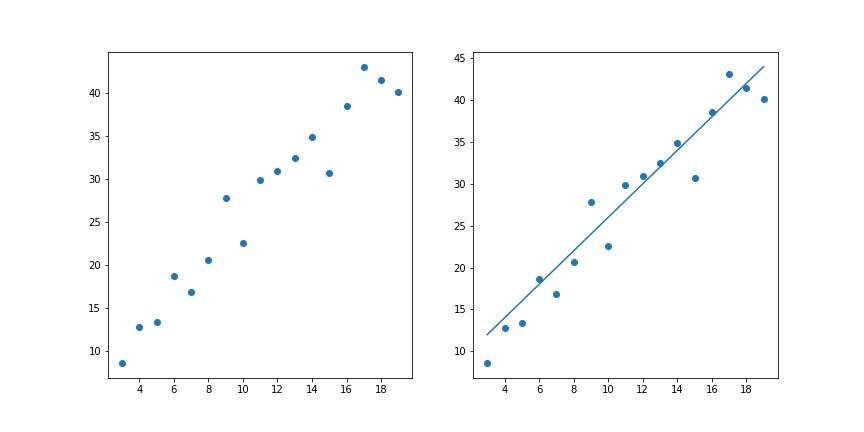
之前我們有提到資料科學家大部分花很多心思在Feature engineering,最主要的是因為機器學習的推力就是資料的品質與多寡。我們回到上面的例子,我們在說要套用什麼模型的時候,完全沒有提到是由機器決定的,因為模型是由工程師經過分析來決定的。而機器學習的便是這個模型的參數!例如Linear Regression是由w和b來決定的:
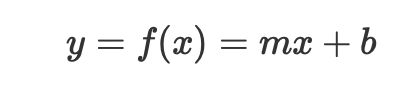
學習完之後,我們便需要一個指摽來告訴我們這個模型該往什麼方向改進,這便是Loss function的任務。既然是function,那就會有輸入跟輸出,輸入便是我現在訓練出來的模型,輸出就是我跟現實的誤差。舉例來說,Linear Regression可以利用平方誤差或是絕對誤差當作Loss function,之後會有更詳細的介紹。
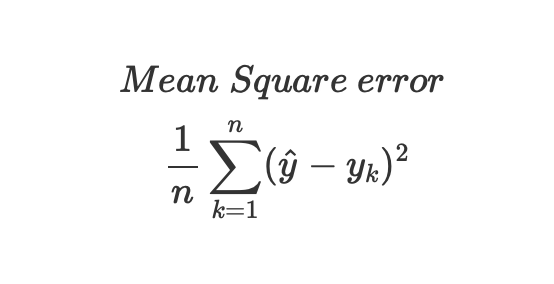
這邊附上我製作的ML的關係圖: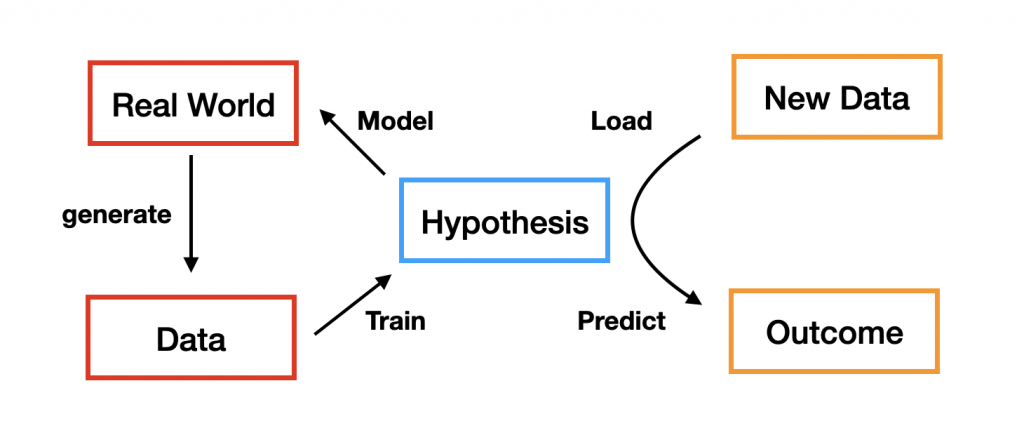
註: Hypothesis是指我們決定的模型,Real World是指真實世界
基本上我們都會用Colab來帶大家跑一次,但如果想在自己電腦做的話需要安裝Package:
$ conda activate <your-environment>
$ conda install -c anaconda scikit-learn
透過這張圖,我們可以了解到他基本可以分成三類Supervised learning, Unsupervised learning和 Reinforcement learning。

Supervised Learning
Supervised 就是指在有結果的條件下訓練。讓機器調整完參數,能馬上知道他的分類是對或錯!
Unsupervised Learning
相較於Supervised,Unsupervised沒有結果,他只能依照各群體的相似度來做分類。
Reinforcement Learning
機器透過跟環境的互動活得反饋,一樣沒有標記,但是會告訴機器做的好或壞(利用分數)。機器的目標就是得到最高分。
之後我們只會提到前兩種,第三種的話也許以後可以補上!明天我們會開始介紹 Supervised Learning 的演算法!
不能在 IT 裡用 LaTex 好難過,但是用內建的圖片又好模糊
因此之後會將文章放在我的網站上,之後會在 IT 上放連結,讓大家可以來舒服的看文章!

