
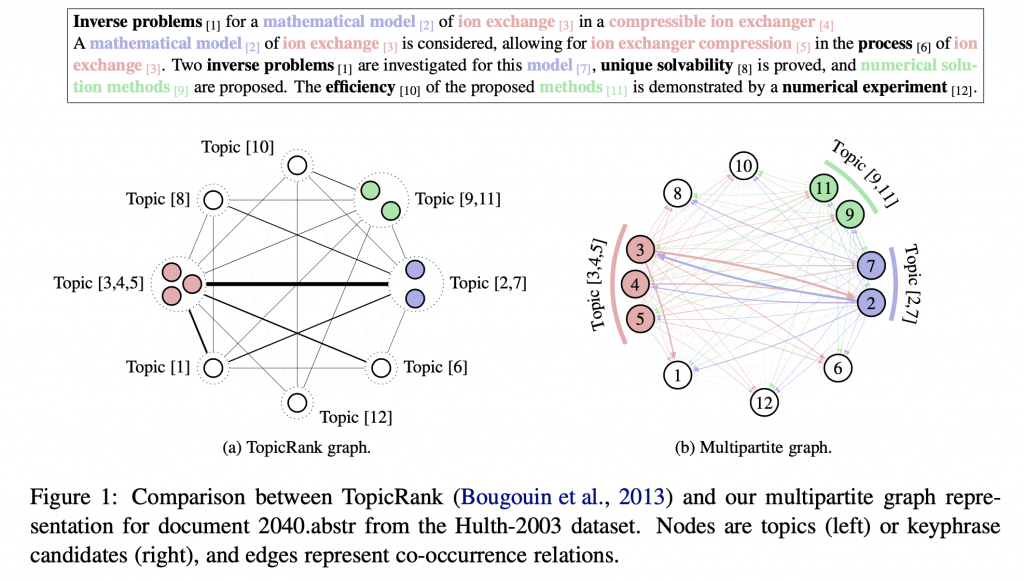
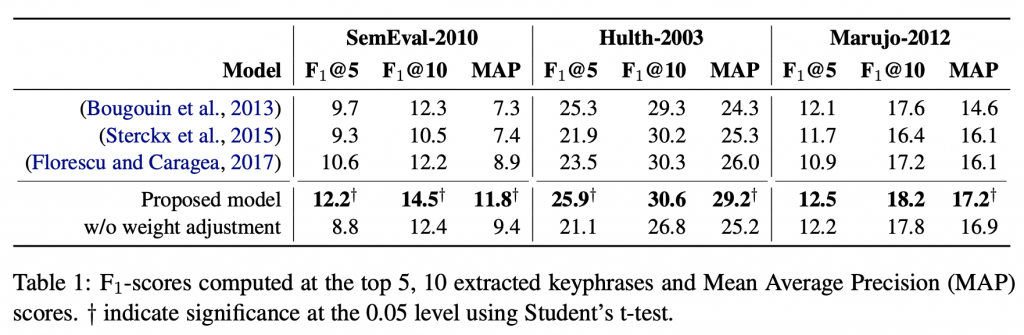
本文延續 TopicRank 的思想,使用 HAC 先將候選詞分群,希望最後的結果能涵蓋到較多主題。詞圖的構成為:以候選詞為節點;除了同主題下的節點,其他所有節點互相連接,構成多分圖;邊的權重則是兩候選詞之位置差倒數之總和。並有額外的提拔機制,提升特定詞的分數。本文模型在三個資料集中都表現優於舊有方法。
NAACL 2018
Unsupervised Keyphrase Extraction with Multipartite Graphs
https://www.aclweb.org/anthology/N18-2105/
ci cj 是兩個候選詞,P(c) 指的是候選詞 c 的位置集合。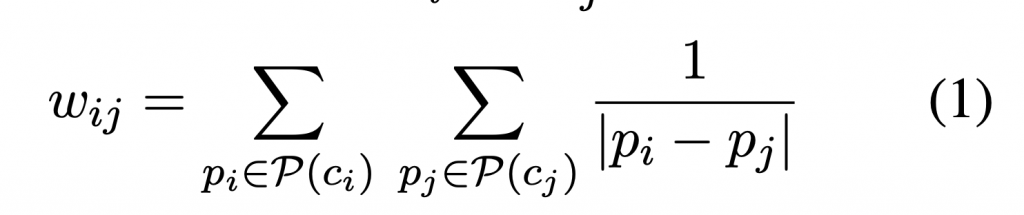
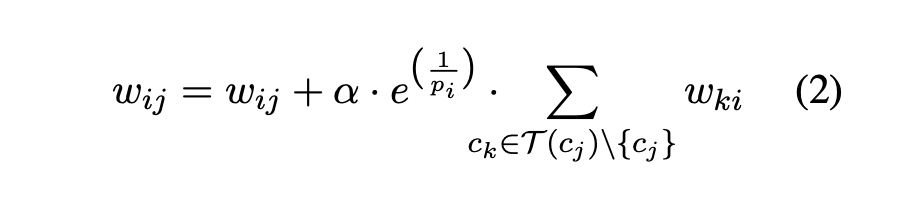
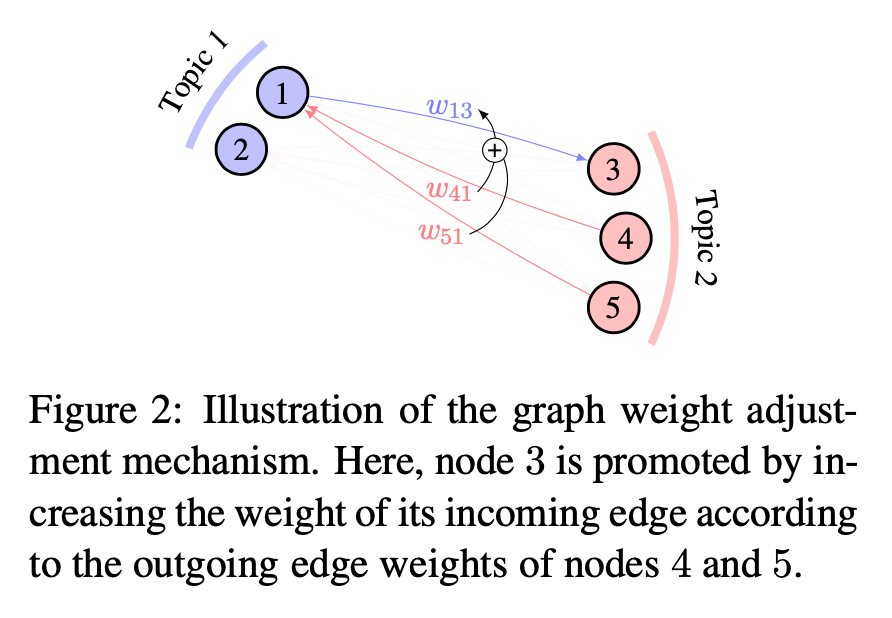

 iThome鐵人賽
iThome鐵人賽