
讓我們在回顧一下昨天提到的什麼是 FP
In functional programming, functions are treated as first-class citizens, meaning that they can be bound to names (including local identifiers), passed as arguments, and returned from other functions, just as any other data type can.
函數也可以當作參數傳遞,函數也可以被當作回傳值,這也是 high order function 的定義
今天就繼續來講,函數也可以被當作回傳值
如下面的例子,最後回傳了一個 lambda 函數
fun returnAsLambda(): () -> Int {
var num = 100
return {
// var num = 100
num++
println("lambda is Closure, result: $num")
num
}
}
returnAsLambda() 回傳的是 lambda 函數,
如果直接呼叫 returnAsLambda()
println(returnAsLambda())
結果會是
() -> kotlin.Int
是的,印出來的竟然只是 lambda 函數的宣告,那到底怎麼呼叫這個函數?
那如果用昨天解說過的 IIFE 呢?立刻執行這個函數!
println(returnAsLambda()())
結果會是如下,成功印出!
lambda is Closure, result: 101
101
如果呼叫兩次呢?
println(returnAsLambda()())
println(returnAsLambda()())
正常的印出 101,101
lambda is Closure, result: 101
101
lambda is Closure, result: 101
101
比較好的做法其實會用一個變數 getFromFunFactory 把這個回傳的 lambda 函數接起來後
此時 returnAsLambda() 就像是一個產生 lambda 函數工廠的模式
在呼叫 getFromFunFactory(),這裡呼叫了兩次
fun main() {
val getFromFunFactory = returnAsLambda()
println(getFromFunFactory())
println(getFromFunFactory())
}
發現結果如下
lambda is Closure, result: 101
101
lambda is Closure, result: 102
102
getFromFunFactory()不是獨立呼叫的嗎?為什麼值保留住繼續累加了呢?
因為 Kotlin 也是一門 Functional Programming 所以也有閉包的概念
相信以前初學 JS 的時候, 都會對於這個名詞感到莫名恐懼XD,尤其是在10年前那資訊還沒那麼發達的年代,大家都亂寫 JS xd
匿名函數或 lambda 的 scope 就是指以下大括弧的範圍,也就是這個 lambda 函數
匿名函數或 lambda 能夠使用在自己 scope 之外的變數,這裡指的也就是 num 這個變數
fun returnAsLambda(): () -> Int {
var num = 100 // lambda 的 scope 外面
return { // lambda 的 scope - start
num++
println("lambda is Closure, result: $num")
num
} // --lambda 的 scope end
}
當 return 這個內部 lambda 函數出來的時候,除了回傳 lambda 函數本身之外,也一併記憶了外面 num 這個執行當下的環境(變數),所以 num 這個變數的值會被獨立的保存在 lambda 函數內
所以當呼叫第一次的後 num 就變成 101,在呼叫第二次時,這時的 num 已經是 101 所以加 1 後變成 102
前面這樣的寫法,其實會變成獨立呼叫了 IIFE,而造成了變數不會被保留
fun returnAsLambda(): () -> Int {
var num = 100
return {
// var num = 100
num++
println("lambda is Closure, result: $num")
num
}
}
println(returnAsLambda()()) // 101
println(returnAsLambda()()) // 101
要改成這樣,在函數回傳的當下就呼叫 IIFE,才會是正確閉包的結果
val iife = (fun(): () -> Int {
var num = 100
return {
// var num = 100
num++
println("lambda is Closure, result: $num")
num
}
})()
iife() // lambda is Closure, result: 101
iife() // lambda is Closure, result: 102
更 lambda expression 的寫法,重點是不用宣告 fun,回傳型態,和 return 關鍵字
// simple way
val iifeSimple = {
var num = 100
{
// var num = 100
num++
println("lambda is Closure, result: $num")
num
}
}()
iifeSimple()
iifeSimple()
函數參照 - 可以把具名函數( fun 開頭且有名稱的函數) 轉成 lambda expression
還記得之前例子的 runLambda() 最後一個參數是一個 lambda expression嗎?
所以 runLambda("Tim", showUserStatusFun) 這樣呼叫是不可行的,因為 showUserStatusFun 是一個具名函數, 要透過 *函數參照 ( :: ),*把具名函數轉成 lambda expression,才能傳入
runLambda("Tim", ::showUserStatusFun)
// 如果今天要呼叫的 function 是個 具名函數, 不是 lambda or 匿名函數
// function ref: 把 具名函數 轉成 lambda expression
// use function ref
fun showUserStatusFun(id: Int, name: String): String {
println("result is userName: $name, his/her id is $id")
return "userName: $name, his/her id is $id"
}
// runLambda("Tim", showUserStatusFun) // 不能這樣用
runLambda("Tim", ::showUserStatusFun)
當參數有 vararg 關鍵字的時候,代表這是一個可變動長度的參數
// 這裏多個 string 傳入 vararg 會變成一個 array, 傳不傳都可以
fun sayHi(greeting: String, vararg lotsGreeting: String) {
println(greeting)
lotsGreeting.forEach { println("lotsGreeting: $it") }
}
因為要求傳入的類型是 String,所以其實可以像這樣直接把字串一個一個傳入,或者根本不傳參數,vararg 會把傳入的參數變成一個 array,所以在程式裡可以用 forEach 去跑 loop 印出值來
// vararg
sayHi("hello")
sayHi("hello", "a", "b", "c")
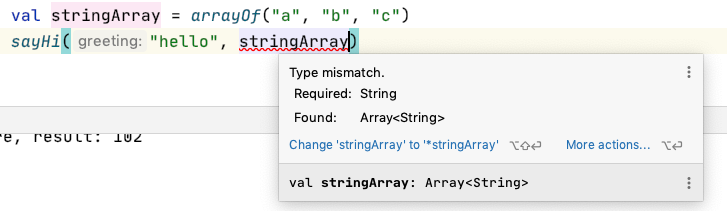
如果要直接傳入一個 array 變數的話,要加上 spread operator 也就是 * 號,就能夠傳入
val stringArray = arrayOf("a", "b", "c")
// 這樣是不可行的~!
// sayHi("hello", stringArray)
// spread operator
sayHi("hello", *stringArray)
在 kotlin 裡面寫 lambda 是一件非常方便的事情,但每次要傳入一個 lambda function 其實都會創造一個物件 instance,久了其實會造成效能問題
fun main() {
runInlineLambda("Tim") { id: Int, name: String ->
println("result is userName: $name, his/her id is $id")
"userName: $name, his/her id is $id"
}
}
fun runInlineLambda(userName: String, showUserStatus: (Int, String) -> String) {
val id = 83666
println(showUserStatus(id, userName))
}
像以上的程式碼,如果打開 byte code 來看的話,會發現有呼叫 runInlineLambda 而且傳入 lambda 的地方創立了一個 instance
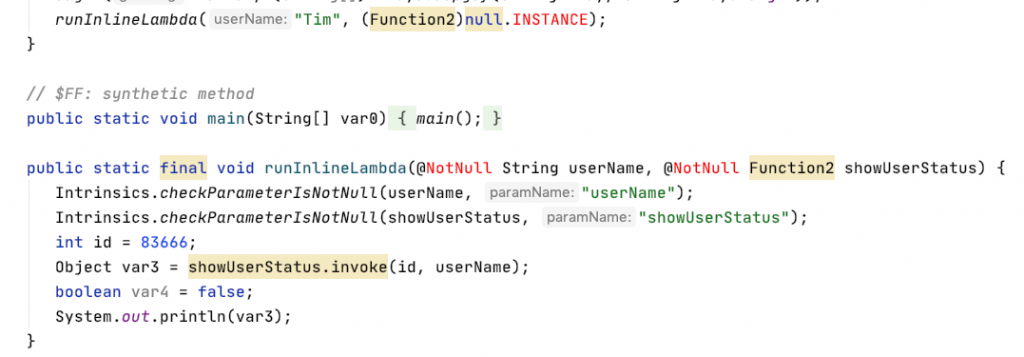
但如果改成 inline function 後
inline fun runInlineLambda(userName: String, showUserStatus: (Int, String) -> String) {
val id = 83666
println(showUserStatus(id, userName))
}
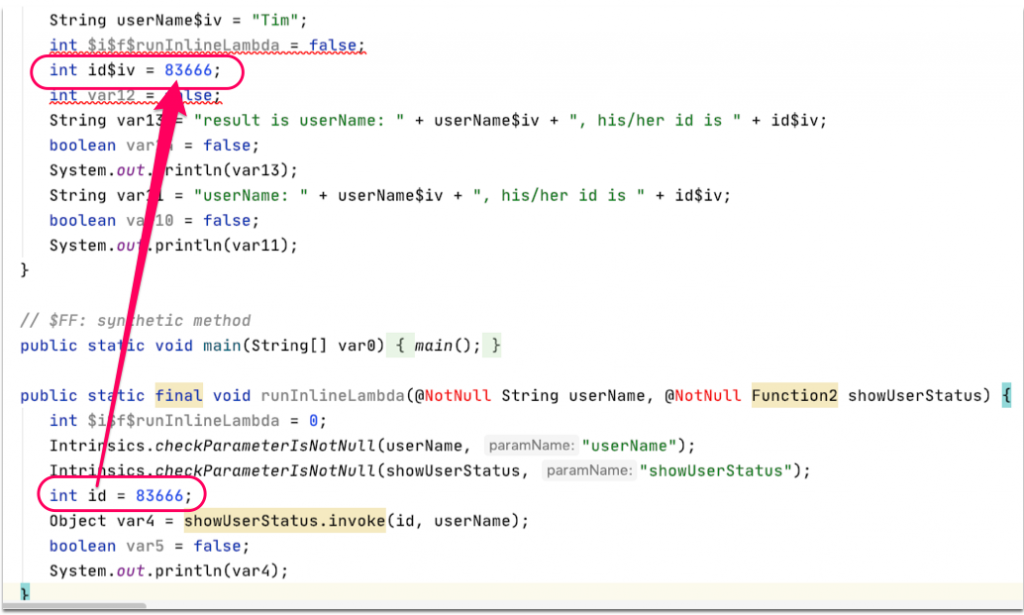
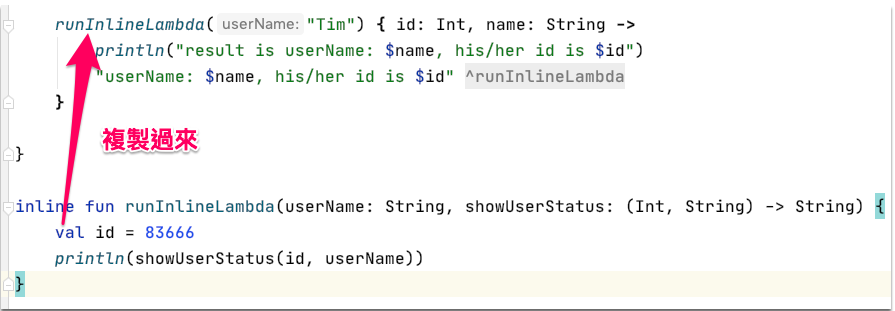
會發現原本 main 裡面呼叫 runInlineLambda 的程式碼消失了,進一步的他把下方 static final void runInlineLambda 內的整段程式碼都複製一份到 main 裡面了!
如此就可以減少 lambda function 造成的新建物件 instance 的問題,減少記憶體的消耗
但要注意的是因為 inlining 會造成大量的程式碼,所以如果是很大的函數,不建議使用 inline 關鍵字。
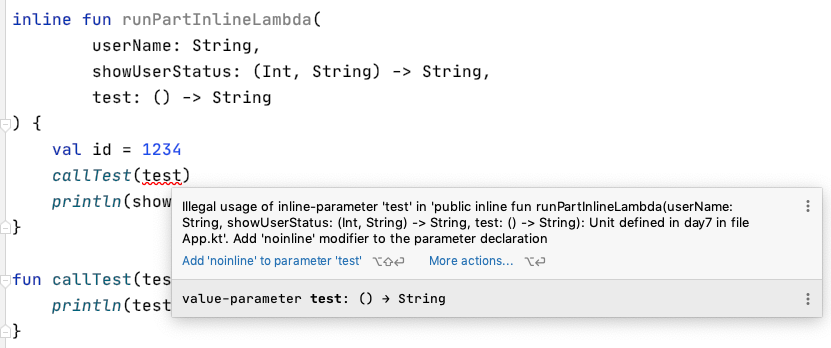
但如果今天 inline function 裡面,有個 test lambda 想要被傳入其他 function 的話
inline fun runPartInlineLambda(
userName: String,
showUserStatus: (Int, String) -> String,
test: () -> String
) {
val id = 1234
callTest(test)
println(showUserStatus(id, userName))
}
fun callTest(test: () -> String) {
println(test())
}
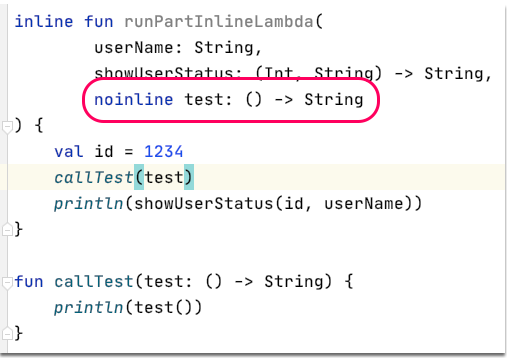
這樣是不會被允許的,從提示可以知道這時候要使用 noinline
如此就可以順利把 test lambda 傳入其他 function!
每次我們呼叫函數的時候,其實 JVM 會使用 call stack 維護一個新的函數的 stack frame,之後在函數返回的時候從 stack frame 在取出恢復原本的狀態。那如果是遞迴函數,就會不斷的創造新的 stack frame,到最後導致 stack overflow。
尾遞迴函數 (Tail recursive functions) 可以把遞迴函數的過程優化成普通的循環函數(iteration),如此可以大大提升執行的效能。
尾遞迴的用法就是在 fun 前面加上 tailrec 這個關鍵字,以有名的 fibonacci 數列來看的話,會像下面這樣寫
fun fibonacci(n: Int): Int {
if (n < 2) return n
return fibonacci(n - 1) + fibonacci(n - 2)
}
然後我們很天真的幫 fun 加上 tailrec 後...
// 這是錯的! return 不能有算式, 只能呼叫函數本身
tailrec fun fibonacci2(n: Int): Int {
if (n < 2) return n
return fibonacci2(n - 1) + fibonacci2(n - 2)
}
再去看 byte code
ㄟ ....怎麼沒有作用

原因是尾遞迴使用有一個很重要的關鍵
在函數最後一句只能呼叫自己本身,不能有任何其他的運算符號
所以 return fibonacci2(n - 1) + fibonacci2(n - 2) 這裏的 + 號會使 tailrec 失效。
正確的寫法如下
這樣寫最後就只有呼叫函數自己本身,並且在參數上面有給予第 0 和第 1 個 fibonacci 預設值
// 改成這樣
tailrec fun fibonacciByTailrec(n: Int, a: Int = 0, b: Int = 1): Int {
if (n == 0) return a
if (n == 1) return b
return fibonacciByTailrec(n - 1, a, a + b)
}
再來看一下 byte code,確實這個遞迴函數變成循環函數了!

其實這樣的寫法,就是 fibonacci 動態規劃的寫法,當然也是 iteration 的方式,但我是在想這樣有類似這樣最後 return 兩個呼叫自己本身的遞迴,要寫成 tailrec 的話,好像也差不多把 iteration 的方式寫出來了 ...倒
上面的寫法也可以改成更 Kotlin 一點
tailrec fun fibonacciByTailrecAndWhen(n: Int, a: Int = 0, b: Int = 1): Int =
when (n) {
0 -> a
1 -> b
else -> fibonacciByTailrecAndWhen(n - 1, a, a + b)
}
這點其實是一開始忘記講的...
這又是另一個 Kotlin 良好的設計,傳入函數的參數都是 read-only 的!也就是 val

這樣能避免大部分的參數被竄改掉。
函數就先介紹到這裡!還有一些比較進階的函數在比較後面會講到!謝謝大家我們明天見!
今日練習的程式在這: 請點我

 iThome鐵人賽
iThome鐵人賽