當你想要取某些列時,只需要像我下方的程式碼那樣在 data 後方加上你想要取得的那列的指標名稱就可以了。
import pandas as pd
csv = "titanic.csv"
data = pd.read_csv(csv)
Ne = data["Name"]
prine(Ne)

當你想要取不只一列時,你可以先將你想要取的那幾列用成一個 list 的結構,在將它
丟給 data,看下方範例。
import pandas as pd
csv = "titanic.csv"
data = pd.read_csv(csv)
alist = ["Name","Age","Sex"]
print(data[alist])

接下來我們實做看看如何將資料進行篩選。
假設我們想要把年齡介於20~30歲的人過濾出來。
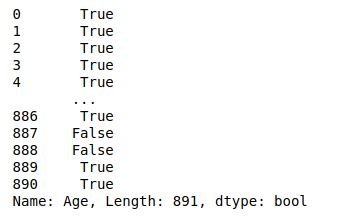
第一步先把大於20歲的人找出來
import pandas as pd
csv = "titanic.csv"
data = pd.read_csv(csv)
ag1 = data["Age"]>=20
ag1
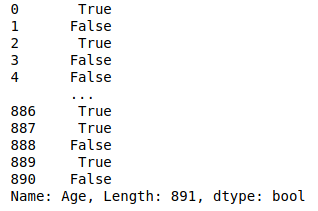
再來把小於30歲的人找出來
import pandas as pd
csv = "titanic.csv"
data = pd.read_csv(csv)
ag1 = data["Age"]>=20
ag2 = data["Age"]<=30
ag2
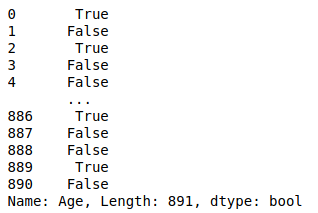
然後將兩個結果(ag1,ag2)用and去判斷,就可以得出了大於20歲又小於30歲的人
import pandas as pd
csv = "titanic.csv"
data = pd.read_csv(csv)
ag1 = data["Age"]>=20
ag2 = data["Age"]<=30
agg = ag1 & ag2
agg
最後我們將得出來的結果套用進我們的 data 數據裡,如果是 True 的就留下, False 就濾掉,最後的結果如下圖,把上下兩張圖拿來對對看,第一筆資料是 True 所以它被留下,第二筆資料是 False 所以它被過濾掉,再來我們可以看左下角這筆數據從原來的 891 筆資料變成了 245 筆資料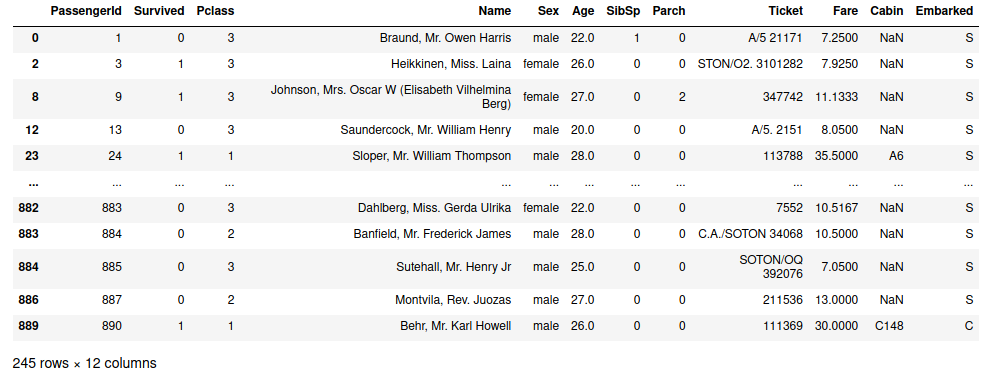
還有一個簡單的方法可以達到跟上面一樣的效果,可以自己試試看,下面這行主要是用 between 這個函數來找出介於20~30歲的人,一樣把 True 或 False 丟給 data 去進行處理。
data[data["Age"].between(20,30)]
好了,今天就介紹到這,明天繼續。


 iThome鐵人賽
iThome鐵人賽