API Server創建Pod的過程會透過kube-scheduler從cluster中選擇一個最佳節點來運作, 通常是由default-scheduler來執行。在調度過程中scheduler不會修改Pod, 而是從中讀取數據,再根據配置選出最適合的節點, 然後通過API調用把Pod綁定到節點上, scheduler的核心目標是基於資源可用性將Pod公平的分佈於cluster節點上, 調度過程會分為三個階段預選(Predicate), 優選(Priority), 選定(Select)。
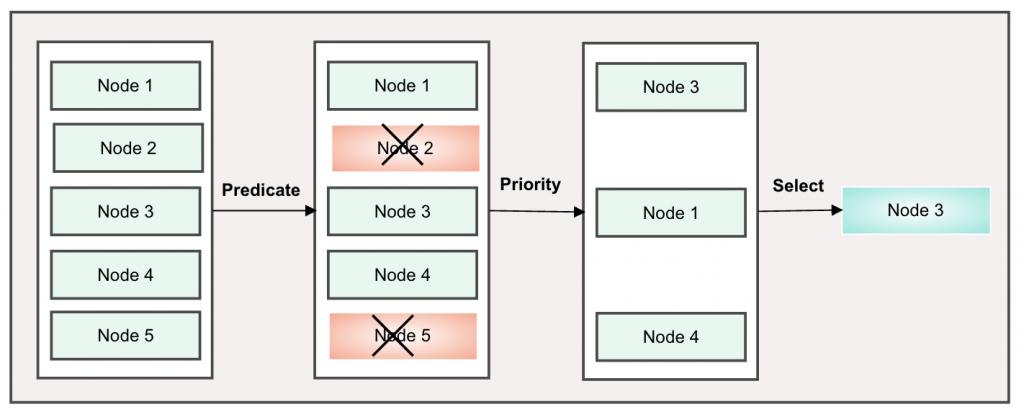
預選(Predicate)
基於一系列的規則對每個節點進行檢查, 採用一票否決的方式先把不適合的節點過濾掉, 如果過濾後沒有留下適合的節點, 則Pod會先pending住, 直到適合的節點出現。
- 常用預選策略
- CheckNodeConditon: 回報Disk, Network錯誤或未準備好的情況是否可以調度
- HostName: 節點屬性是否符合 Pod spec.hostname 屬性
- PodFitsPorts: 節點讓符合 Pod spec.hostPort的屬性是否被佔用
- MatchNodeSelector: 節點標籤是否匹配Pod spec.nodeSelector
- NoDiskConflict: 是否支援Pod配置的volume
- PodFitsResources: 資源是否符合Pod需求
- PodToleratesNodeTaints: 污點是否在Pod spec.tolerations 可允許範圍
- PodToleratesNodeNoExecuteTaints: 污點是否在Pod spec.tolerations 可允許範圍
- CheckNodeLabelPresence: 檢查Node上所有標籤的存在是否合法
- CheckServiceAffinity: 根據目前Pod關聯的Service既存的關聯節點進行調度
- MaxEBSVolumeCount: 掛載的EBS Volume是否已達上限
- MaxGCEPDVolumeCount: 掛載的GCE PD Volume是否已達上限, 預設16
- MaxAzureDiskVolumeCount: 掛載的Azure disk Volume是否已達上限, 預設16
- CheckVolumeBinding: 節點上volume關聯是否符合Pod需求
- NoVolumeZoneConflict: 檢查Pod部署之後是否存在Volume衝突
- CheckNodeMemoryPressure: 節點反應資源壓力升高時,是否還部署Pod
- CheckNodePIDPressure: 節點反應資源壓力升高時,是否還部署Pod
- CheckNodeDiskPressure: 節點反應資源壓力升高時,是否還部署Pod
- MatchInterPodAffinity: 節點是否滿足Pod親和性/反親和性條件
- MaxCSIVolumeCount: 掛載的CSI Volume是否已達上限
- CheckNodeUnschedulable: 如果節點有設置 spec.Unschedulable, Pod是否能容忍
優選(Priority)
從預選後的節點進行優先序排序, 再挑出最適合運行的節點
- 常用優選策略
- LeastRequestedPriority: 以節點上的空閑資源和總資源計算後的比值做評估
- BalancedREsourceAllocation: CPU和Memory佔用比例做計算
- NodePreferAvoidPodsPriority: 已註解訊息分配權重計算
- NodeAffinityPriority: 節點親和性偏好評估
- TaintTolerrationPriority: 污點容忍度評估
- SelectorSpreadPriority: 以標籤選擇器匹配到的數量做評估
- InterPodAffinityPriority: 以Pod親和性匹配結果做評估
- MostRequestedPriority: 以節點上的空閑資源和總資源計算後的比值做評估
- NodeLabelPriority: 以節點是否有特定標籤做評估
- ImageLocalityPriority: 依照節點上的Pod image做評估
- ResourceLimitsPriority: 根據節點是否能滿足Pod所需資源做評估
選定(Select)
從優選的排序中挑出最優先的節點
節點親和調度
節點親和性是scheduler用來確認Pod調度位置的一組規則, 他用node上的自訂標籤和pod上的標籤選擇器來定義規則。分為兩個類型:硬親和性(required)和軟親和性(preferred), 硬親和性是強制規定節點需要滿足Pod的規則, 否則Pod會一直保持在Pending的狀態, 軟親和性在Pod無法找到完全符合的節點時可以退而求其次選擇一個不匹配規則的節點。當節點標籤發生改變不再符合Pod親和性時, Pod不會被刪除, 異動只對新的Pod有效。
Pod 親和調度
Pod與Pod之間因為業務需求而需要將其組織在同一節點或架構等位置時, 可以將這些Pod之間的關聯稱為親和性; 若是出於安全理由等原因需要將Pod相互隔開則稱為反親和性。
如果通過節點親和性來定義Pod的親和性或反親和性,用戶需要非常明確指定Pod可運行的節點標籤, 這並非最佳的做法, 實務上scheduler可以把第一個Pod放在任何位置, 之後要加入的Pod就以第一個Pod為基準來依照親和性與反親和性分配節點。Pod親和性也分為硬親和性(required)和軟親和性(preferred), 意義上和節點親和性相同。
污點和容忍度
污點(taints)是定義在節點之上的key-value屬性, 用來讓節點拒絕Pod的部署, 主要是針對未標記接納節點污點容忍度的Pod;
容忍度(tolerations)是定義在Pod上面的key-valus屬性, 用來配置可以容忍的節點污點;而scheduler只能把pod調度到Pod容忍度可以接受的節點上。
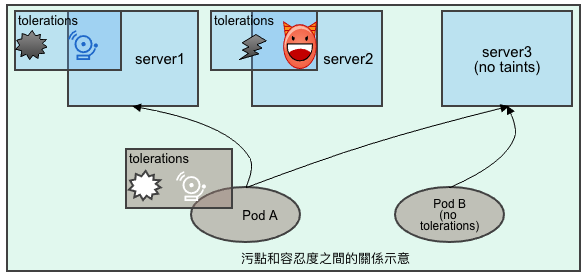
節點親和性可以讓Pod被吸引到同一類的節點, 而污點則是讓節點可以排除特定的Pod。
今日小結
今天就看一下資源調度, 親和度以及污點和容忍度的概念, k8s除了基本的部署之外, 對於個物件之間的關聯也支援了很多種設定, 可以讓用戶依照特定的需求來選用。

