為什麼選爬蟲作為主題?
為什麼選爬蟲作為主題?在決定以爬蟲作為主題時有朋友勸我不要寫這類有爭議的主題,但因為以下幾點我還是選了這個主題:
學習爬蟲對我有什麼好處?未來職涯上有更多的選擇
訓練你對網頁架構的認知
反爬蟲的網頁了了解網路世界在資料這塊的邏輯
說出你的需求並與工程師溝通順暢
分析資料能力的人才最有機會做出能說服公司的策略 今日目標
今日目標openCrawlerWeb
checkDriver
checkDriver 整合進 openCrawlerWeb
在Day5有提到尋找工具的方法,現在我們依序來說明:
能用的套件記錄下來
實際測試確認是否符合專案需求,以下是我當時找到的資源並附上實測後的分析:
所見即所得,看得到的資訊都能夠抓下來,學習起來非常容易且直覺,所以這是本專案最後選擇的工具
openCrawlerWeb我的文章會會依據需求使用到它的各種功能,如果有迫不及待的小夥伴也可以先去官網來更深刻的了解他
selenium-webdriver前置環境安裝
yarn add selenium-webdriver
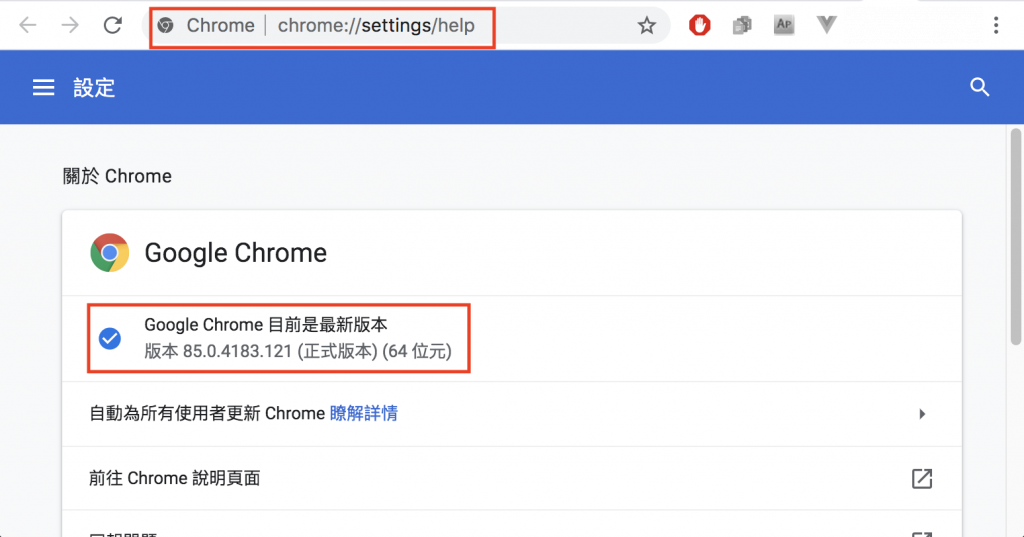
chrome://settings/help貼到你的網址列
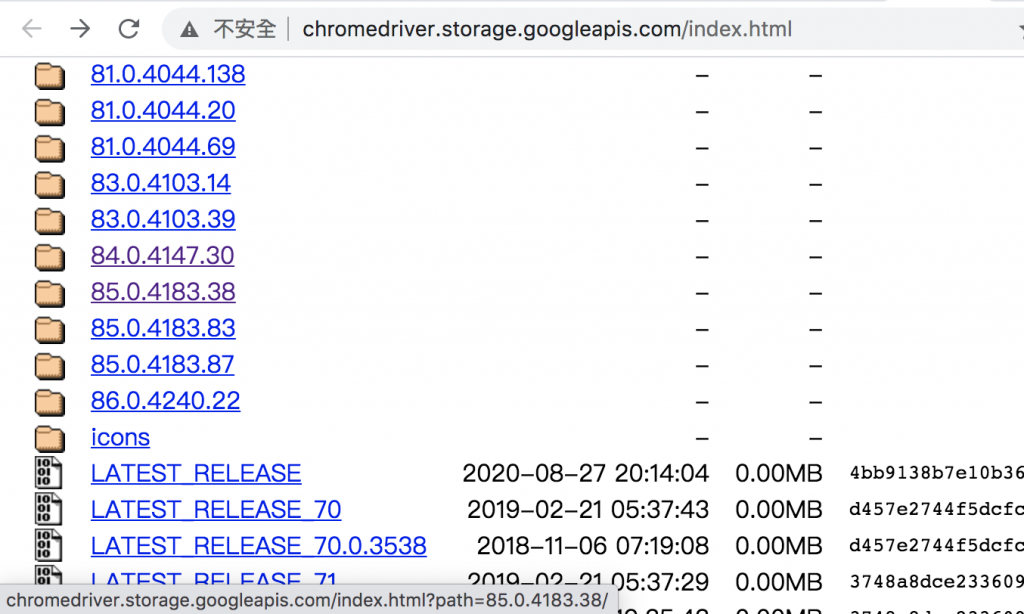
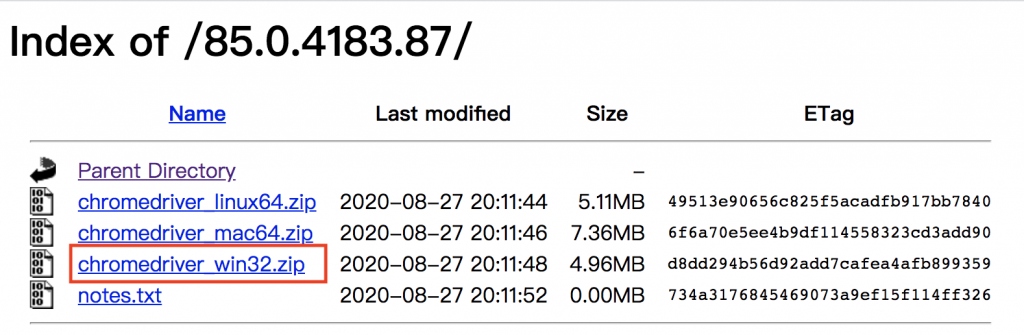
與你 chrome 版本相同的chrome driver
chromedriver.exe 放到專案根目錄下
用openCrawlerWeb函式打開爬蟲用網頁
PS. 因為 javascript 支援非同步語法,所以我們必須很明確地告訴程式他要執行的順序(在 async 的函式中用 await,是標明必須等待這項工作完成才能進入下一步),否則他跑起來的順序跟你想的不一樣 (並非完成前面工作才執行下一步的順序),想更深入理解的朋友可以參考這篇文章喔
require('dotenv').config(); //載入.env環境檔
const webdriver = require('selenium-webdriver') // 加入虛擬網頁套件
async function openCrawlerWeb() {
// 建立這個browser的類型
let driver = await new webdriver.Builder().forBrowser("chrome").build();
const web = 'https://www.google.com/';//填寫你想要前往的網站
driver.get(web)//透國這個driver打開網頁
}
openCrawlerWeb()//打開爬蟲網頁
執行程式
在專案資料夾的終端機(Terminal)執行指令
yarn start
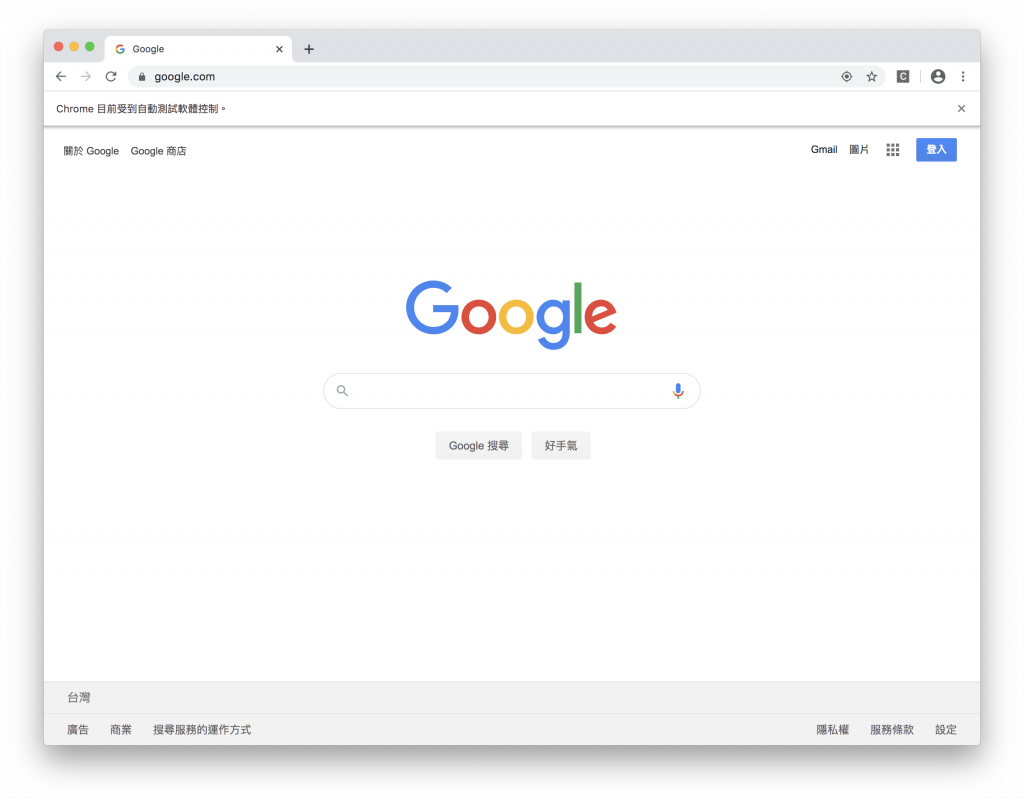
如果執行順利,你會看到 chrome 應用程式自動打開並且進入 google 的首頁

因為有人回報部分 windows 就算把 chromedriver.exe 放在專案根目錄也讀不到,所以特別寫了一個 checkDriver 的函式,邏輯如下:
chromedriver.exe 的檔案
const chrome = require('selenium-webdriver/chrome');
const path = require('path');//用於處理文件路徑的小工具
const fs = require("fs");//讀取檔案用
function checkDriver() {
try {
chrome.getDefaultService()//確認是否有預設
} catch {
console.warn('找不到預設driver!');
//'../chromedriver.exe'記得調整成自己的路徑
const file_path = '../chromedriver.exe'
//請確認印出來日誌中的位置是否與你路徑相同
console.log(path.join(__dirname, file_path));
//確認路徑下chromedriver.exe是否存在
if (fs.existsSync(path.join(__dirname, file_path))) {
//設定driver路徑
const service = new chrome.ServiceBuilder(path.join(__dirname, file_path)).build();
chrome.setDefaultService(service);
console.log('設定driver路徑');
} else {
console.error('無法設定driver路徑');
return false
}
}
return true
}
將 chromedriver.exe 放到根目錄後記得在 .gitignore 把它加進去忽略清單喔,他屬於不需要版控的檔案
node_modules
.env
chromedriver.exe
checkDriver整合到openCrawlerWeb在建立瀏覽器之前,我們先用 checkDriver 函式來確認 Driver 是否是設定,如果無法設定會跳出錯誤提醒,統整後程式如下
require('dotenv').config(); //載入.env環境檔
const webdriver = require('selenium-webdriver') // 加入虛擬網頁套件
const chrome = require('selenium-webdriver/chrome');
const path = require('path');//用於處理文件路徑的小工具
const fs = require("fs");//讀取檔案用
function checkDriver() {
try {
chrome.getDefaultService()//確認是否有預設
} catch {
console.warn('找不到預設driver!');
//'../chromedriver.exe'記得調整成自己的路徑
const file_path = '../chromedriver.exe'
//請確認印出來日誌中的位置是否與你路徑相同
console.log(path.join(__dirname, file_path));
//確認路徑下chromedriver.exe是否存在
if (fs.existsSync(path.join(__dirname, file_path))) {
//設定driver路徑
const service = new chrome.ServiceBuilder(path.join(__dirname, file_path)).build();
chrome.setDefaultService(service);
console.log('設定driver路徑');
} else {
console.error('無法設定driver路徑');
return false
}
}
return true
}
async function openCrawlerWeb() {
if (!checkDriver()) {// 檢查Driver是否是設定,如果無法設定就結束程式
return
}
// 建立這個broswer的類型
let driver = await new webdriver.Builder().forBrowser("chrome").build();
const web = 'https://www.google.com/';//填寫你想要前往的網站
driver.get(web)//透國這個driver打開網頁
}
openCrawlerWeb()//打開爬蟲網頁
 參考資源
參考資源免責聲明:文章技術僅抓取公開數據作爲研究,任何組織和個人不得以此技術盜取他人智慧財產、造成網站損害,否則一切后果由該組織或個人承擔。作者不承擔任何法律及連帶責任!
我在 Medium 平台 也分享了許多技術文章
❝ 主題涵蓋「MIS & DEVOPS、資料庫、前端、後端、MICROSFT 365、GOOGLE 雲端應用、個人研究」希望可以幫助遇到相同問題、想自我成長的人。❞
在許多人的幫助下,本系列文章已出版成書,並添加了新的篇章與細節補充:
- 加入更多實務經驗,用完整的開發流程讓讀者了解專案每個階段要注意的事項
- 將爬蟲的步驟與技巧做更詳細的說明,讓讀者可以輕鬆入門
- 調整專案架構
- 優化爬蟲程式,以更廣的視角來擷取網頁資訊
- 增加資料驗證、錯誤通知等功能,讓爬蟲執行遇到問題時可以第一時間通知使用者
- 排程部分改用 node-schedule & pm2 的組合,讓讀者可以輕鬆管理專案程序並獲得更精確的 log 資訊
有興趣的朋友可以到天瓏書局選購,感謝大家的支持。
購書連結:https://www.tenlong.com.tw/products/9789864348008
用 node.js 開發爬蟲有 google 開發的 puppeteer.js 可以使用 
感謝分享,解決問題方法百百種,選擇自己熟悉的就沒問題~
馬上加入補充說明XD
請問作者如果沒有與chrome版本相同版本的chrome driver,是不是會導致程式執行錯誤?
印象中如果版本不同會報錯誤喔
感謝回覆,因為chrome drive沒有提供最新的與chrome的版本,那請問是不是就不能爬蟲嗎?