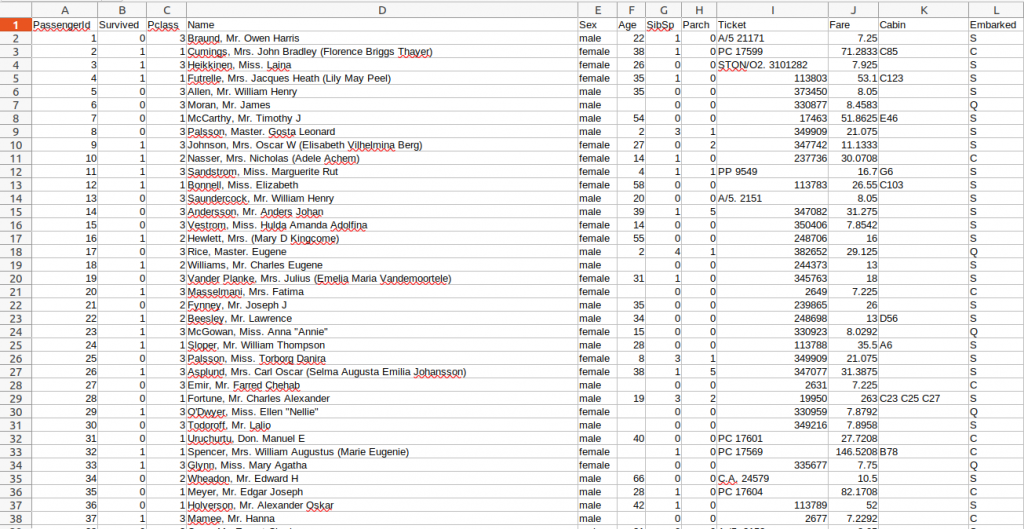
這是我們之前載下來的csv檔,假設我們今天想要去算算看各個不同等級的房間獲救的比率,那我們就會需要用到兩個指標,分別是 survived 和 Pclass ,這兩個指標分別是用來紀錄乘客是否獲救和他們房間的等級。
為了進行上述的計算,我們可以用下面這個函數。
pivot_table() 就像是Excel中的數據透視表,他在 pandas 中是個好用的函數,這次只會簡單帶過,有興趣的可以去網路上了解下。
import pandas as pd
import numpy as np
csv = "titanic.csv"
data = pd.read_csv(csv)
sur = data.pivot_table(index="Pclass",values="Survived",aggfunc=np.mean)
sur
在 pivot_table() 函數裡我們將 Pclass(房間等級) 設為 索引(index) ,因為我們想要知道各個等級的獲救率,再來我們把 Survived 設為 數值(values) 因為要被我們拿來做計算,最後將numpy裡的 mean(平均值) 設為 aggfunc ,代表我們在建表時需要進行平均值的處理。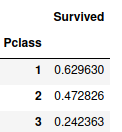
這樣結果就出來了。
我們也可將年齡也納入計算
import pandas as pd
import numpy as np
csv = "titanic.csv"
data = pd.read_csv(csv)
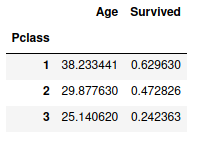
sur = data.pivot_table(index="Pclass",values=["Survived","Age"],aggfunc=np.mean)
sur


 iThome鐵人賽
iThome鐵人賽