前幾篇的教學教大家建立了一個自己的index,有了index怎麼可以沒有doc(文檔)呢,今天就來教大家把資料匯入ES
有兩個方法可以往es裡丟資料:create、index
這兩者的差異是create需要指定id而index如果沒有指定id則會自動生成,其餘用法其實差不多,這邊用index來做示範
假設我有以下的csv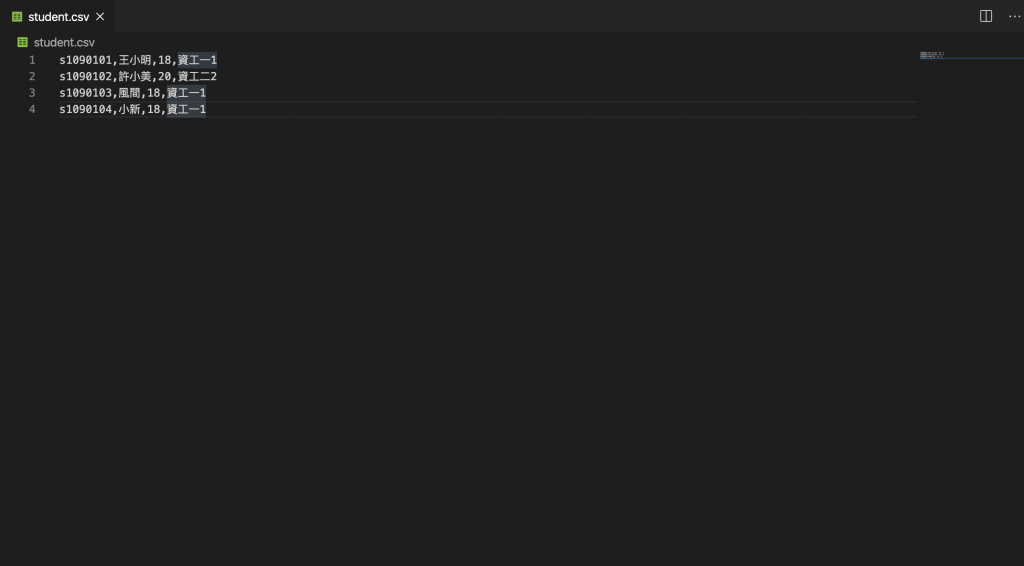
1.利用python將資料源整理成mappings的格式,例如以下:
{
'sid': 's1090101',
'name': '王小明',
'age': 18,
'class': '資工一1'
}
過程就不多做贅述
2.使用index這個方法把剛剛整理好的資料源丟進去
es.index(index='school_members', body=剛剛整理好的資料源)
完整程式碼在下面:
from elasticsearch import Elasticsearch
def load_datas():
datas = list()
with open('student.csv', 'r') as f:
for data in f.readlines():
sid, name, age, class_ = data.replace('\n', '').split(',')
datas.append(
{
"sid": sid,
"name": name,
"age": int(age),
"class": class_
}
)
return datas
def create_data(es, datas):
for data in datas:
es.index(index='school', body=data)
if __name__ == "__main__":
es = Elasticsearch(hosts='192.168.1.59', port=9200)
datas = load_datas()
create_data(es, datas)
需要給id
es.index(index='school_members', body=剛剛整理好的資料源, id=1)
刪除資料
es.delete(index='school_members', id=想要刪除的文檔id)
更新資料
定義body:
{
"doc": {
"age": 20 #想更新的欄位:更新的值
}
}
執行
es.update(index='school_members', id=想要更新的文檔id)
今天的教學就到這裡,下篇來教大家可以批量對文檔操作的方法:bulk


 iThome鐵人賽
iThome鐵人賽