在網路購物商城中,適當的詞庫,可以做為蒐尋的利器。
舉個例子來說,如果消費者輸入了 "PS", 然後網站就接著提示 "PS4" 或是 "PS5 預購",是不是能對於轉化率有所促進呢? 應該很少人會真的特別輸入"Play Station"吧?
同樣地,為了做為練習這次使用的方法很簡單,就是透過維基百科中收錄好的三國演義人名,做為自訂詞庫。什麼?竟然將三國英傑,當成產品沿街叫賣嗎?咦,不是有家日本遊戲公司叫做"光榮"的,已經這樣做了將近快要30-40年啦... 這年頭大家想起的趙雲,幾乎都是三國無雙的招牌人物形象啦。
今天就透過簡單的 R 爬蟲去取得詞庫所需要的人名資料:
觀察一下維基百科的頁面元素,在頁面上有100個表格,我們要做的就是將這100個表格的文字元素抽取出來。因為有100個表格,所以記得要用 html_nodes 有複數s字尾,而不是 html_node 。後者只能抽取第一個表格。

後續再將這100個表格,合併成1個大表格。透過 data.table 的rbindlist函數可以很高效的完成這件事。
最後由於只需要最左邊的"姓名"資料,在data.frame中抽取"姓名"後,直接放到向量變數 all_names 中。
require(httr)
require(rvest)
require(dplyr)
require(data.table)
# 三國演義角色列表 URL https://zh.wikipedia.org/zh-tw/%E4%B8%89%E5%9B%BD%E6%BC%94%E4%B9%89%E8%A7%92%E8%89%B2%E5%88%97%E8%A1%A8
res <- httr::GET(url = 'https://zh.wikipedia.org/zh-tw/%E4%B8%89%E5%9B%BD%E6%BC%94%E4%B9%89%E8%A7%92%E8%89%B2%E5%88%97%E8%A1%A8' )
name_tables_list <- content ( res , type ="text" , encoding = "UTF-8" ) %>% read_html()
%>% html_nodes( '#mw-content-text > div.mw-parser-output > table' )
name_tables_list <- html_table(name_tables_list , fill = TRUE )
name_table <- data.table::rbindlist(name_tables_list )
all_names <- name_table$姓名
你以為這樣就結束了嗎? 有一種東西叫"Data Clean"。資料,只要不是從結構式資料庫中取得,很多時候都需要花時間進行清洗。事情沒有這麼簡單,讓我們透過 length 函數檢查一下姓名的字數,會發現有些字數誇張的長。你認為會有人的名字高達近20字的嗎?
檢視後,發現有這2種狀況:
1.左側小括號"("後,有文字補充說明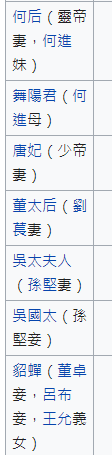
2.逗號","後,有文字補充說明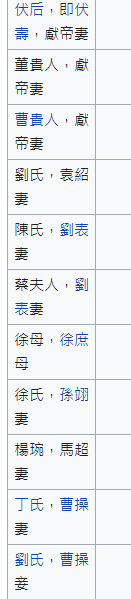
all_names <- gsub( "\\(.*" , "" , x = all_names)
all_names <- gsub( ",.*" , "" , x = all_names)
其中比較要注意的是 小括號在正規表達式中,由於有群組的作用。所以需要進行轉義,而 R 的轉義語法稍微麻煩一點,要透過2個"\"才能進行轉義。並且為了簡化起見,我將左側小括號與逗號後的文字,全數進行刪除。
原本也想要將表格中的"字"也納入詞庫中,但其中有一些內容為 "魏國明將典韋之子"、 "前期為張飛副將" ... 這如果完整進行資料清洗,我想可能今天的鐵人賽文章就發不出來了.... 所以請容我先偷懶一下吧。
總之,到了這個階段,all_names 中的內容,就是最簡單的人名列表囉:
[971] "尚廣" "昌豨" "昌奇" "法真" "法正" "沮授" "沮鵠" "段珪" "段煨" "爰青"
[981] "爰邵" "韋康" "韋晃" "夏惲" "夏恂" "耿武" "耿紀" "郝萌" "郝昭" "眭
希望明天可以搞定在 Elastic Cloud 的自訂詞庫設定!


 iThome鐵人賽
iThome鐵人賽