5-2. 設定完成後,就可以開始查詢 order.csv 裡的資料,Athena 是使用標準 SQL 進行查詢,所以如果會使用SQL操作資料庫,再來是用 Athena 進行查詢分析幾乎是沒有門檻的,以這個訂單資料來說,可以使用 Athena 找出星期幾的訂單數量是比較多的SELECT order_dow, count(*) count FROM "it_db"."order" group by order_dow order by order_dow
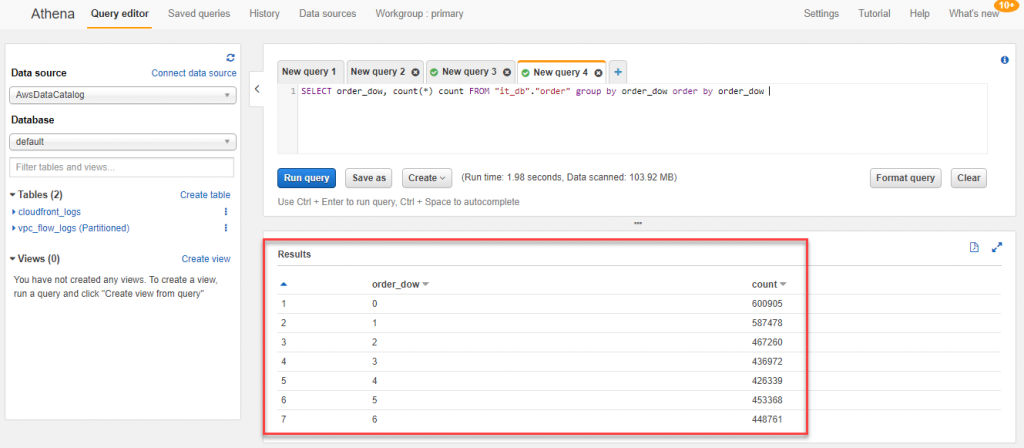
可以看出是星期日與星期一的訂單數量是最多的,透過 Athena 可以很快的察看任何維度,例如每個消費者的訂單數量、回購頻率的分布、等等,之後可以在匯入其他CSV資料,可以看到每個商品的購買數量,每個客戶喜歡的商品類型、等等
左邊的 Data source 的部分,當中的 Database 與 Table 和 Glue Data Catalog 的 Database 與 Table 是相通的,所以 Crawler 創建的 Table 都會顯示在 Athena 的 Data source 中,透過這個方式 Athena 可以不需要了解 Table 後面的資料實際所儲存的地方,統一透過 Crawler 產生的 Table,Athena 可以直接對這些資料源進行查詢甚至是 join,在不同的資料源之間進行查詢
例如資料源是 S3、MySQL、MongoDB,透過 Glue Data Catalog 的 Crawler 可以將這三個資料源轉換成三個 Database 與 Table,Athena 就可以很輕易的將這些資料進行 Join 與分析


 iThome鐵人賽
iThome鐵人賽