4-6. IAM 的部分選擇我們在步驟 1-1 時創建的 IAM Role(ITGlue)
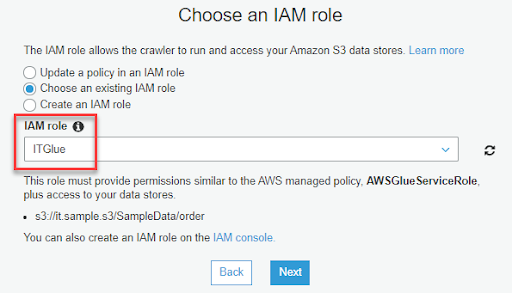
4-7. Schedul 可以設定 Crawler 是否要定期執行,通常這個會用在需要將新的 Partition 更新到 Table 中時所使用,Partition 之後會有比較詳細的說明,這邊我們先選擇 Run on demand
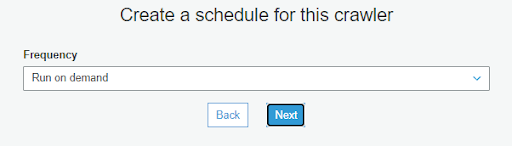
4-8. 點選 Add database 創建一個自己的 DB 這樣資料比較不會混亂,Prefix added to table 的內容會添加到之後創建出來的 Table Name 前面,Table Name 則會是 S3 的資料夾名稱,Prefix added to table 在這邊先維持空白就好,最後點選 Next 後再點選最下面的 Finish 就完成了
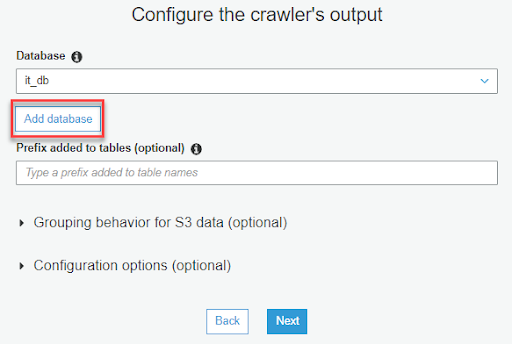
4-9. 回到 Crawlers 的頁面,勾選剛剛創建的 SimpleDataCrawler,再點選 Run crawler,當 Crawler 執行完成時,可以看到 Tables added 的欄位變成 1
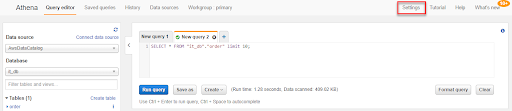
4-10. 回到 Tables 的頁面可以看到 Crawler 所產生的 Table,勾選 order 這個 Table,並點選 Action 中的 View data,接下來要使用 Athena 進行查詢



 iThome鐵人賽
iThome鐵人賽