隨著訓練的輪數增加,模型在訓練集的正確率增加,但是到了一定輪數後,驗證集的正確率或loss反而往下掉了,發生這種情形,先把訓練過程的曲線畫出來,來看看怎麼回事,要記得將訓練過程產生的資訊存起來。
hist = model.fit(
x = x_train,
y = y_train,
batch_size = 32,
epochs = 20,
validation_split = 0.1,
verbose = 2
)
history = hist.history
x = np.arange(20)
plt.figure(facecolor='w')
plt.plot(x, history['loss'], label='loss')
plt.plot(x, history['val_loss'], label='val_loss')
plt.plot(x, history['accuracy'], label='accuracy')
plt.plot(x, history['val_accuracy'], label='val_accuracy')
plt.xlim(0,19)
plt.xticks([i for i in range(0,20,3)],[str(i) for i in range(0,20,3)])
plt.xlabel('epoch')
plt.ylim(0,1)
plt.ylabel('acc-loss')
plt.legend()
plt.show()
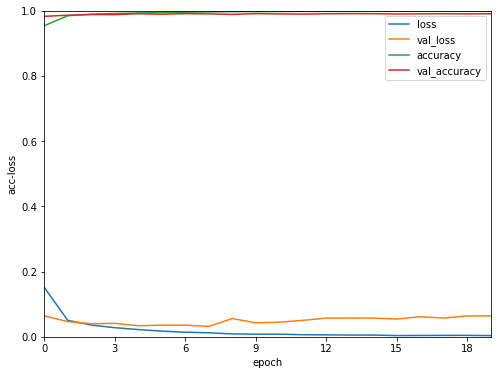
在訓練集上的loss隨著時間下降,但是驗證集的loss卻升高了,這代表了模型對訓練集的擬合度升高,不一定代表在驗證集也是如此,就像熟背練習卷上每道題目的考生,面對大考時,反而發揮的不好。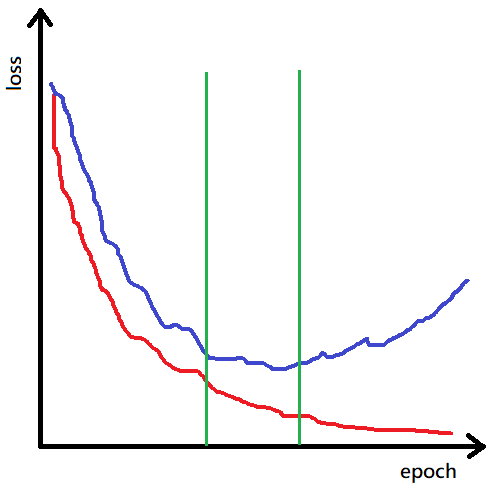
以上的紅線代表模型在訓練集上的擬合度,藍線是在驗證集上的擬合度,在綠線左方,訓練集和驗證集的loss都很高,代表模型,還沒有很好的學習到東西,綠線的右方,訓練集的loss很低,但是驗證集的loss很高,代表模型已經針對訓練集最佳化,失去泛用、普遍性了,我們想要的結果,應該處於兩條綠線之間,這是我們在訓練時使用驗證集的主要原因,幫助我們簡單判別模型的狀態。

