講完圖片訊息處理的方法之後,
想介紹一下關於音訊檔案處理的方法,
這個部分也是滿好玩的,跟圖片處理一樣有很多細節可以操作,
不過既然是聊天機器人,目前這個系列文就簡單介紹關於如何將語音訊息轉成文字的方法囉~
跟接收圖片訊息的方法一樣,實際使用操作辦法如下:
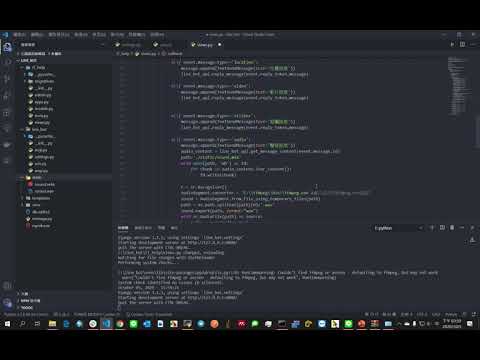
elif event.message.type=='audio':
message.append(TextSendMessage(text='聲音訊息'))
audio_content = line_bot_api.get_message_content(event.message.id)
path='./static/sound.m4a'
with open(path, 'wb') as fd:
for chunk in audio_content.iter_content():
fd.write(chunk)
line_bot_api.reply_message(event.reply_token,message)
這樣一來就能將聲音訊息寫入到實體檔案,
並且存放在指定的路徑資料夾內囉~
實際操作影片:
相信LINE的使用者多半有嘗試過使用語音訊息代替打字訊息的經驗,
一方面是有些事情用打字可能講不清楚,而且有時候用說的確實方便許多,
今天我們就嘗試做一個在收到語音訊息之後,將語音轉為文字內容的應用吧,
首先,我們需要安裝speech_recognition、pydub兩個python套件,
並且還要再安裝ffmpeg進行音訊轉檔,
#在進入虛擬環境之下
$ pip install SpeechRecognition pydub
順利安裝完成後,接著要安裝ffmpeg,
ffmpeg 是一個可以執行音訊和視訊多種格式的錄影、轉檔、串流功能的自由軟體,
我們在這裡需要使用到ffmpeg的轉檔功能,將檔案轉為.wav檔,
ffmpeg在windows下安裝首先要到官網下載,
選擇ffmpeg-N-99458-g069d2b4a50-win64-gpl-shared.zip版本,
下載完畢之後將檔案解壓縮,將資料夾名稱改為ffmpeg並放到C:/底下(或其他自己想放的路徑),
完成安裝後,我們可以將以下程式碼加入到剛剛擷取音訊內容下方,
#views.py
#import speech_recognition及pydub套件
import speech_recognition as sr
from pydub import AudioSegment
...
elif event.message.type=='audio':
message.append(TextSendMessage(text='聲音訊息'))
audio_content = line_bot_api.get_message_content(event.message.id)
path='./static/sound.m4a'
with open(path, 'wb') as fd:
for chunk in audio_content.iter_content():
fd.write(chunk)
#進行語音轉文字處理
r = sr.Recognizer()
AudioSegment.converter = 'C:\\ffmpeg\\bin\\ffmpeg.exe'#輸入自己的ffmpeg.exe路徑
sound = AudioSegment.from_file_using_temporary_files(path)
path = os.path.splitext(path)[0]+'.wav'
sound.export(path, format="wav")
with sr.AudioFile(path) as source:
audio = r.record(source)
text = r.recognize_google(audio,language='zh-Hant')#設定要以什麼文字轉換
#將轉換的文字回傳給用戶
message.append(TextSendMessage(text=text))
line_bot_api.reply_message(event.reply_token,message)
設定完畢之後即可傳送語音訊息進行測試,
如果看到以下畫面就是順利完成啦~
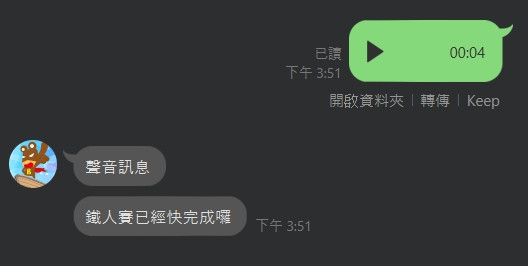
這樣一來就可以將語音轉文字作為觸發其他功能的應用囉,
譬如用說話的方式輸入指令,或者是將語音轉變成文字內容並記錄在資料庫中等等,
只是咬字需要很清楚才行就是了,如果有更好的辦法也歡迎留言交流囉~
實際操作影片: