大家好,接續昨天的房價預測,已經做了大致上的介紹,而今天要做的就是對昨天下載的資料集,「House Sales in King County, USA」的資料進行處理。
首先要匯入要用到的套件:
import numpy as np
import pandas as pd
再來要讀取資料集的資料,使用的是pandas函式庫的read_csv方法,將檔案放到虛擬環境的位置,再執行方法:data=pd.read_csv(“kc_house_data.csv”)
然後可以用以下方法查看讀取的資料:
顯示資料:data.head()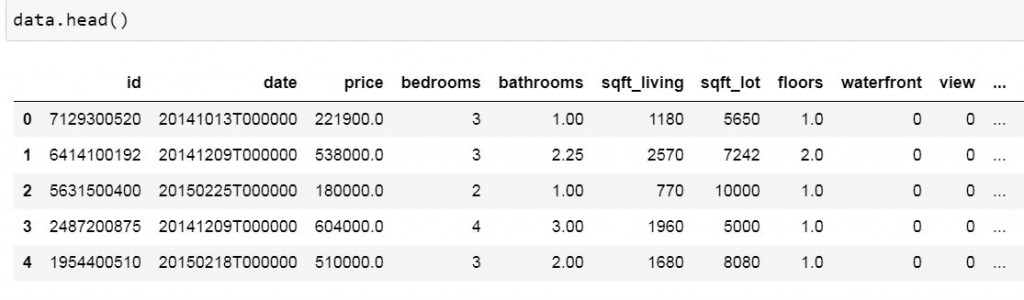
顯示資料型態:data.dtypes
在上面顯示的資料集可以看到,資料date的資料型態非數值,而模型的輸入只接受數值型態,所以要將其轉為數值,並且分成年、月、日三種資料,這裡以‘20141013T000000’這筆資料為例:
data['year']=pd.to_numeric(data['date '].str.slice(0,4))
data['month ']=pd.to_numeric(data['date'].str.slice(4,6))
data['day ']=pd.to_numeric(data['date'].str.slice(6,8))
上面三行分別代表的數值是2014、10、13。
接著要刪除沒有用的資料,要刪除的有id和date,id是無意義的資料,date已經分成年、月、日三種資料。
data.drop(['id'],axis="columns",inplace=True)
data.drop(['date'],axis="columns",inplace=True)

可以從上圖確認id和date已經被刪除。
再來要將資料集分成三個部分,分別是訓練資料、驗證資料、測試資料,資料用亂數分組,各組資料比例為6:2:2。
num=data.shape[0]
indexs=np.random.permutation(num)
train_indexs=indexs[:int(num*0.6)]
val_indexs=indexs[int(num*0.6):int(num*0.8)]
test_indexs=indexs[int(num*0.8)]
今天就先做到這一步,明天會將資料進行標準化,並且建立模型

