要深入探討 GPT-3,必須先了解 Transformer。
2017 年 6 月,Google 以及多倫多大學的研究人員共同提出了一個自然語言處理 (NLP; Natural Language Process) 的新模型架構,稱之為「Transformer」(註一)。這篇論文可以說是近期 NLP 的經典之作,提出後被廣泛的討論及引用。今天 (2020/09/22) 在 Google Scholar 上查了它被引用的次數: 12015,不得不說是驚人呀!
這篇論文的標題為「Attention Is All You Need」,強調只要用 Attention 就夠了。過去解決「編碼器/解碼器 (Encoder/Decoder)」的問題時,主要是使用 RNN、LSTM 這類的模型結構,有時候也有人會使用 CNN。然而這篇論文主張,單單使用 Attention 就夠了,如此,模型的結構會比之前簡單,而模型的效能也更好。
Transformer 的另外一個好處是:模型在訓練及推理時,可以運用大量的平行處理,以節省時間。這個部份在後面會加以的說明。
帶著朝聖的心,讓老頭跟著大家走一遍這篇論文。
RNN (以及它的變形 LSTM, GRU) 處理輸入序列 (sequence) 時,都必須依序列內元素 (element) 的順序,一個接一個的處理,這當然就加長了模型訓練所需的時間。
下圖即是 RNN 處理輸入序列時的簡圖(註二),由圖中可以看出,要計算 X1之前,必須先算 X0,要算 X2 之前,必須先算 X1 ,這種嚴格的前後關係,使得我們沒有辦法利用平行處理的方式來加快速度。Transformer 的架構,有利於平行處理,也就是說,輸入序列內所有的元素,只要運算資源允許,可以同時加入計算,節省所需時間。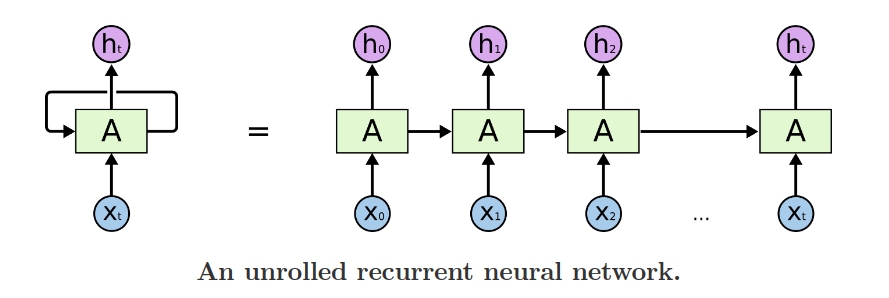
除了無法平行處理這個問題之外,RNN 這一類的模型還有其他的缺點。以上圖來看,在處理 X1 這個元素並得到 H1 的輸出時,考量了 X1 以及它之前的 X0,並沒有考量 X2之後的其他元素,因此 RNN 可以找出 X1 與 X1 之前的元素之間的關連,而無法找出 X1 與 X1 之後的元素彼此之間的關連,這必定限制的 RNN 模型的能力。
再看 X100 和它的輸出 H100,它雖然考量了 X0 到 X100 這些元素,但是 X0 這些比較前面元素的影響力,早已經被層層處理之後稀釋了,所以 RNN 比較難以捕捉 X100 和 X0 之間的關連(亦即兩元素之間的距離越遠,RNN 越難捕捉它們之間的關連)。
Attention 機制可以緩解 RNN 上述的缺點,因此在此之前,許多研究人員已經將它用於以 RNN 為主的序列模型中,來提升模型的效能。
Transformer 的作者認為,即然 RNN 有那麼多缺點,而 Attention 能夠避免這些問題,那乾脆就只用 Attention 就好了,於是催生了 Attention is all you need 這篇論文,並提出了 Transformer 模型架構。
(註一:論文 arXiv 號碼 1706.03762 )
(註二:源自 Christopher Olah 之 《Understanding LSTM Networks》 )

