在 Glue ETL Job 中 除了 Spark 可以使用之外,還可以使用 Python Shell 進行 ETL 的處理,Python Shell 裡已經包含了 Pandas 的 Library 可以直接使用,接下來會透過 Python Shell 的方式計算出每個 User 購買前五多的商品
it.sample.s3
㇄SampleData
㇄order
⎢ ㇄orders.csv
㇄order_products_prior
⎢ ㇄order_products__prior.csv
㇄order_products_train
⎢ ㇄order_products__train.csv
㇄products
⎢ ㇄products.csv
㇄sample_submission
⎢ ㇄sample_submission.csv
㇄departments
⎢ ㇄departments.csv
㇄aisles
㇄aisles.csv
from setuptools import setup
setup(
name="python_shell_s3fs",
version="0.1",
packages=[],
install_requires=['s3fs==0.4.2']
)
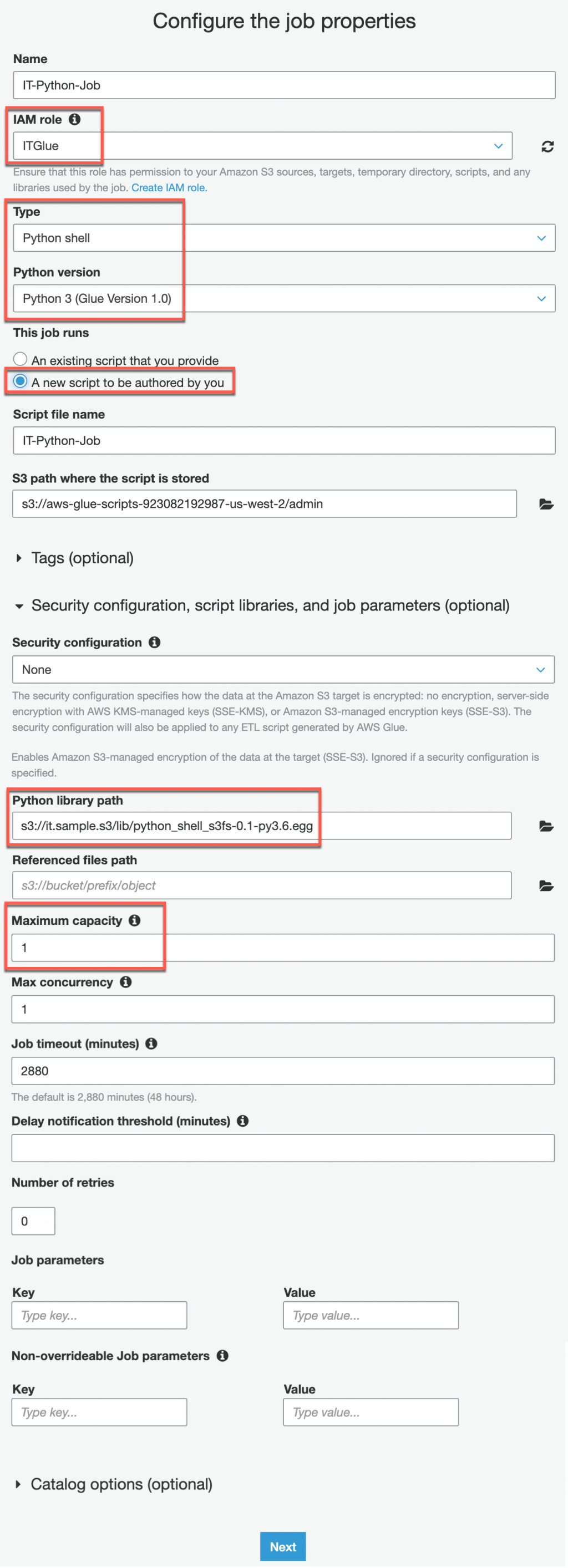
創建完成後執行 python3 setup.py bdist_egg,執行完成後你會發現多出了三個資料夾(build、dist、python_shell_s3fs.egg-info),請將 dist 中的 python_shell_s3fs-0.1-py3.6.egg 上傳到 S3 備用,我將它放在 s3://it.sample.s3/lib/python_shell_s3fs-0.1-py3.6.egg
創建 Glue Job
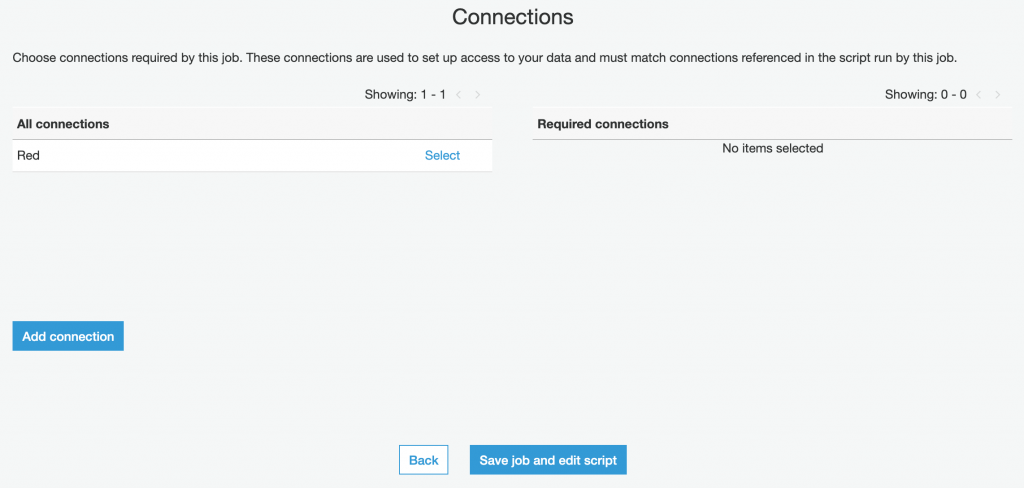
以上設定完成就可以點選下一步


 iThome鐵人賽
iThome鐵人賽