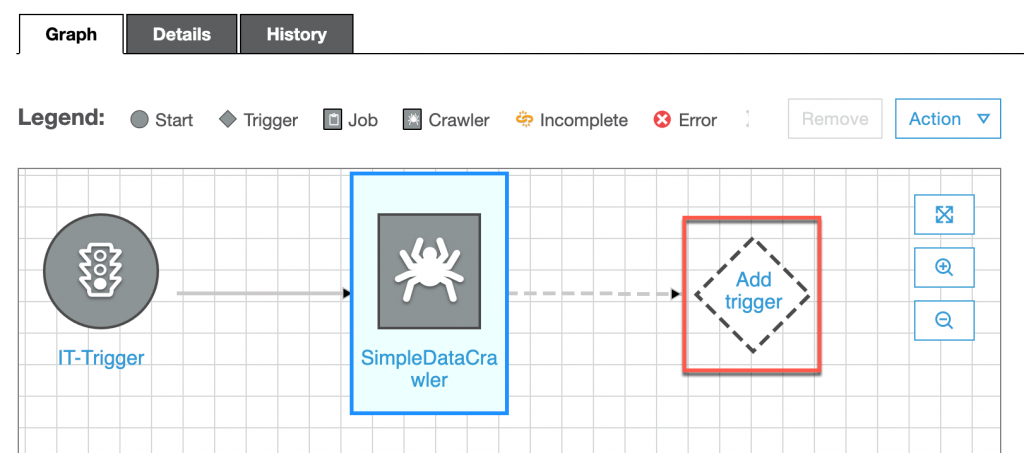
講完 Data Catalog 與 ETL Job 後,在整個資料處理的流程中可能會需要用自動化的方式讓整個流程可以夠便利,而今天就要來介紹如何創建 Glue 的自動化流程
假設我們的資料源是以天為單位的方式存入S3,如下所示,則會有 Partition 更新的需求,每一天都是一個 Partition,所以在執行 ETL Job 之前需要先執行一次 Data Catalog 來更新新的 Partition 資料,這樣 ETL Job 才能看到最新的資料
it.sample.s3
㇄SampleData
㇄order
⎢ ㇄2020
⎢ ㇄01
⎢ ㇄01
⎢ ㇄orders.csv
㇄order_products_prior
⎢ ㇄2020
⎢ ㇄01
⎢ ㇄01
⎢ ㇄order_products__prior.csv
㇄order_products_train
⎢ ㇄2020
⎢ ㇄01
⎢ ㇄01
⎢ ㇄order_products__train.csv
㇄products
⎢ ㇄2020
⎢ ㇄01
⎢ ㇄01
⎢ ㇄products.csv
㇄sample_submission
⎢ ㇄2020
⎢ ㇄01
⎢ ㇄01
⎢ ㇄sample_submission.csv
㇄departments
⎢ ㇄2020
⎢ ㇄01
⎢ ㇄01
⎢ ㇄departments.csv
㇄aisles
㇄2020
㇄01
㇄01
㇄aisles.csv
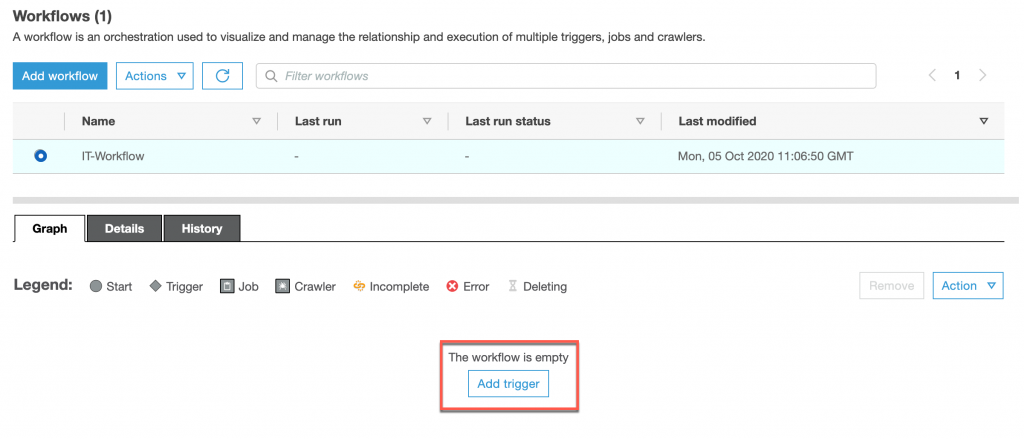
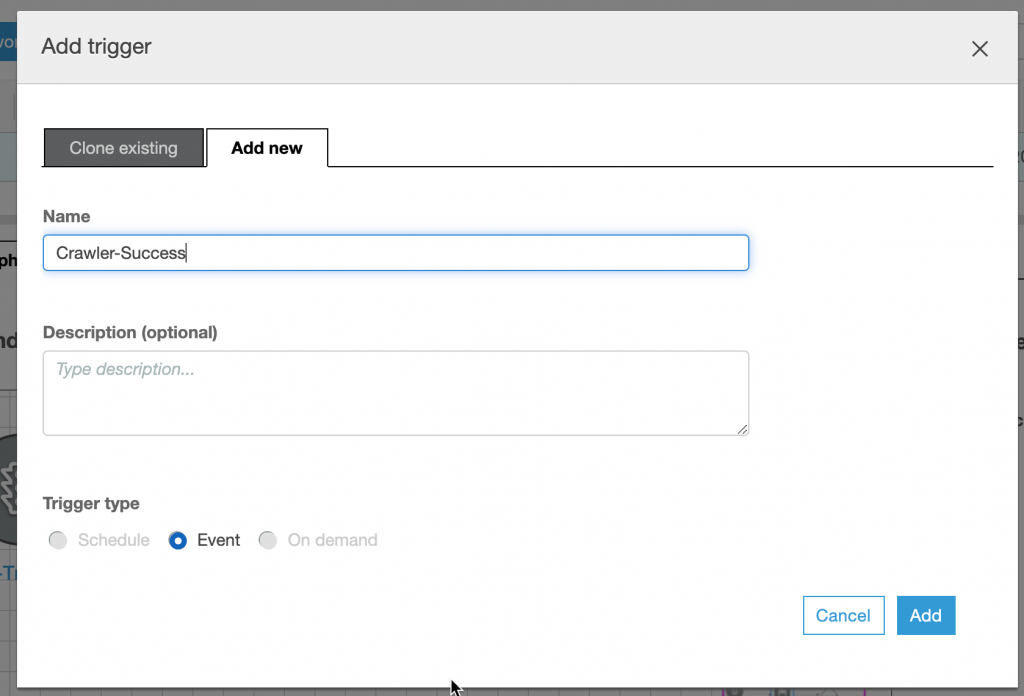
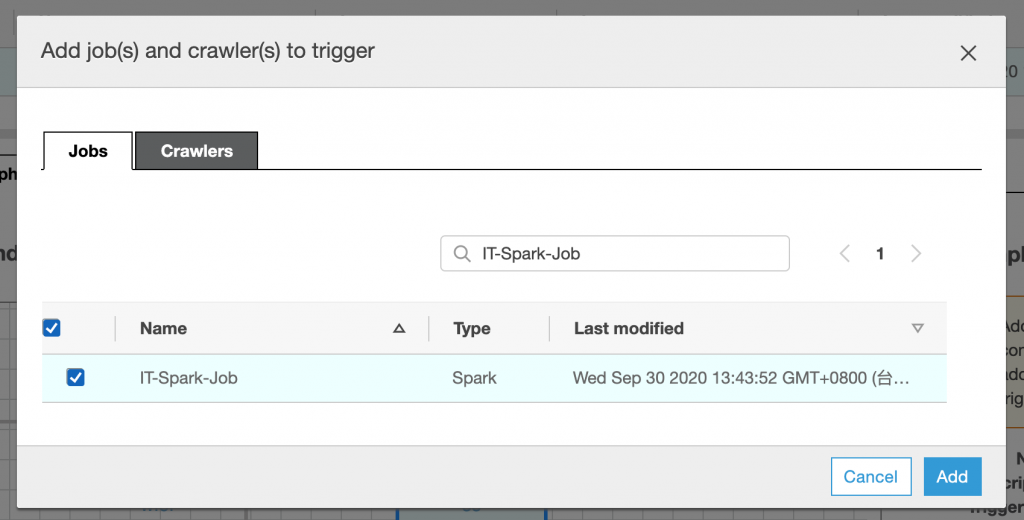
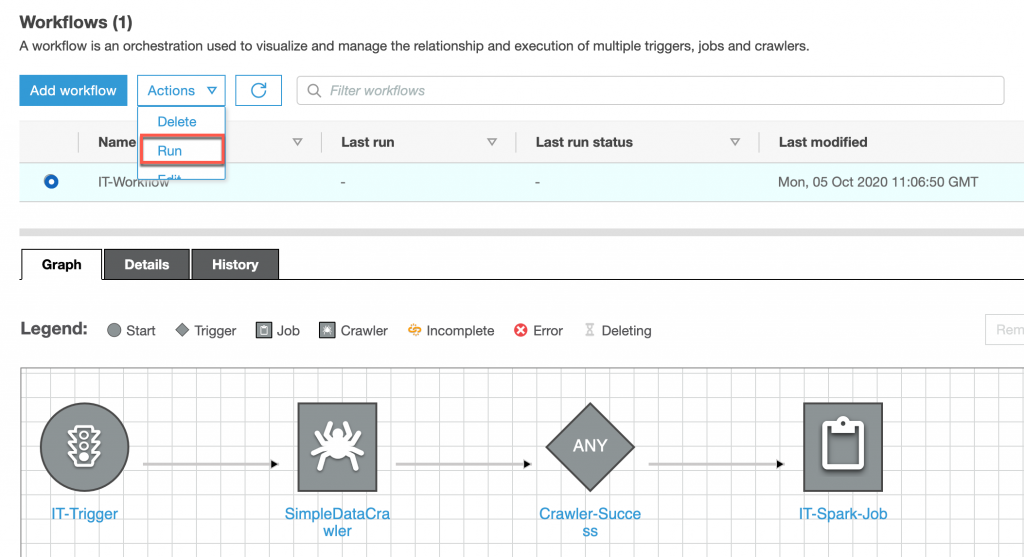
所以我們的目標是在執行完成 Data Catalog 後在執行 ETL Job





 iThome鐵人賽
iThome鐵人賽