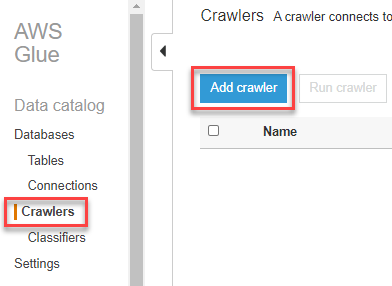
4-2. 點開 Crawler name 下面的選單,點選 Custom classifiers 裡剛剛創建的 Classifier 右邊的 Add,將他加入右邊的 Selected classifiers,代表要使用這個 Classifier 爬取資料
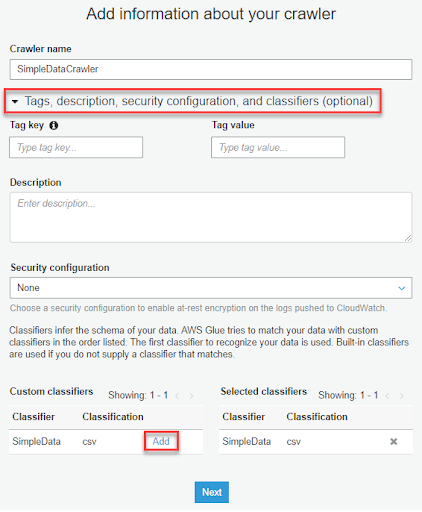
4-3. 選擇要使用的資料來源,這邊我們選擇 Data stores,也就是外部的資料源
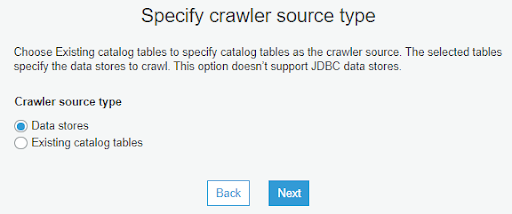
4-4. 填入剛剛上傳 order.csv 的 S3 資料夾路徑,建議可以點選旁邊的資料夾圖示,用圖形化介面的方式選擇 S3 路徑,除了比較方便也可以避免使用到其他 Region 的 S3 造成資料無法訪問
另外要記得選擇資料所在的資料夾,不能直接選擇 CSV 檔,如果直接選擇 CSV 檔 Crawler 會無法正常爬取資料
最下面的 Exclude patterns 可以排除選定的路徑下所不要的資料或資料夾,例如 在您的資料中會有不需要爬取的資料夾 testdir,那我們可以在 Exclude patterns 中設定 testdir/**,這樣 Crawler 就不會去處理 testdir 中的資料
4-5. 這邊我們先選擇 No 繼續往下走,如果需要使用多個資料源可以選擇 Yes


 iThome鐵人賽
iThome鐵人賽