就像買房子最重要的三點就是 地點!地點!地點! 一個企業級的平台最重要的三點就是監控!監控!監控!
OpenShift 提供了一套整合了 Prometheus,Alert Manager 及 Grafana 的系統監控功能,它支持監控系統相關套件的 Metrics,包括一組預設的 Alerts 以立即通知系統管理員任何發生的問題以及預設的一組Grafana Dashboards。
Cluster Monitoring Operator: 最核心主要的組件. 它控制已經被部署的其他監控用的組件並確保這些組件有隨著系統升級做更新。
Prometheus Operator:用來創建,配置和管理 Prometheus 和Alertmanager。
Prometheus:一套開源並且用於監控容器或微服務的工具。 Prometheus 會根據時間序列,收集並存儲這些目標對象的 Metrics 。 它是主要用來收集和監控整個系統和服務數據的工具。
Prometheus Adapter:提供一組與 Kubernetes 系統資源 Metrics 相關的 API,譬如 CPU 跟 Memory 的使用率,以提供給 "Horizontal Pod Autoscaling (HPA)" 使用。
kube-state-metrics:監聽 Kubernetes API server 並產生系統上物件的狀態的 metrics 給 Prometheus 查詢使用。
openshift-state-metrics:類似 kube-state-metrics,但它用來提供 OpenShift 專屬的物件的狀態的 metrics。
node-exporter:node-exporter 部署在每個節點,負責收集每個節點的 metrics。
Alertmanager:提供和管理 Alerts
Grafana:提供使用者介面方便管理者查詢及觀察系統狀態,包含一組預設,針對 OpenShift 設計, read-only 的 Dashboard。
這些Components 大部分被部署在 "openshift-monitoring" namespaces
$ oc get deploy -n openshift-monitoring
NAME READY UP-TO-DATE AVAILABLE AGE
cluster-monitoring-operator 1/1 1 1 110d
grafana 1/1 1 1 110d
kube-state-metrics 1/1 1 1 110d
openshift-state-metrics 1/1 1 1 110d
prometheus-adapter 2/2 2 2 110d
prometheus-operator 1/1 1 1 110d
thanos-querier 2/2 2 2 110d
OpenShift 提供介面讓系統管理員直接在 OpenShift Web UI 做監控。
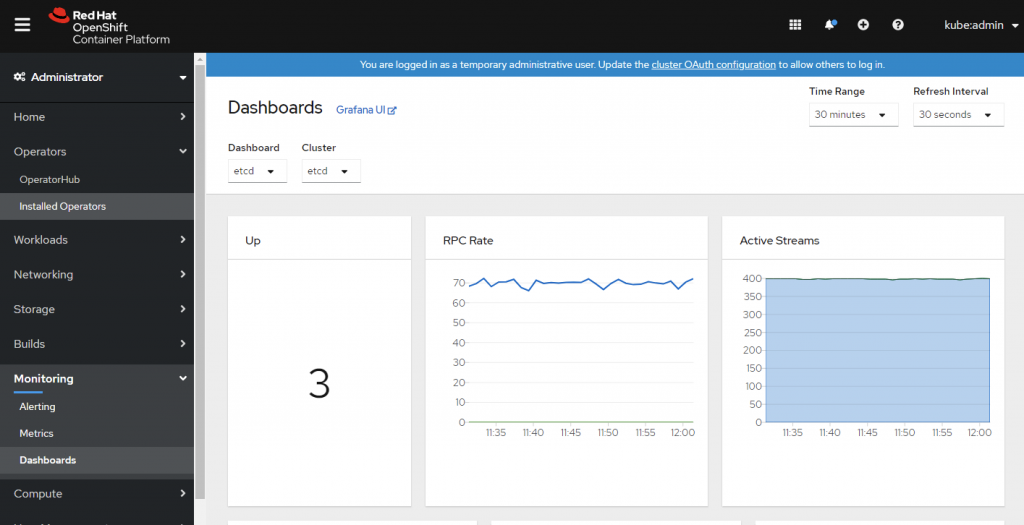
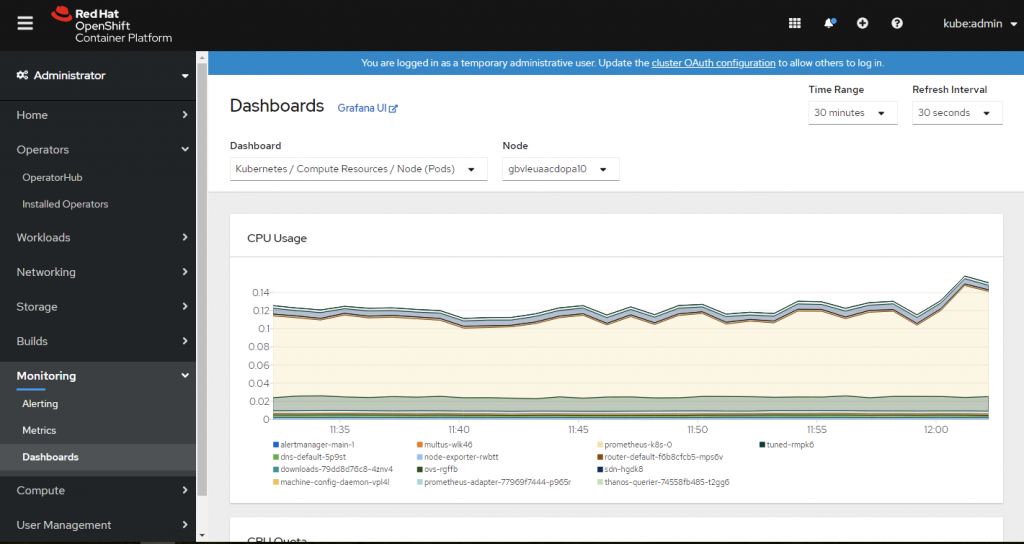
當然,管理者仍然也可以透過 OpenShift 使用者帳戶登入原本的 Prometheus 跟 Grafana 介面。