所謂"工欲善其事,必先利其器",我們需要一個強大的工具來輔助我們進行資料分析,今天就帶大家來安裝Anaconda及Jupyter Notebook。
Anaconda是一套免費開源的平台,支援Python及R語言,被廣大使用者用於資料分析、機器學習、深度學習等應用,且適用於Windows、Linux和MacOS,是目前最受大家歡迎的虛擬環境管理工具。詳細介紹可至官網查看:
Anaconda | The World's Most Popular Data Science Platform
Jupyter Notebook是Anaconda所支援的其中一個套件,它是為進行程式編譯而開發的應用環境,使用Python來撰寫,會建議初學者使用Jupyter Notebook的好處是,它可以逐行編譯逐行輸出,進行Debug時相對方便,而且很容易呈現資料視覺化,執行起來非常簡單容易上手。
在介紹套件(Package)前,先來介紹一下模組(module),在進行程式工作時,有時候我們會重複用到好幾次相同的功能,例如:計算一份資料的平均值,我們可能要執行以下程式。
x=[10,20,30,45,67,88,99,123] #假設有一份資料x
sum=0
for i in x: #計算樣本數
sum=sum+i #計算總和
print("平均值為",:sum/i) #輸出結果
然而我們每次要計算平均值都必須這樣打一次實在是太麻煩了,這時我們就可以創立一個計算平均值的模組,只要每次我們每次需要使用時,就可以用呼叫的方式來使用,方便許多。
#建立模組
def mean(x):
sum=0
for i in x:
sum=sum+i
return sum/i #返還結果
#實際使用時
x=[10,20,30,45,67,88,99,123] #建立資料後
mean=mean(x) #呼叫模組
print("平均值為",mean)#得到結果
很多個同性質不同功能的模組和在一起,就是套件啦~在做資料分析時,我們常常需要需要用import的方式來載入這些前人所提供的套件,省下我們從頭撰寫程式的時間,下面就來看看有哪些常用的套件吧。
Pandas是一個強大、靈活的資料分析工具,能將資料以DataFrame的表格形式呈現及處理,非常適合用於初期的資料探索、整理等。
Numpy主要提供一些陣列的運算支援以及高效率的處理模組,也是Python資料分析的基礎工具,Numpy對於陣列的運算提供了相當多的支援,使用者常常可以以簡短的程式取代冗長的迴圈計算。
Matplotlib主要功能為資料視覺化,提供使用者繪製各種不同的圖形,方便我們做視覺化分析。使用者也可以依照個人喜好調整圖形的各種參數,畫出獨一無二的圖形。
Keras是一個用Python編寫的高級神經網路API,提供了大量深度學習的模組,使用者可以透過它開發深度學習的模型進行訓練、預測以及使用一些最佳化工具等等。
首先至官網下載Anaconda Individual Edition

這邊的安裝其實非常簡單,幾乎是可以一鍵按到底的那種
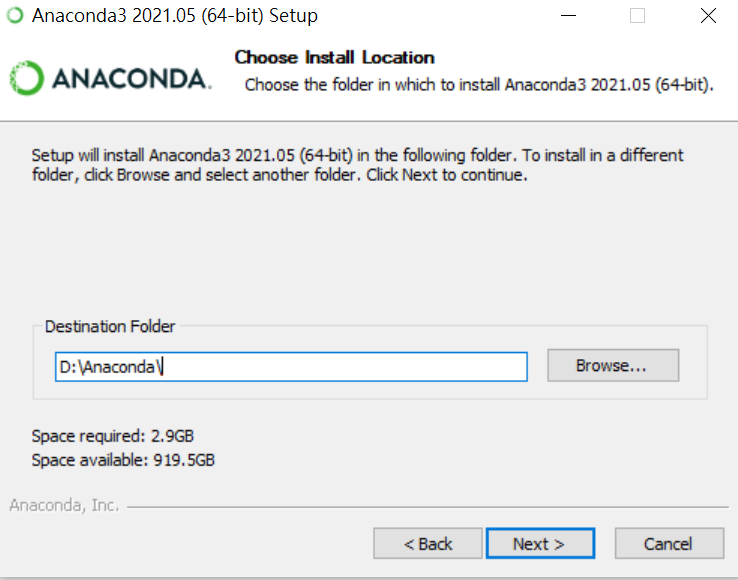
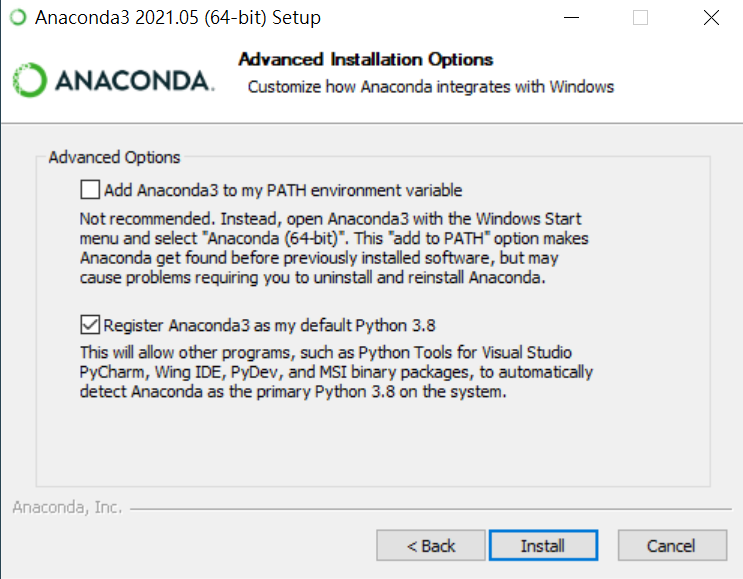

由於新版的Anaconda在安裝時就會預設連同Jupyter Notebook一起安裝了,因此我們就不用麻煩的在裝一次,那我們就試試看我們的Jupyter Notebook是否運作正常吧。
在開始欄位可以找到它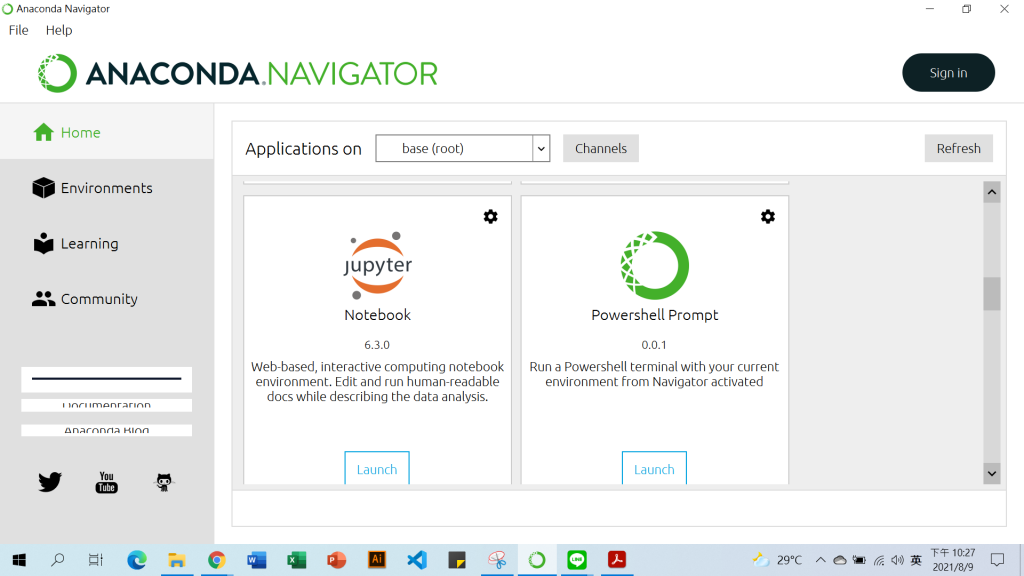
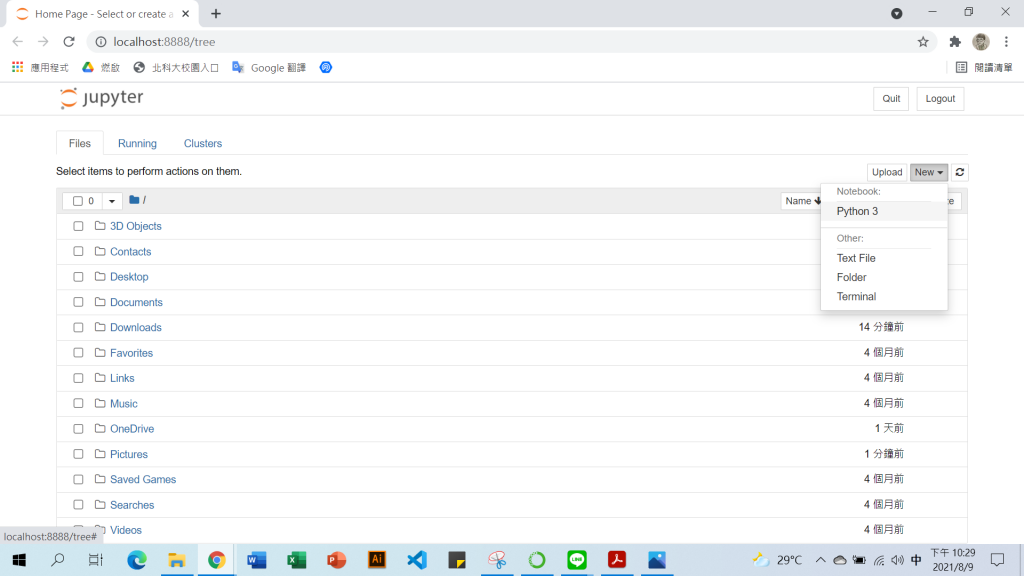
不免俗的我們也來Print一下Hello World(按Shift+Enter即可執行程式)
conda install pandas #後面接想安裝的套件名稱
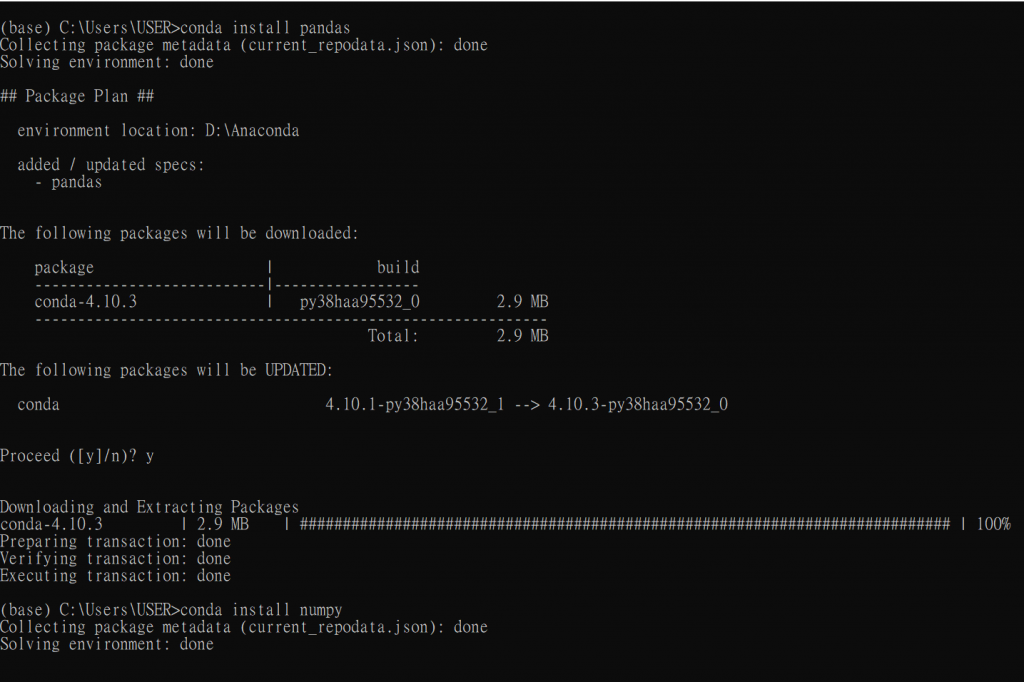

import pandas as pd
import numpy as np
安裝環境及套件大概到這邊告一段落啦,其他的就讓大家自行摸索,畢竟"讀萬卷書不如行萬里路"嘛!今天只介紹了幾個基本套件,其他的會等到後面用到時在一起介紹,那就明天見囉~


 iThome鐵人賽
iThome鐵人賽