昨天簡單猜測了非同步框架所應具備的基本功能 ( 某種資料模式, thread schedule ), 可以發現 Multi-threading data structure 在非同步框架中是必須的存在, 所以為了之後可以看懂原始碼, 會花幾天簡單說說一些常見的 concurrency 觀念 , 幫助我們了解之後遇到的 Multi-threading data structure 。
atomic operation 可以說是用來理解底層同步機制的基石, 就現實面來說在之後閱讀原始碼的過程會大量的遇到基於原子操作的 CAS 演算法, 而且就我目前的觀察, 大多數同步機制的實踐會使用 lock-free 演算法, 基於上述原因, 我會用盡可能地把之後可能會用到的 atomic 操作相關觀念闡述於這幾天的文章。 因為這部分的教學網路上蠻多的, 但不提一下我又怕沒人要看我寫的文, 所以我會盡可能簡單帶過。
指不會被執行緒調度機制打斷的操作,這種操作一旦開始,就一直運行到結束,中間過程可以假設為沒有其它 thread 會與其交互
因此利用原子操作可以回避掉,race condition , transaction 等資料錯誤順序存取的問題
關於 thread 的意義可以參考我以前文章中提到的舉例
C# Task 十分鐘輕鬆學同步非同步 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天
實際上有許多定義, 但基於篇幅以下僅闡述其中一種
藉由上面的定義我們可以瞭解到, asynchronous 是實踐 concurrency 的方法之一, 也因此在探討 asynchronous 的過程沒有辦法迴避去了解 concurrency 相關議題。
Race condition 是 concurrency programming 一定會遇到的問題, 主要問題點在於, 當有多條 thread 在面對同一個 storage 交叉運作時, 有可能因為錯誤的資料取用順序導致錯誤結果。
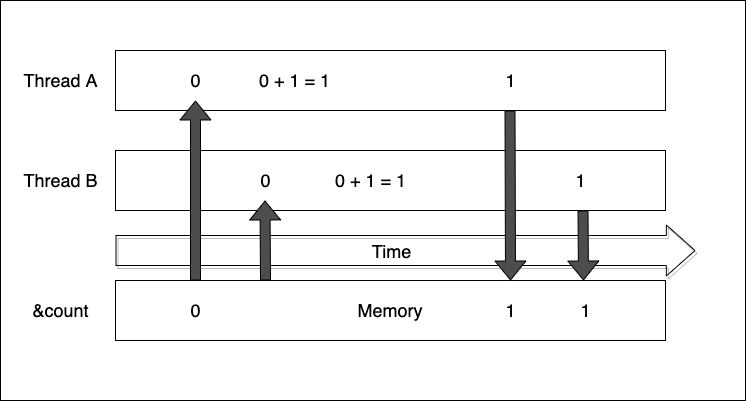
以下用圖片簡略說明 :
當兩條 thread 同時取用了變數且其值為 0 , 兩條 thread 各自對 0 加一後存回, 使用者以為變數應該是2, 但其實因為做了兩次 0 加 1 , 所以最終的結果是 1。
以下程式碼為兩條 thread 各把一個變數加 5000 , 最終結果應該是 10000 , 但會因為 Race condition 導致得不到 10000 這個結果。
#include <iostream>
#include <thread>
using namespace std;
void plusOne(int* count) {
for (int i = 0; i < 5000; i++) {
int newCount = *count;
newCount++;
*count = newCount;
}
}
int main() {
int count = 0;
thread ThreadA = thread(plusOne, &count);
thread ThreadB = thread(plusOne, &count);
ThreadA.join();
ThreadB.join();
cout << &count << " : " << count << endl;
}
為了解決 Race condition 所以必須由 OS 或 hardware 提供某種機制來限制 thread 切換的自由度。
而用來限制 thread 自由度的方法被稱作 "同步機制" , 因為其目的是強迫 processor 在某些段落或某句指令僅能同步運行( 不可以切換成別的 thread ) , 同步機制的模型被廣泛的使用在應用端的語言, 例如 JS 中就是利用 await 來限制 thread 停下來等待 IO 回傳, 不要創建新的 thread 且切換過去繼續走。
同步機制分成以下兩種 :
atomic operation 的本質是由 CPU 提供的 atomic instruction, 以下這篇文章提到了 ARM CPU 在 atomic operation 的實踐方法。
The ARM processor (Thumb-2), part 11: Atomic access and barriers
CPU 提供指令在鎖定特定記憶體的同時進行操作, 鎖定的作用是檢測該記憶體是否被該指令以外的指令操作, 如果有就放棄操作, 如果沒有就完成操作。
所以若是用以下流程操作, CPU 可以實踐最基本的 atomic operation 。
而前人透過包裝上述指令完成了許多 atomic operation , 以下敘述常用的3種 :
可以發現即便是現今廣泛被使用的原子操作, 其功能都很少, 這是受限於 CPU 提供的 instruction 功能單一, 所以包裝出這種層級的 atomic operation 已是極限。
但是單單靠這幾句 atomic operation 要寫出 concurrency 的 program 是困難的。
所以前人發展了名為 CAS 的 pattern 來使後人可以無腦的利用上面三句 atomic operation 來實踐多數"同步機制"所需功能。
明天會繼續跟大家聊聊 CAS 以及 Lock-Free , 後天應該會利用 CAS 實做簡單的 Lock-Free Data structure 來幫助大家釐清概念
明天見 !


 iThome鐵人賽
iThome鐵人賽