大部分的人對於資料開始產生興趣,不外乎就是因為想要預測未來。
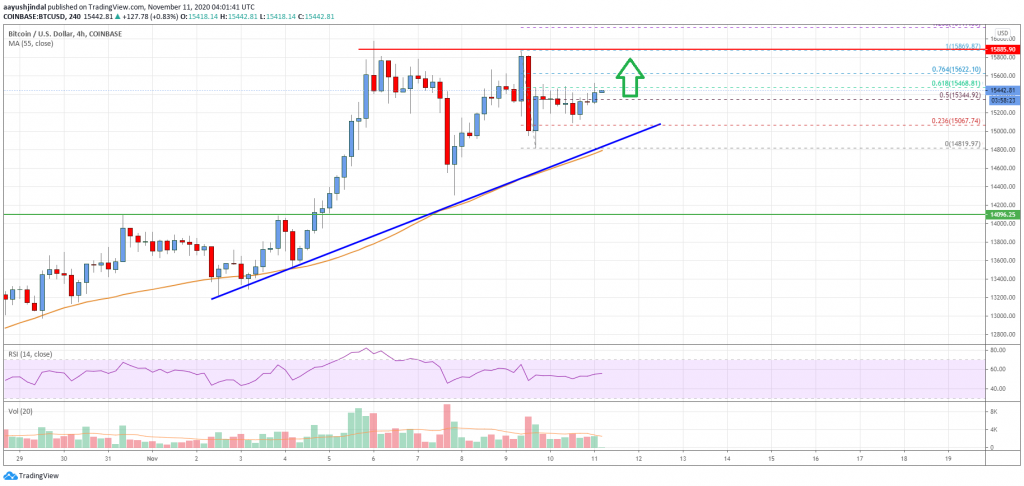
(https://www.livebitcoinnews.com/bitcoin-price-analysis-btc-eyes-more-upsides-above-16k/)
即便不用特別的數據分析,我們也習慣透過搜集資料來對未來做猜測。
不管看到陰天就知道等等就會下雨、或是約會時早就知道你朋友會遲到,我們都會透過曾經發生的事情來預測可能發生的狀況以提早做準備。我們從過去的資料中看見了某種模式(Pattern),即便沒有精確的數字,但也會隱約有個「感覺」(即便「感覺」常常不準)。這個「模式」就是所謂預測模型,每種模式都會解釋一部分的事實,同時也提供了對於未來的猜測。
例如你心中有個「約會遲到模式」,只要是 OOO 就會遲到,但是 XXX 就不會遲到。
對應到比較資料科學的用語來說的話
這邊介紹幾個常用的預測模型以及用途
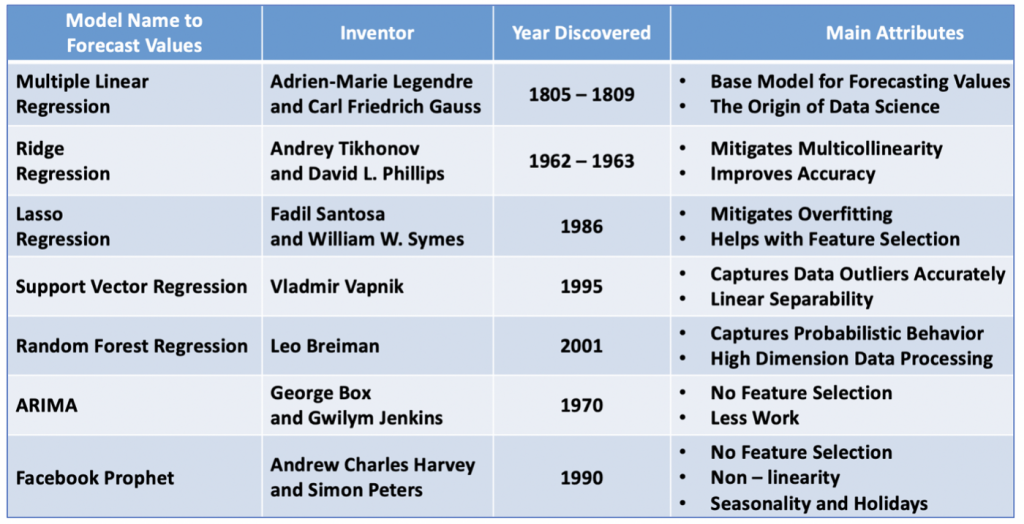
(https://foxworthy-8036.medium.com/18-types-of-predictive-models-in-data-science-b53275810032)
迴歸模型有非常多種(見上圖),但主要目的都是為了預測**「數值型」**的結果。
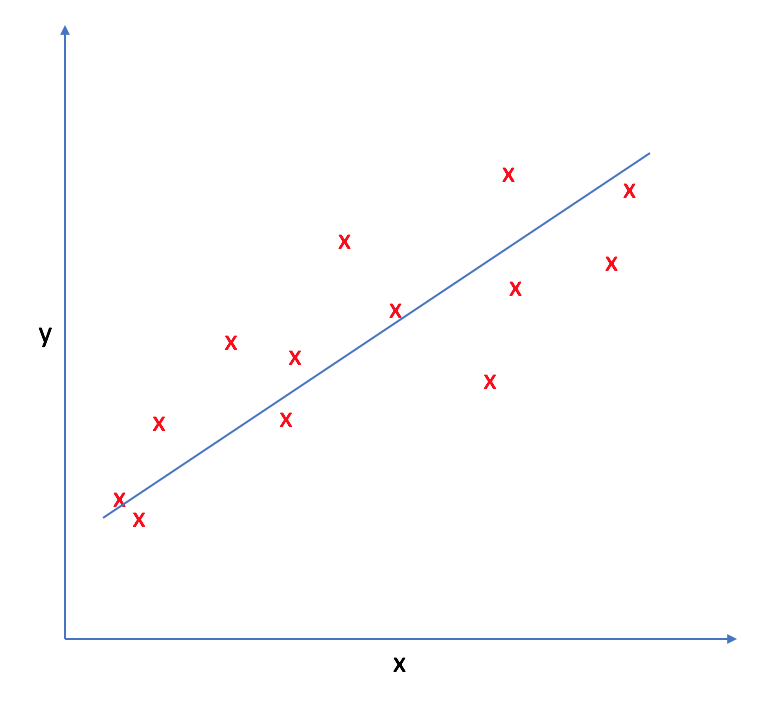
(https://www.jeremyjordan.me/linear-regression/)
就以最常見到的簡單線性迴歸來說好了,如果你每天在記錄體重和體脂肪的關係(如上圖),在你沒有特別運動的情況下,會發現好像可以在這些資料點之間畫一條直線貫穿所有資料,儘管不是所有點都在線上,可以看到當體重越高時、體脂肪也跟著上身,也可以想像如果未來體重再上升的話,體脂肪也可能跟著上升。
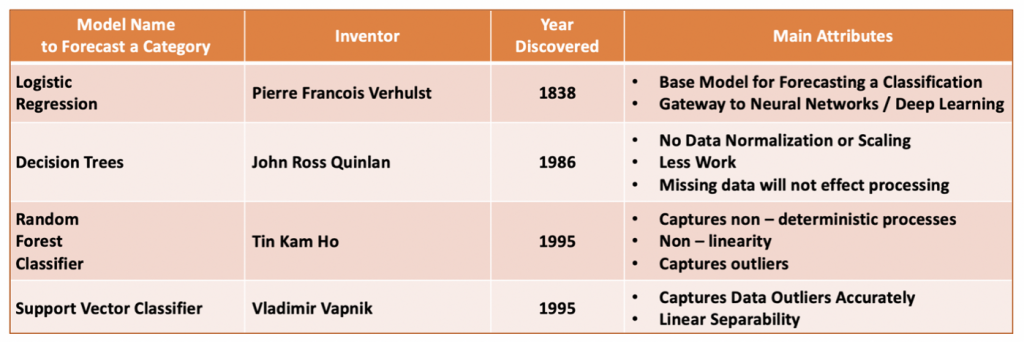
(https://foxworthy-8036.medium.com/18-types-of-predictive-models-in-data-science-b53275810032)
除了預測數值外,我們也很常問要或不要的二元分類問題或多元分類。這種模型的結果不是數值,而是上一篇提到的類別變項,像是下雨/不下雨、點擊/不點擊,或是貓/狗/魚這樣的問題。
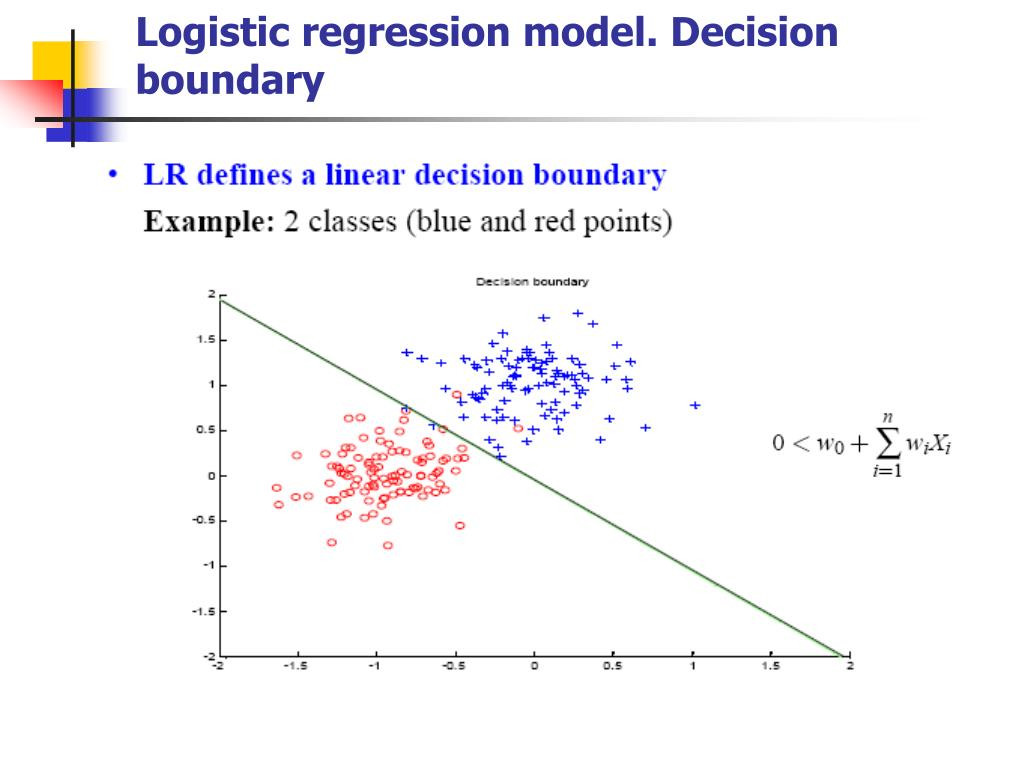
(https://www.slideserve.com/griffin-munoz/logistic-regression)
像上圖就是一個在做分類模型時很常使用的羅吉斯迴歸(Logistic Regression),羅吉斯迴歸會在空間中尋找一條能將結果分成兩邊的線,未來只要根據特徵值(Features)就能知道對應的分類是什麼。
由於預測模型是根據過去的資料來學習資料的模式,方便我們之後能夠透過輸入的特徵值來預測結果,所以在訓練預測模型時很重要的就是需要準備一堆已經知道「答案」的資料。
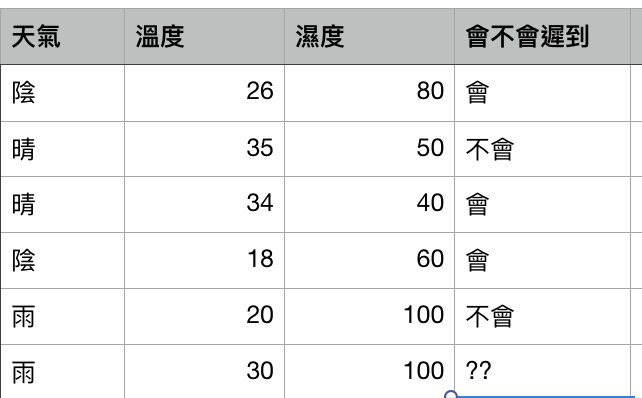
例如上圖,我們想要知道約朋友出門會不會遲到,需要先搜集過去可能影響遲到的特徵值(Feature),像是天氣、溫度、濕度,接著還需要在這些情況下朋友的遲到狀況(Label),才有辦法學到遲到預測模型。
從這個例子你可以看到,即便做一個簡單的遲到預測模型,我們都還是得循序漸進的先定義好要搜集的資料(天氣資料、遲到紀錄),再將這些資料整理到 Excel 中,看一下有沒有錯誤的紀錄資料、做一下資料處理,才有辦法進到模型階段。這也是資料產品很重要的特色 - 循序漸進,要做高層的分析,那些層次基礎的工作一點都跑不掉。
https://foxworthy-8036.medium.com/18-types-of-predictive-models-in-data-science-b53275810032
https://www.jeremyjordan.me/linear-regression/
https://www.slideserve.com/griffin-munoz/logistic-regression

