TiKV Server是負責保存數據資料,採key-value模式儲存,且key的排列是二進制有序的。這部分TiDB是採用RockDB來控制,RockDB是Facebook以Google的levelDB為基礎再開發的一套key-value儲存引擎。這部分交給專業的來,所以TiDB就沒有另外再自行開發一套。
另外TiKV透過了實作Raft協議讓資料產生副本,分散在每一個Tikv node上,副本通常是3份。資料會先寫入raft log中,然後透過協議同步複製到其他node上,然後再寫入rockDB,最終透過RockDB的機制flush到disk中。這樣一個node掛了還有其他node可以使用。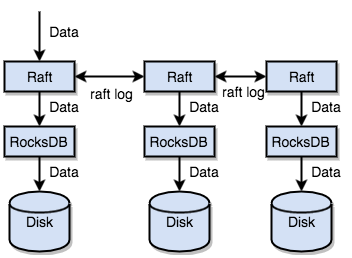
引用pingcap官網架構圖
前面提到key的排列是有序的,而TiKV會依據設定的大小將key-value切成一小段,每一段稱為Region,每一段的範圍是[Key1,Keyn),即包括Key1到Keyn之間不包括keyn。
如圖所示 資料會被切成大小相近的四份(R1~R4)。而這四個Region會被平均分佈到三個node上,如下圖node1有R1與R2,而node2中有R3,node3則有R4。這部分是PD Server做的調度,我們放到後面介紹PD的時候再解釋。
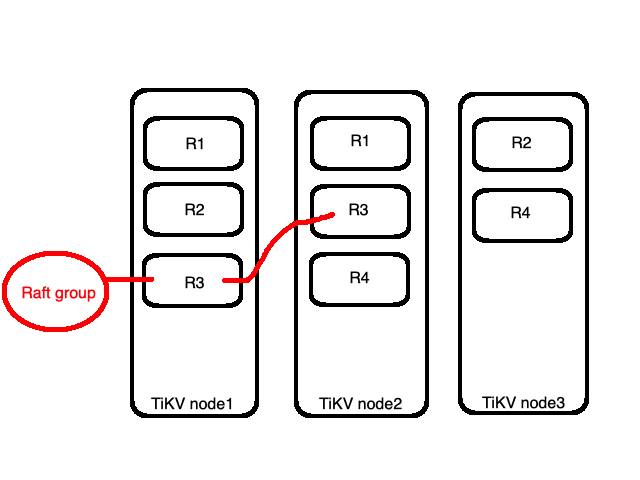
以上圖為例,node1與node2都有R3,則是我們前面提到的副本也被稱作replica,是以Region為單位做副本機制。而全部的R3統稱為一個Raft group。一個Raft group裡頭會有一個leader與多個follower,預設所有讀跟寫的操作都會透過leader,寫的部分會先寫入leader然後複製到follower,讀的部分就只要在leader讀。
有沒有發現這樣的機制可能會造成的問題?瓶頸有可能會卡在leader身上,所以目前的版本有支援新的功能Follower Read,藉以分散leader的loading。
除此之外TiKV還可以透過Coprocessor為TiDB分擔部分的計算,也就是前面討論TiDB架構的時候提到的物理優化計劃的執行者。

