2021 iThome 鐵人賽
分享至
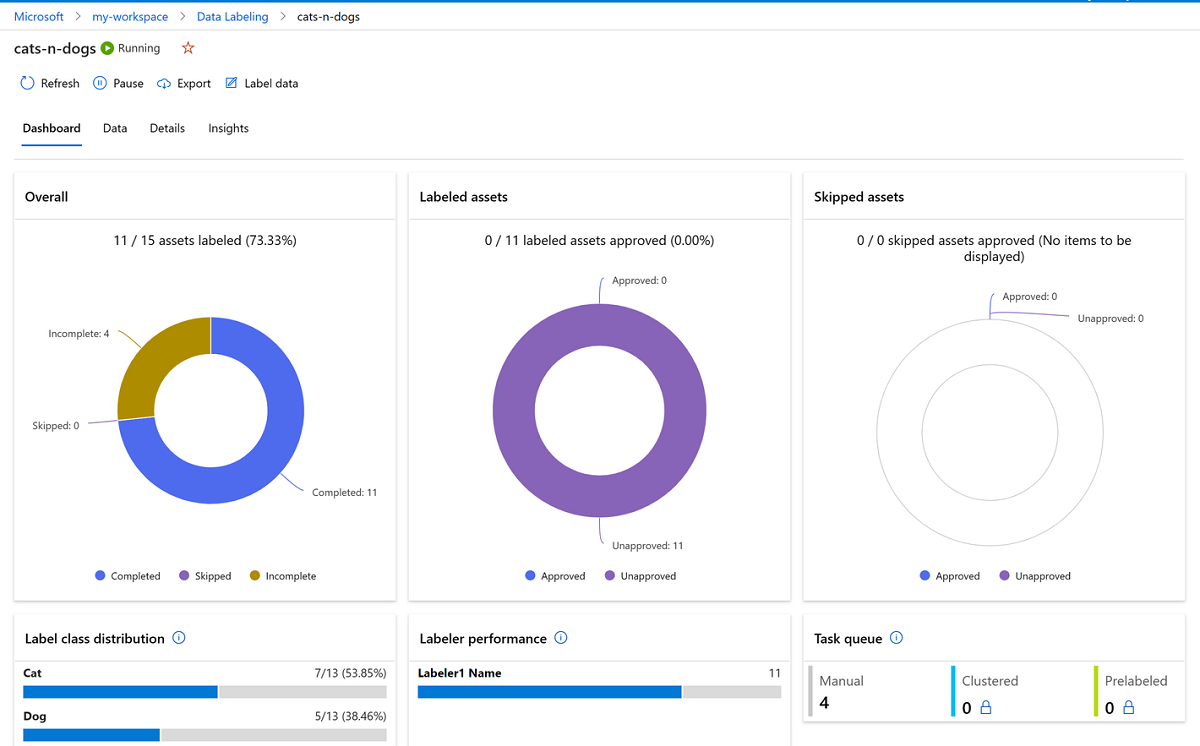
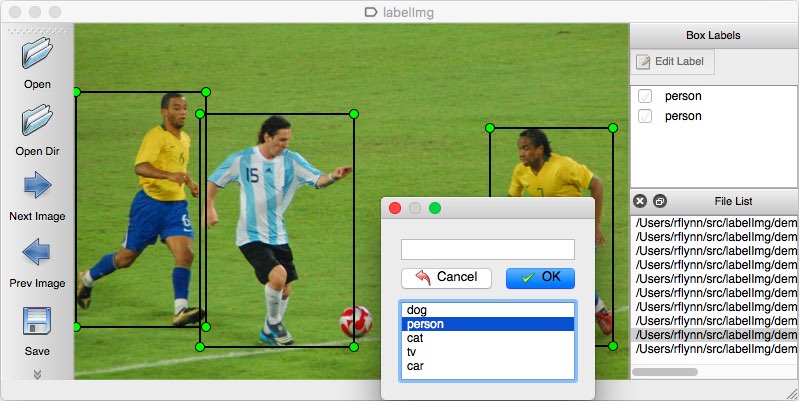
標註資料與特徵工程是處理資料重要的步驟,目的都是為了讓模型效果最佳化,標註的一致性、特徵工程到位都對模型影響至關重要。現實生活情境的資料標註向來不是件容易的事情,但資料在變、世界在變,為了 ML 系統的健康,還是好好地面對 dirty work 吧。
#如果是您要如何讓以下記錄方式一致? A: 嗯...下次會議在11/01舉行。 B: 嗯,下次會議再11/1舉行。 C: 下次會議在11月1日舉行。 D: [語助詞]下次會議在11月1日舉行。
想問如果要自製標注軟體的話需要用到那些函示庫上網找資料都是找到開源軟體但作業需要自己做!
IT邦幫忙