我想先回來介紹一些深度學習框架好了,
非類神經的演算法也可以被歸為AI,
但是神經網路的深度學習算是兵家必爭之地。
假設去應徵要當一名AI軟體工程師,應該不會pytorch,也要會tensorflow吧。
圖片分類算是學深度學習時,
一定會碰到的基礎功能。
下面先分享tensorflow官網基礎教學的使用方法:
參考網站
https://www.tensorflow.org/tutorials/images/cnn?hl=zh_tw
安裝
pip install tensorflow
引入模組
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
資料集為cifar10,總共有10個類別,有卡車、船、飛機、馬、青蛙、狗、鹿、貓、鳥、汽車、飛機,
每個類別有6000張圖片,在load_data的時候,就幫我們切分好了訓練集及測試集,
而每一張圖,為numpy array的格式
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
用list來對應答案與順序
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
將像素 Normalize變成介於0-1的數值,以降低計算複雜度
train_images, test_images = train_images / 255.0, test_images / 255.0
建設模型之前,也可以先查看一下原始資料
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

再來是model的建立,採用的是官網使用的CNN:
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
開始訓練,設定為5個epoch:
history = model.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
評估模型,查看損失函數與準確度:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(test_loss)
print(test_acc)
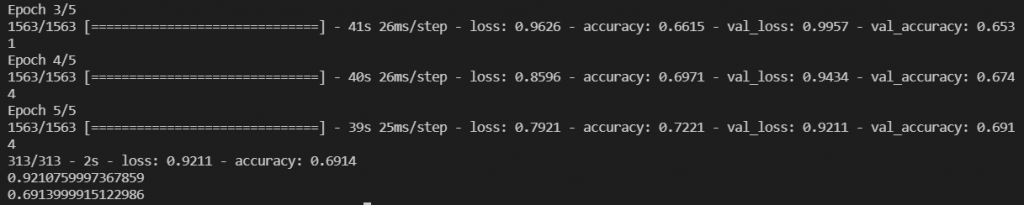
作圖看,可以查看訓練狀況,以及有沒有過擬合的情形:
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
可以發現在這樣的設定之下,準確度不超過70,
因此我想使用autoML的套件autokeras來測試看看,
如果讓程式以往格搜尋的方式自行搭建模型,是否能提升準確度。
由於autokeras使用的是tensorflow 2.5,
所以我使用colab來執行程式(可以在工具區 鍵盤快速鍵設定喜好的快捷鍵):

使用依樣的資料集,一樣用5個epoch
可以發現運行了很久,可惜準確度無法有效提升: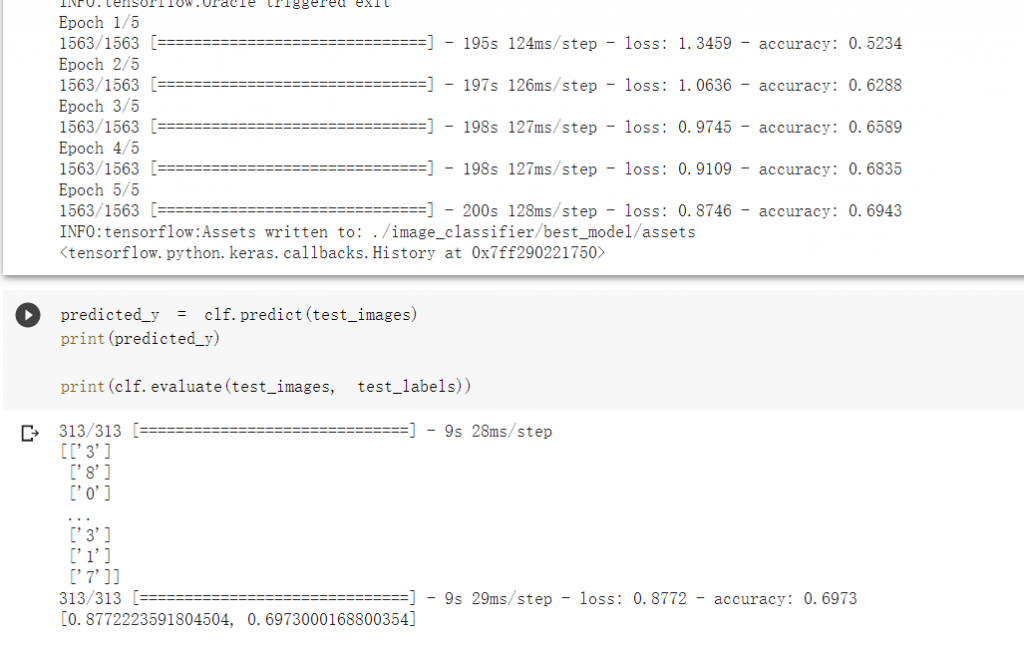
我還記得我畢業專題是用幾百張 積雨雲、層雲、捲雲來做分類,
是希望以雲的形狀來即時預測天氣,準確度是還可以,是因為一開始挑選的圖片差異就很大。
但是如果將模型放入樹梅派,然後放入溫室來拍攝天空就不知道效果如何(先不說準確度了,樹梅派耐的了高溫嗎?)。
有機會的話,大家也可以搭建看看圖片分類的模型,
看能不能有人能搭建出查看牛排幾分熟的模型。
(不確定用物件辨識會不會更好做,但我從外觀來看,主要是顏色的差異)

