這一篇,我想再參考官網的攻略寫一篇,
不過內容多增加了一些程式上的處理,以及過擬合(Overfitting)時的處理。
參考頁面:https://www.tensorflow.org/tutorials/images/classification?hl=zh_tw
首先,引入模組:
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
下載花朵照片資料集,有五類花朵,總共3670張圖片,放置於五個資料夾,
我們可以印出下載路徑,以及查看圖片數目:
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)
print(data_dir)
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
切分訓練集以及測試集,validation_split為切分測試集的比例,
而seed為必須給而且需要為一樣的參數(負責洗牌)
batch_size = 32
img_height = 180
img_width = 180
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=456,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=456,
image_size=(img_height, img_width),
batch_size=batch_size)
可以查看標籤的內容有那些花:
class_names = train_ds.class_names
print(class_names)

緩存資料(可以給路徑cache("/path/to/file")),增加訓練速度,
並且將前處理加入pipline:
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
建立cnn模型,
可以發現第一層,有先進行前處理,將相素數值都除以255,以進行標準化(機器不用算很巨大的數值)
num_classes = 5
model = Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
epochs設定為10,進行訓練
epochs=10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
查看訓練過程:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
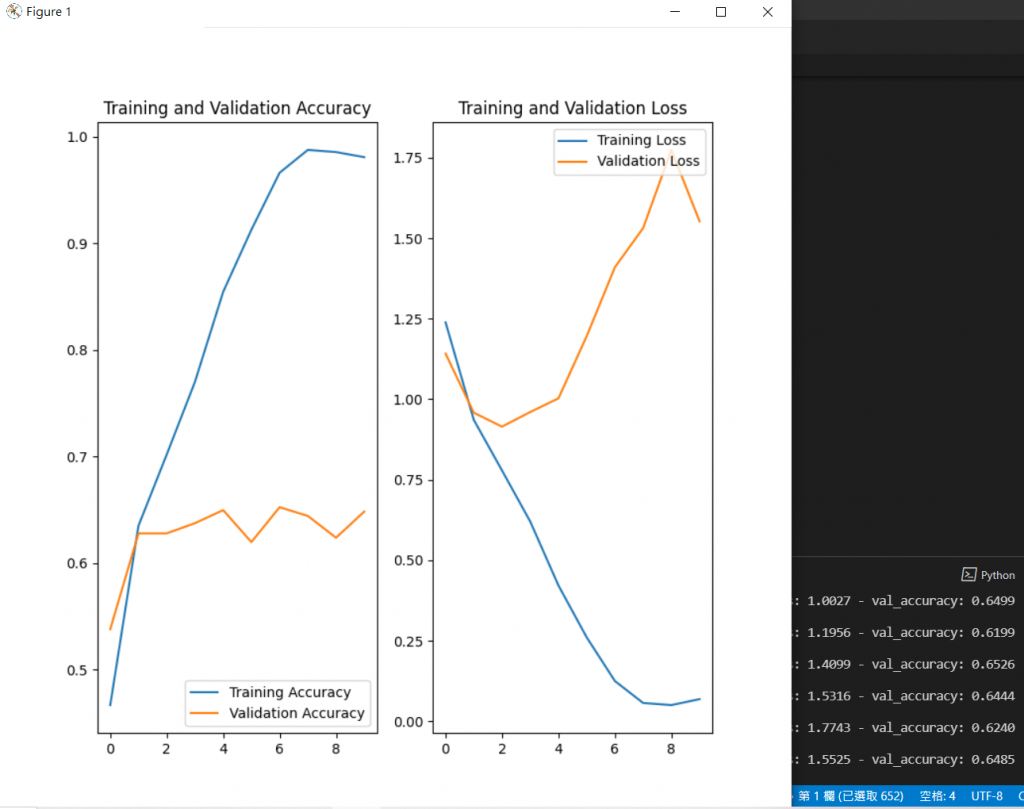
可以發現訓練集有隨著時間增加準確度,
但測試集的準確度卡在0.65就不在提升了。
測試集的損失函數反而隨著時間增加了,
代表有過擬合(Overfitting)的現象。
我們可以使用扭曲、翻轉、歪斜的方式(假設要辨識前方禁止通行交通號誌,就不適合使用這招)來增加訓練集資料。
data_augmentation = keras.Sequential(
[
layers.experimental.preprocessing.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.experimental.preprocessing.RandomRotation(0.1),
layers.experimental.preprocessing.RandomZoom(0.1),
]
)
另一種方法為我們在模型中,加一層Dropout來調節權重:
layers.Dropout(0.2)
重新建立新的模型:
model = Sequential([
data_augmentation,
layers.experimental.preprocessing.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
進行訓練:
epochs = 15
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
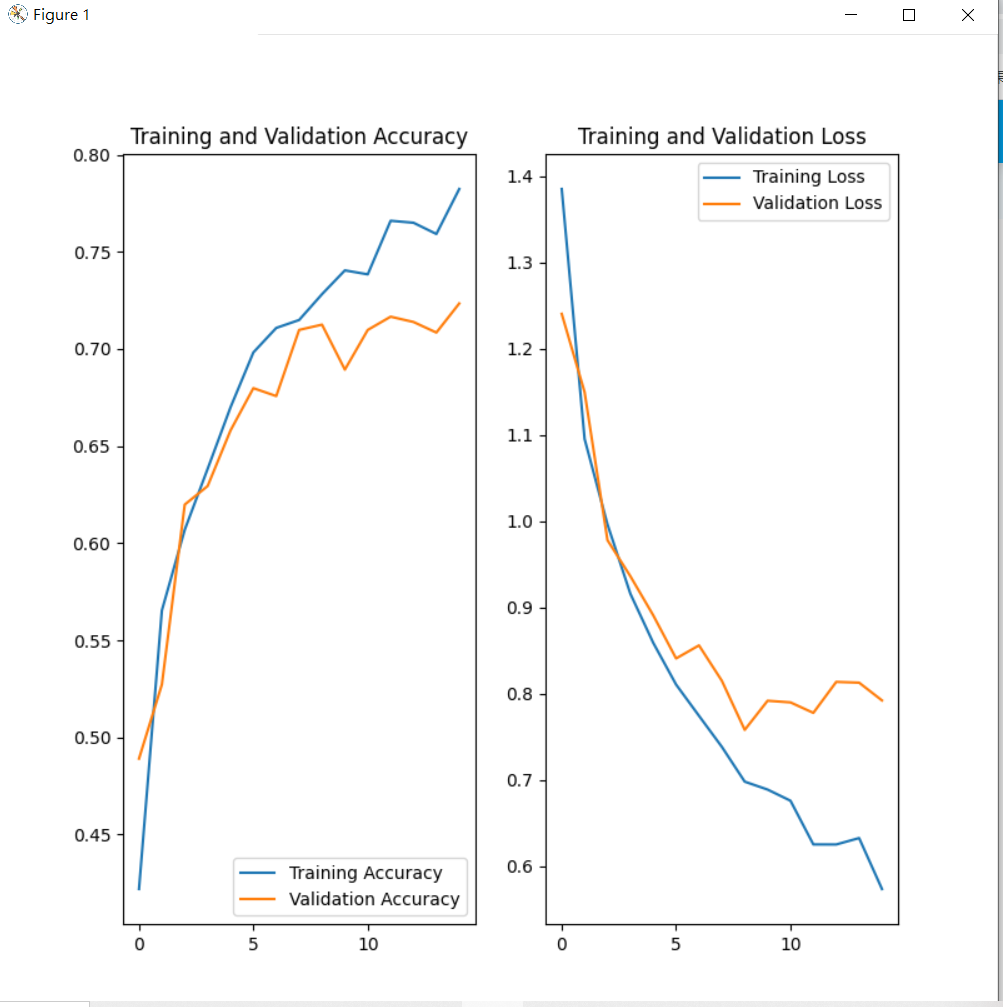
查看訓練結果:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
我們也可以使用官網提供的照片來進行預測,
可以發現由於模型一開始吃資料的時候有多了batch這個張量,所以用tf.expand_dims來增加維度:
sunflower_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg"
sunflower_path = tf.keras.utils.get_file('Red_sunflower', origin=sunflower_url)
img = keras.preprocessing.image.load_img(
sunflower_path, target_size=(img_height, img_width)
)
img_array = keras.preprocessing.image.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create a batch
predictions = model.predict(img_array)
score = tf.nn.softmax(predictions[0])
print(
"This image most likely belongs to {} with a {:.2f} percent confidence."
.format(class_names[np.argmax(score)], 100 * np.max(score))
)


