加工資料泛指各種處理資料的行為,這部分要一篇文章寫完真滴難,所以就也只能蜻蜓點水的各介紹一點,讓大家有個整體的概觀。
在啟動階段,目標當然是弄清楚需求,但也不只弄清楚需求而已,還需要確認「如何」達成需求,以及「是否有可能」達成需求。這時候建議找齊三類人才有辦法討論:
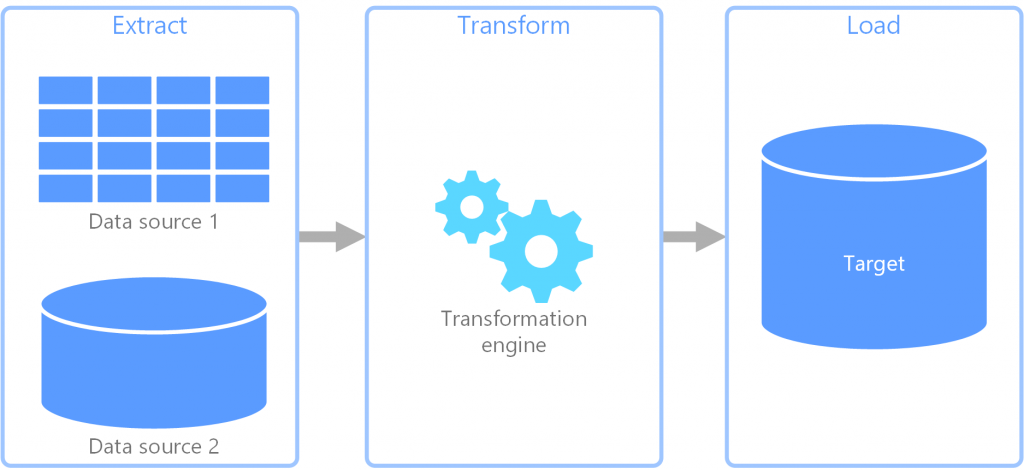
在設計階段,就需要資料工程師來將原始資料「轉換」成可以被後續利用的樣子。我們通常會透過「ETL」或「ELT」的方式來處理資料。
(https://docs.microsoft.com/zh-tw/azure/architecture/data-guide/)
以下提供幾個比較常見的設計模式:
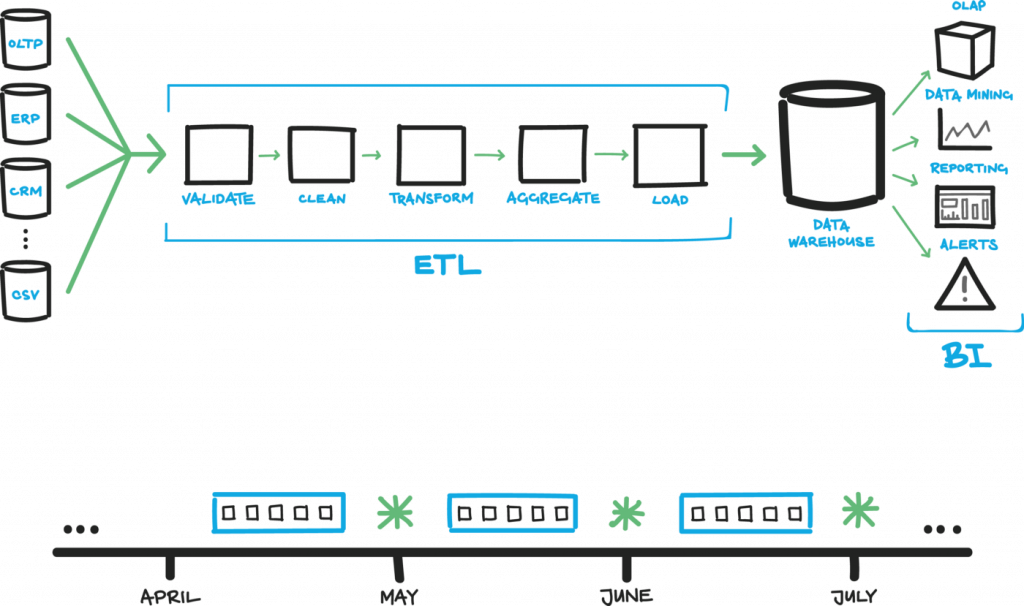
一般來說,資料在進入 Data Warehouse 前,都必須經過這幾個階段,才能供後續業務報表或是視覺化使用。算是基本起手式吧。
(http://letstalkhadoop.blogspot.com/)
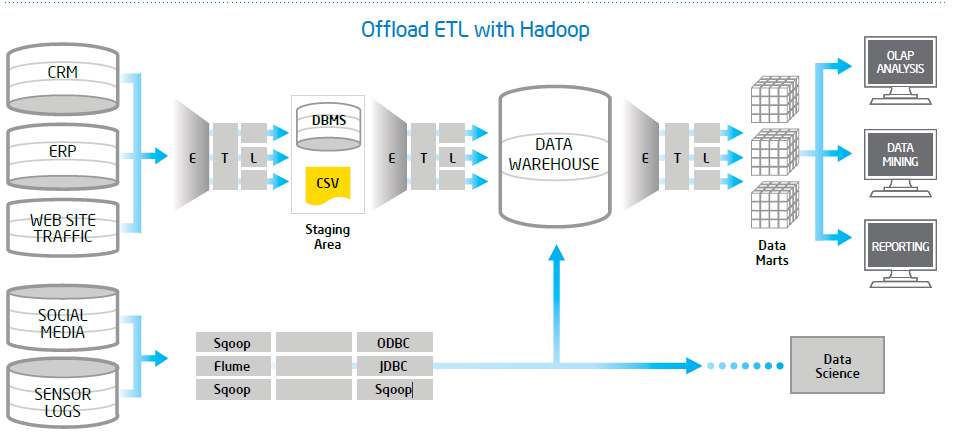
資料傳送到後端後,會經過 ETL 放到 Staging 環境、再透過 ETL 放到 DW、再透過 ETL 整理到了 Data Mart 給 End User 使用。當原始資料越複雜、資料量越多,中間就更需要多層次的處理來確保資料品質以及使用上的效能。
(https://www.slideshare.net/JulienSIMON5/serverless-architecture-with-aws-lambda-june-2016)
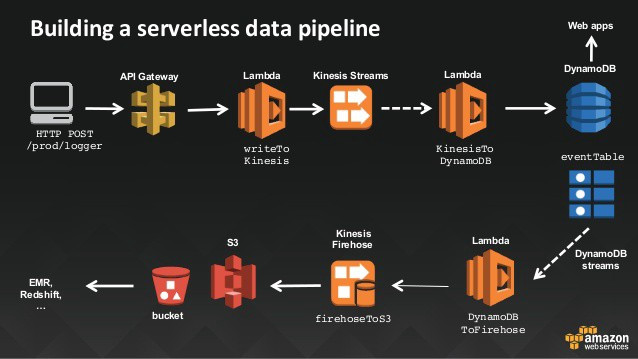
當然除了 Batch ETL 外,Streaming ETL 也是有的。可以根據事件、或是 mini batch 的方式來處理原始資料,配合 Batch Process 來處理累積的資料。
總之 ETL 是個很廣泛的領域,不僅僅是「資料處理」四個字而已。還需要考量到軟硬體架構、商務邏輯、後續的使用才能設計最適合的 ETL 流程。
跟任何一項開發一樣,在實作 Data Pipeline 之前,一定要先確認需求。而且因為資料有重力(Data Gravity),千萬不能只滿足當下需求,更要再多想一點點。
以下就提幾點在設計 Data Pipeline 架構時,通常需要考量的點:
這邊的延遲性是只說從收到資料到處理資料需要多久時間、可以容忍多久的延遲?這會影響到資料需要做即時處理還是批次處理?例如硬體系統的監控資料、或是線上使用者人數可能需要即時,或至少五分鐘內的資料。如果像是每天看的 BI 報表,需要等前一天的資料都收完才能計算的,處理頻次就是每天一次,相對來說也可以容忍比較大的延遲。
在計算資料時,需要到多精準?例如銀行的金額就沒有容許誤差的可能;但是像是線上即時使用者數、或是推文數就多少有誤差的空間。那另外像處理即時資料時,要求是「最少一次」還是「僅此一次」?對於資料先後順序有沒有特別要求?如果使用者每天需要 Aggregate 一次資料,那原始資料中每條資料的先後順序或許就沒有太大影響。
一般來說越接近資料源的「資料收集」系統,越注重高可用性。因為最源頭的資料一但掉了就GG了。必須讓原始資料儘早落地,才能安心做後續資料清洗或計算等開發。
系統能不能支援版本回滾?
資料處理邏輯有時候難免會更新,如果錯的話能不能快速回滾的之前的版本重跑資料?
紀錄任務進行時間
能不能量測每次的時間,如果有天處理時間異常增加能不能發送告警?
防止錯誤資料進入正式環境
資料處理有件有趣的事情是,即便程式邏輯正確,也不代表商業邏輯正確。通常一個新上線或是新修改後的資料處理程式,不會馬上將結果導入正式環境中以免污染當前的資料。如何透過環境設定切割來做到這件事,後面會有專文討論。
資源監控
能否簡單監控甚至預測所需資源?
易於開發/部署
開發 Data Pipeline 系統的人,和之後使用 Data Pipeline 建立任務的人可能是不同的兩群人(例如系統架構師開發系統、之後交由資料工程師建立任務)。那這套系統使用的語言能不能符合之後使用者主要的開發語言?或能不能允許其他語言來使用(例如 Python 或 Shell Script)。
自動化的維運工具
Data Pipeline 系統和其他任何軟體系統一樣都需要維運,越自動的維運機制以及越完整的自我修復功能,都能大大降低未來的負擔。