不同類型的資料產品在其各自專案週期有需要注意的地方,以下我們將說明在處理原始資料時,各階段應該做的事情
在初始階段,最重要的就是要了解搜集資料的需求。儘管我們很難知道這些資料未來還需要做哪些用途,但至少要把當下的需求弄清楚。我們可以把常見資料需求分為幾種類型:
紀錄資訊 - 這邊指的就是單純留存用的紀錄、像是 Log 訊息、系統資訊、Audit 資料,這些記錄會一直被寫入DB 或儲存裝置,寫下去之後也不太會修改。
分析建模 - 有些資料是為了分析用途,像是統計分析、市場調查,這些資料需要考量到分析和建模的方便,會盡量以「大表」的形式來搜集。
前端互動 - 像是大家在看的 Blog、或是電商網站等,需要將這些要呈現的資訊、以及跟使用者互動的資料存在後端資料庫,這些資料會根據使用者互動寫入或是被讀取,通常會將資料做正規化。
設計階段當然就是根據之前調查的用途,來決定資料的搜集方式。一般來說在設計上要考量幾點:
細節設計方式可以參考:The Art of Logging
關於調查的資料設計可以參考:Survey Data
資料正規化介紹:
https://en.wikipedia.org/wiki/Database_normalization
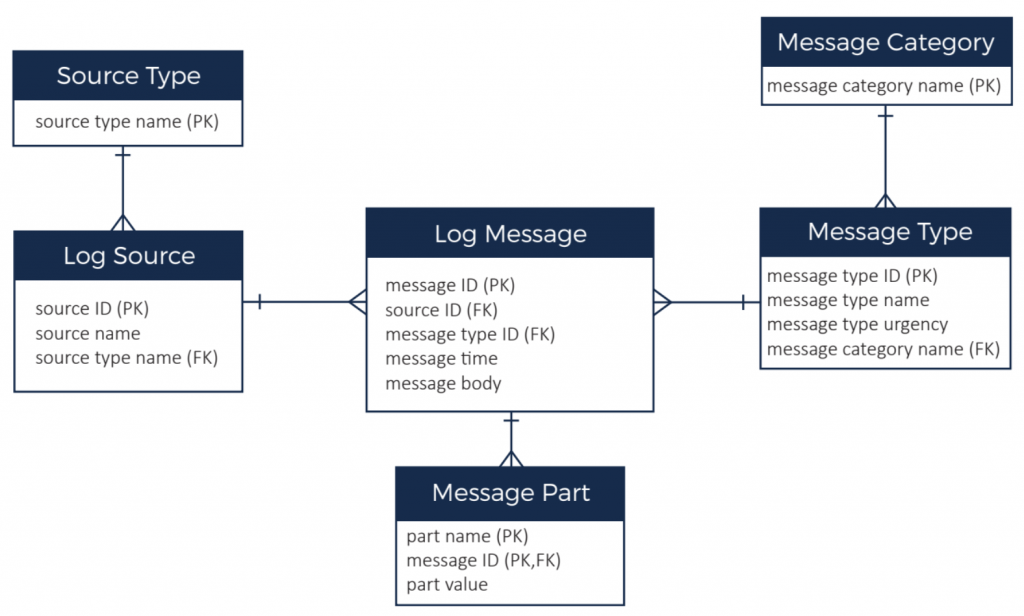
在設計階段,如果資料很複雜,最重要的事情就是需要整理 Data 之間的關聯,通常會用 Data Model 的方式來呈現。Data Model 的設計除了考量需求之外,也須要一併考量儲存方式和資料內容。
(https://www.instaclustr.com/cassandra-nosql-data-model-design-2/)
在開發階段要注意的事情倒不是很多。只要注意好設計規格,基本上用哪種語言來實作都差不多。
紀錄資訊:要注意需要在開發時設定好 Logger Level,這樣才能方便調整屆時程式輸出的資訊。Logging facility for Python
分析建模:如果是一次性的分析資料在開發時更要注意資料的正確性,沒有處理好就付之一炬了。
前端互動:在開發這種跟資料庫串接的後端程式時有非常多設計方式以及眉角需要注意,不是幾句話就寫得完了,這邊就真的只能給幾個關鍵字讓大家查詢,像是:
由於搜集資料的程式壞了就沒救了,部署搜集資料的程式時,需要嚴格的測試來避免資料丟失或髒資料進入,因此在部署之前「通常」會有嚴格的測試和 QA 機制。
這部分要測試的東西(針對資料的部分)包括幾點:
上線之後需要評估的東西基本除了資料規格、資料量、意外的狀況之外,也要特別評估資料是否能夠回答一開始在發想階段的商務需求,是不是有少收的或多收的情況出現。
在迭代階段當然就是根據之前的評估結果來做改善,這邊我們特別分為一次性的資料搜集以及持續性的資料搜集來介紹需要留意的地方:
如果是一次性的資料搜集,像是單次的調查、或是單次的活動,已經搜集的資料並不會影響新的資料時,在迭代上其實就可以放心的改善。
反之,如果像是 Log 蒐集、交易資料搜集、或是後端資料庫,過去的資料會延續到未來使用時,在迭代上就需要特別小心。例如我們在做資料分析的時候可能都會用到最近半年的資料,如果資料來源在第三個月有經歷改版,那就會影響到分析的狀況,而這個影響會持續三個月,一直到舊版本的資料不再被納入分析為止。或例如像下圖的狀況:在 v1 的時候我們會蒐集使用者的點擊資料。到了 v2 的時候可能因為前端 App 改版,造成點擊量突然提高,發現後緊急更新了 v 2.1 來修正這個異常。
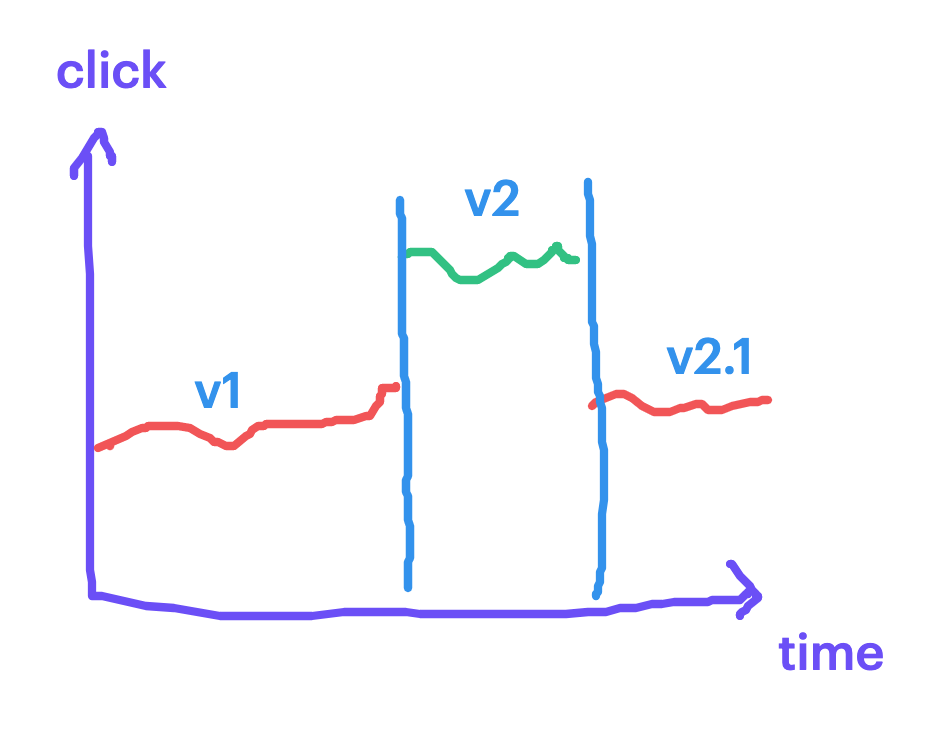
因此在持續性的資料蒐集時特別需要留意以下狀況:
https://www.codeproject.com/Articles/42354/The-Art-of-Logging