本篇章介紹經常發生在 Pinpline 上的潛在傷害 (Hazards) 以及針對各種 Case 所設立的解決機制。
Structural Hazards
在同一個 Clock Cycle 中,若 Pipeline 有兩個以上的指令需要使用同一個資源,便會產生 Structural Hazards 的問題。如此一來,後面的指令便會需要延後放入流水線,造成處理器無法在理想狀況下運行(一個 Cycle 處理一條指令)。
該情況又稱為流水線泡沫化。
為避免該狀況發生,在處理器設計階段時必須考慮設置兩個以上的 Data Unit 去處理指令以及資料的記憶體操作。或是將 Instruction 和 Data 的快取區隔開來。
Data Hazards
假設有兩個算數指令,分別是 ADD 和 SUB ,並且 SUB 的輸入資料是 ADD 的輸出資料。若 SUB 在執行時, ADD 處理的結果還沒有被寫回記憶體,便會造成 Data Hazards 。
細節可以參考 NCTU OCW 的 9:10 處。
若不希望兩個指令中間有太多的閒置週期,可以利用 Forwarding 的技術解決,請見下圖。
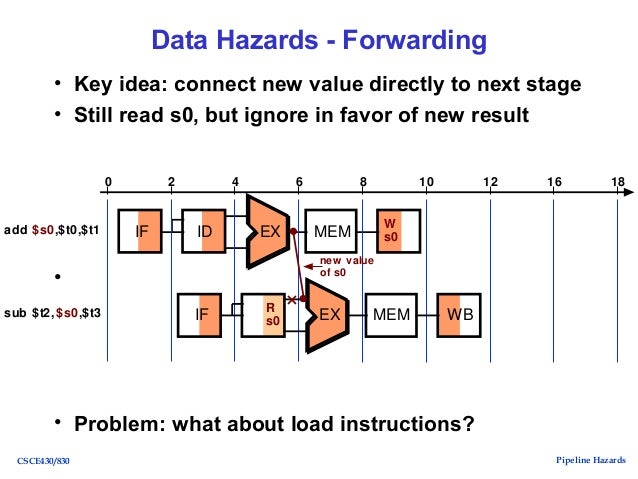
其主要概念是: 不等到第一個指令將結果寫回,直接在第一個指令完成 Execution 時將結果傳送給第二個指令的 Execution Input 。
圖片取自 slideshare 。
Fowarding 確實能夠解決上述的 Case ,不過仍然會遇到流水線泡沫化的情況產生,像是:
細節可以參考 NCTU OCW 的22:16 處。
因此,我們日常開發所使用的編譯器都會對程式語言做 Code Re-Ordering 減少流水線泡沫化的狀況產生,簡單的舉例如下:
若在 C 程式碼中有兩項加法操作:
int a = b + e;
int c = b + f;
若我們真的按照程式碼的邏輯工作,計算機會這樣處理我們的程式:
若這樣做,即使有 Forwarding 還是會在 2. 和 3. 之間以及 5. 和 6. 之間產生泡沫化的狀況。一共需要 13 個 Clock Cycle 才能完成。
詳細計算方式如下:
第一個指令需要等待完整的流水線週期: 5
之後每個指令需要等待一個週期: 6
一共產生了兩次泡沫化: 2
而聰明的編譯器會將我們的程式碼做編排優化:
在搭配 Forwarding 的前提下,我們就可以避免泡沫化的問題發生,加速程式碼的運作。
Control Hazards
Control hazards 發生在處理器被要求作條件分支時,做條件分支分析需等到條件需求被運算出來,才知道要執行的下一條指令位置,而在 pipeline 的處理過程中可以先利用 Branch prediction 猜測下一條指令。如果判斷錯誤會造成的暫存器資料改變,需要還原回來以及對 pipeline 做清空的操作,十分浪費效能。
Branch prediction 主要有兩類:
while, for 等 loop 通常都會重複執行一次以上。假設它一定會向後跳轉,只要在迴圈執行超過兩次的狀態下就能出現成效。為避免大家搞混前後的定義,特別補充一下。
向前跳轉的定義: 跳轉後指令的位置大於目前指令。
向後跳轉的定義: 跳轉後指令的位置小於目前指令,也就是往回跳。
BEQ 條件轉跳指令,動態分支預測會為 100 個 BEQ 指令個別建立歷史紀錄。這麼做的原因是: 不同的 BEQ 的比較條件不盡相同,若這 100 個指令都參照同一個歷史紀錄,會造成大量的錯誤預測,導致處理器需要反覆的清空流水線。由於現今的處理器多採用動態分支預測提高處理器的工作效率,本節就特別以飽和計數器為例,向大家介紹最簡單的動態預測策略。

圖片來源: Link 。
計數器一共有 4 個狀態機,其狀態分別是:
| MSB | LSB |
|---|---|
| 0 | 0 |
| 0 | 1 |
| 1 | 0 |
| 1 | 1 |
若 MSB == 0 不轉跳,
反之,若 MSB == 1 則轉跳。
這樣子做的好處是: 不會因為犯錯一次就改變想法,假設原本預測不轉跳,那必須要連續猜錯兩次才會改變想法。
如果設計者希望計數器猜錯更多次才改變想法,我們可以將計數器從二位元增加至三位元,甚至是更多位元。不過,一昧的增加位元不一定能帶來更好的性能。


 iThome鐵人賽
iThome鐵人賽