Kafka
簡單來說,我們可以稱後端和後端之間溝通的橋樑稱為Middleware,就如我們的Lab,API層與Data層溝通的橋樑,我們使用的是Kafka這種單向Queue的生產者消費者模型,而不是HTTP restful協議
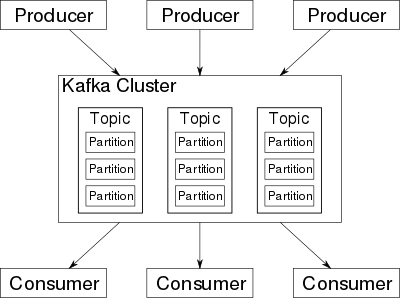
上圖架構圖取自維基百科,但是很好的說明了Kafka的整體架構,其中
Kafka Cluster:一個cluster有多個kafka server,Topic可以理解為是Kafka的一個table,是被多個server共享的,裡面的每個partition包含著有序資料,多個partition可以保證資料備份
Producer: 資料生產者,可以發送資料到指定的Topci,然後會把相同的資料發送到不同的Kafka server的partition中,也可以指定key,相同的key會在相同的partition裡
Consumer:資料消費者,指定一個Topic就可以監聽他並且消費,每一個Partition都是有順序的消費的,所以在同個partition下保證有順序,但是如果從更高角度的Kafka cluster就不保證了
看起來有點類似HTTP中的UDP,資料送出去就不管了
Redis
Redis是一種NoSQL的key-value資料庫,與其他資料庫不同的地方是,他是存在記憶體的,所以他每秒讀寫的次數非常快,適合用來存放需要經常讀寫的小數據,在應用上,經常拿來當作Cache的伺服器,他甚至還支持Cluster、分散式、主從同步,可以無限擴增
在我們的Lab中,Redis主要用來存放Object的Metadata,裡面存放的資料例如size、name、version等經常會被用到
由於Redis為了追求高性能,雖然他是用類似json的key-value去存放資料,但他不能無限巢狀式的在json的value再指定一個json

