相較於資料湖,另一個更常見的大數據儲存系統是 — 資料倉儲。和資料湖一樣,資料倉儲也用來儲存巨量資料,但一個明顯的區別是,它是儲存傳統常見的結構化資料,像是表格、資料庫。資料倉儲的發展比資料湖更成熟,因為結構化資料是更容易被處理與分析的資料結構,它像是資料庫的延伸,可以是來自一個或多個不同資料源的整合中央儲存庫;橫跨更大的時間系統,將歷史與當前資料儲存在一起,提供不同價值的資訊。
AWS中的資料倉儲分析服務是Amazon Redshift,它使用ANSI SQL查詢資料並可搭配標準 JDBC 和 ODBC 驅動程式存取;其後可整合其他BI工具來產出動態報表或視覺化儀表板等。
Redshift全託管服務支持的資料量可達PB等級,不僅部屬快且可擴展;它能夠如此快速的查找巨量資料並執行複雜的SQL運算是因為底層引擎應用了機器學習、平行處理與直欄式儲存*技術。
進入Redshift服務頁面(目前沒有繁體中文)可以看到當前叢集狀態,類似Hadoop3的9870埠號作用。直接點選橘色「建立叢集」鍵,或是從左側工具欄由叢集cluster分頁進入建立頁面。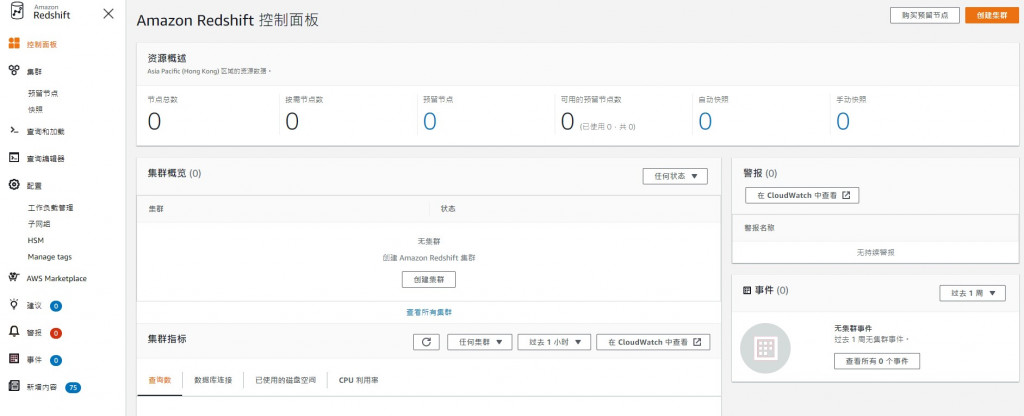
依據使用需求選擇對應的節點類型,預設帶入的RA3類型是分離運算和儲存節點,分開節點的好處是可以分開計價。要注意的是DS2類型在今年底(2021)將退役,已無法建立,在手冊上都有其他替代類型建議,RA3在IOPS和低延遲*上都有更佳的表現。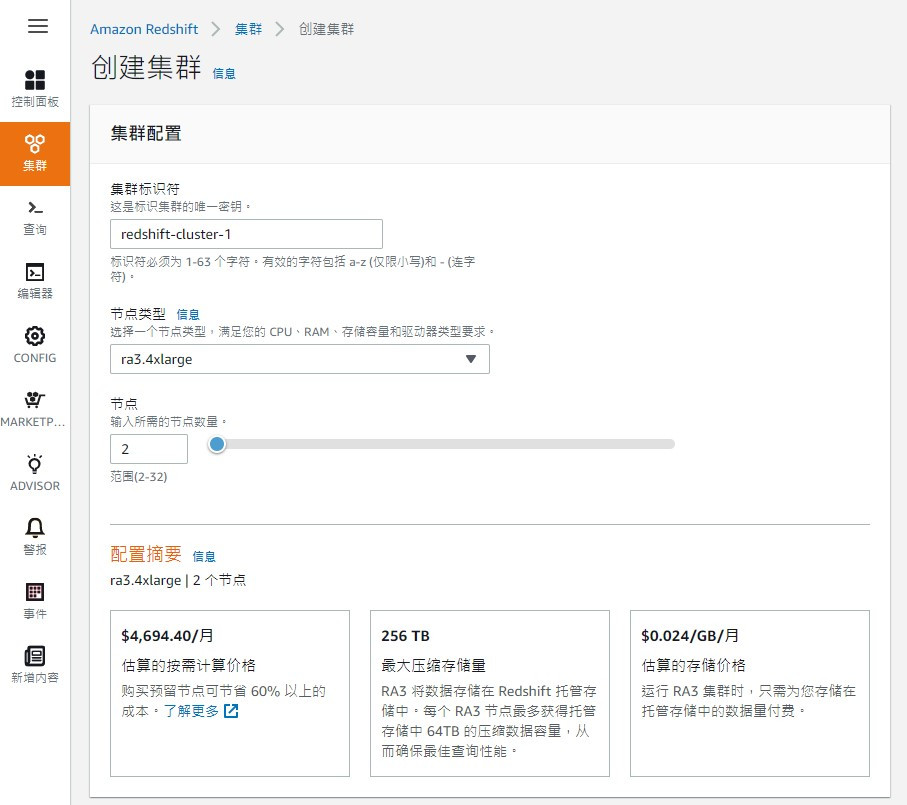
建立節點時如果基本配置不使用預設值,記得先到config分頁建立對應Subnet Group 再回來建立 cluster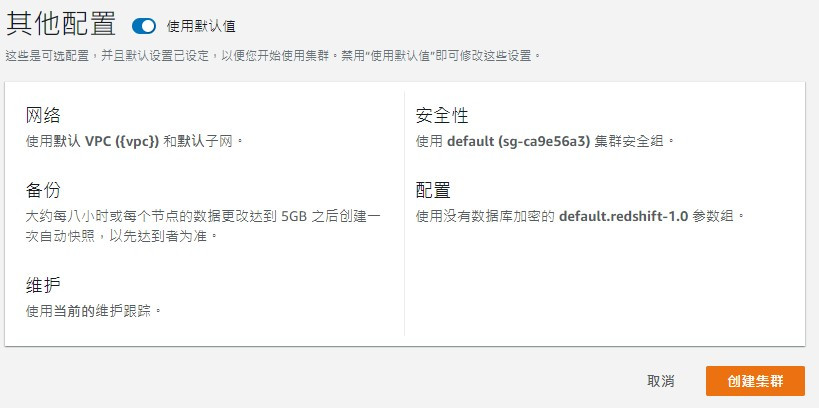
備份與還原方面,Redshift在導入資料時會複製所有資料並持續備份到S3,所以它會持續備份並維護到至少三份資料 (原始資料和複本,以及S3 的備份)。叢集方面,Redshift預設會自動備份並保留一天,最長可設定為 35 天。
當叢集建立完成並導入資料後,可直接在左側工具欄的編輯器分頁下SQL,查詢結果會直接出現在下方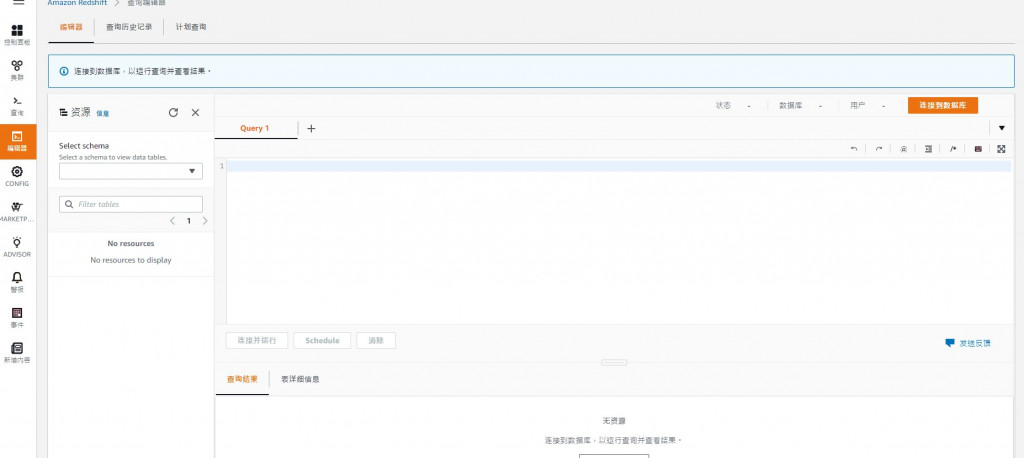
值得一提的功能是工作負載管理(WLM, Workload Management),它可以自動或手動定義要優先處理的查詢,可以在不增加節點的條件下增加處理的查詢量。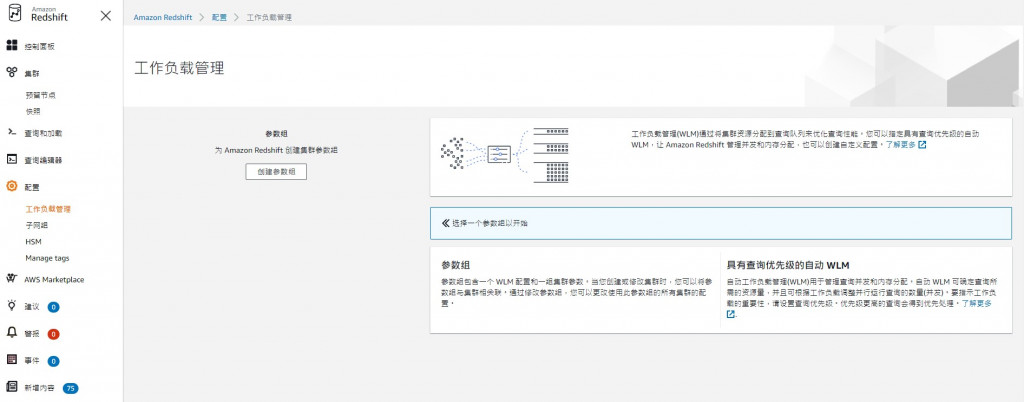
*直欄式儲存 Columnar / Column-oriented
( https://zh.wikipedia.org/wiki/%E5%88%97%E5%BC%8F%E6%95%B0%E6%8D%AE%E5%BA%93 )
*RA3( https://aws.amazon.com/tw/blogs/apn/amazon-redshift-benchmarking-comparison-of-ra3-vs-ds2-instance-types/ )


 iThome鐵人賽
iThome鐵人賽