在整理實驗結果之前,先來說說怎麼紀錄實驗~~
你484常常聽到以下對話
A: 哭啊,明天Meeting要報告的實驗記錄我都還沒整理。
B: 你都怎麼記錄呢?
A: 我都輸出成dataframe然後存在本地啊!
B: 那你要怎麼整理不同模型間的指標?
A: 用Excel...
但就在今天你遇見MLFlow後,
一切都會很美好 :D
他是一款開源的套件,可以幫助我們追蹤每次實驗的模型參數、模型指標和模型本人。
也可以叫出一個美麗的介面方便我們操作,像是做圖、查看模型架構等等。
pip install mlflow
有三個函數可以記錄:mlflow.log_param():記錄參數(batch_size, epochs 等等)mlflow.log_metric():記錄指標(accuracy, loss 等等)mlfow.log_artifact():記錄額外的東東(模型、訓練logs 等等)
import mlflow
epochs = 5
accuracy = [0.6, 0.7, 0.8, 0.9, 1.0]
model_architecture = " Input((None, 100))\n Dense(20)\n Dense(7)"
* # 記錄參數
mlflow.log_param('epochs', epochs)
# 記錄指標
for epoch in range(epochs):
mlflow.log_metric('accuracy', accuracy[epoch], step=epoch)
# 記錄加工品
mlfow.log_artifact(model_architecture)
在訓練模型之前加上一句
mlflow.tensorflow.autolog()
就可以自動記錄許多東西,
你想的到和想不到的都會記起來。我都用這招
https://www.mlflow.org/docs/latest/tracking.html#adding-tags-to-runs
mlruns資料夾中。
0資料夾代表實驗0
0資料夾底下有許多名字很亂的資料夾代表實驗0的run,run,例如:1ba8713ed81b422e92accaad547c67ab。run就是保存你所有記錄的地方。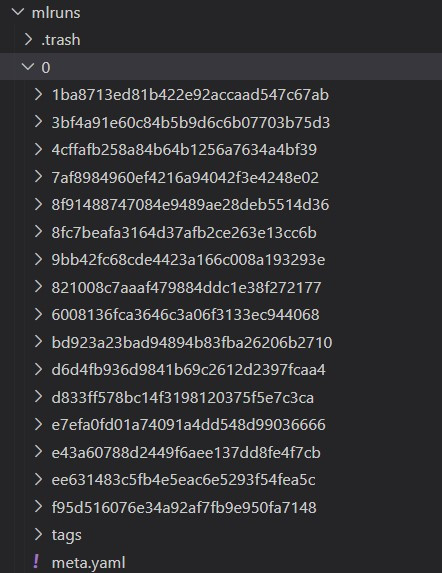

只要在與mlruns同層資料夾下輸入指令
mlflow ui
# Output:
INFO:waitress:Serving on http://127.0.0.1:5000
輸入 http://127.0.0.1:5000 就能打開 UI 。
左側欄位是實驗experiment欄位,你做的experiment會依照id排序。
(預設id為0,實驗名稱可自訂,我訂為Select architecture)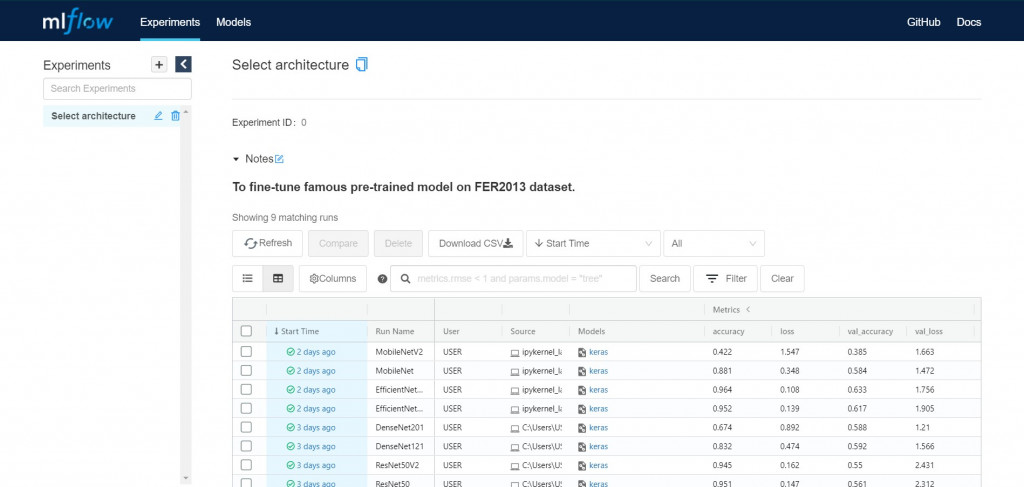
右下側可勾框代表runs,每一列代表一個run。
(這裡我讓它按照實驗起始時間排序)
勾選想要比較的runs,按下compare,就能比較兩個模型的記錄(前提是你有記錄)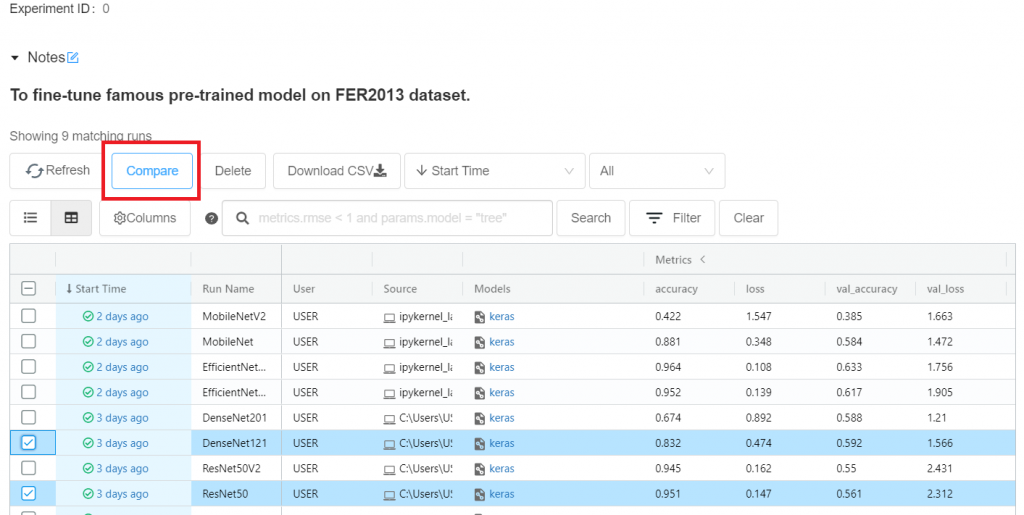
可以查看當初設的參數,也可以做出很棒的比較圖。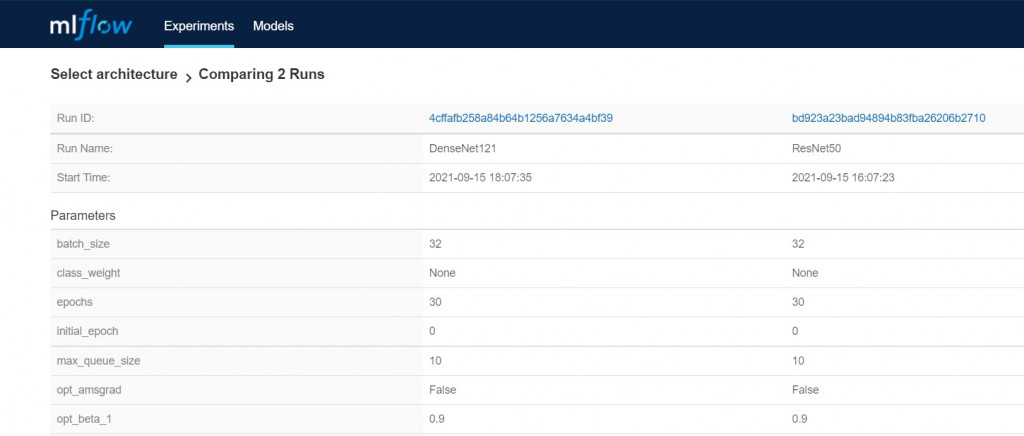
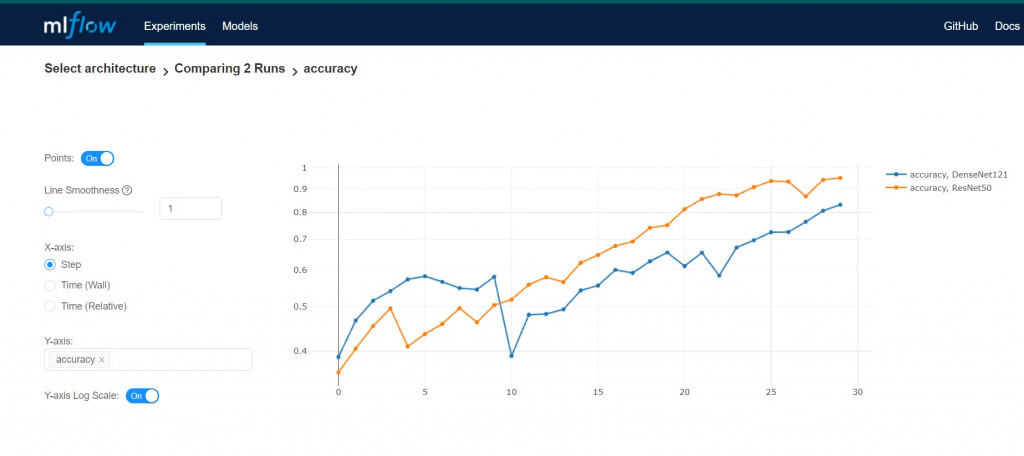
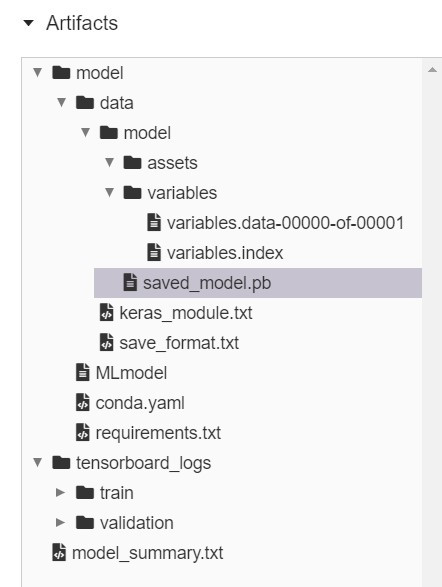
往下拉到Artifact的地方,可以看到儲存的data, model, summary等等。
所以MLFlow也可你幫你儲存模型。
才不會出現「啊!我跑了一整天的模型忘記存QQ」的慘況。