
| 模型 | 進度 |
|---|---|
| VGG Net | 完成 |
| ResNet | 完成 |
| DensNet | 完成 |
| MobileNet | 完成 |
| EfficientNet | 此篇 |
你遇過以下幾種困擾嗎?

在我初學神經網路的時候,
只會暴力地把模型加深,
然後期望梯度下降法幫我解決所有問題。
因為那時大家都在這麼做。
:喂喂 你能解決梯度消失的問題嗎?
:好像可耶
:太棒了! 我們再加深100層。
(ResNet-1001表示)
但是,Mingxing Tan 和 Quoc V. Le完全看不下去,
他們覺得現在大家瘋狂地加深網路根本拿石頭砸自己的腳,
就算Google研究團隊發表了一個1000萬層的網路,
然後說它有多好、多棒。
事實上,像你我一樣的小小研究員或是民間小公司,
根本就不可能有那樣的運算資源去訓練出跟Google一樣好的模型。
更別說他們有一堆我們拿不到的Data。
這是EfficientNetB0架構,是B0~B7中最小的: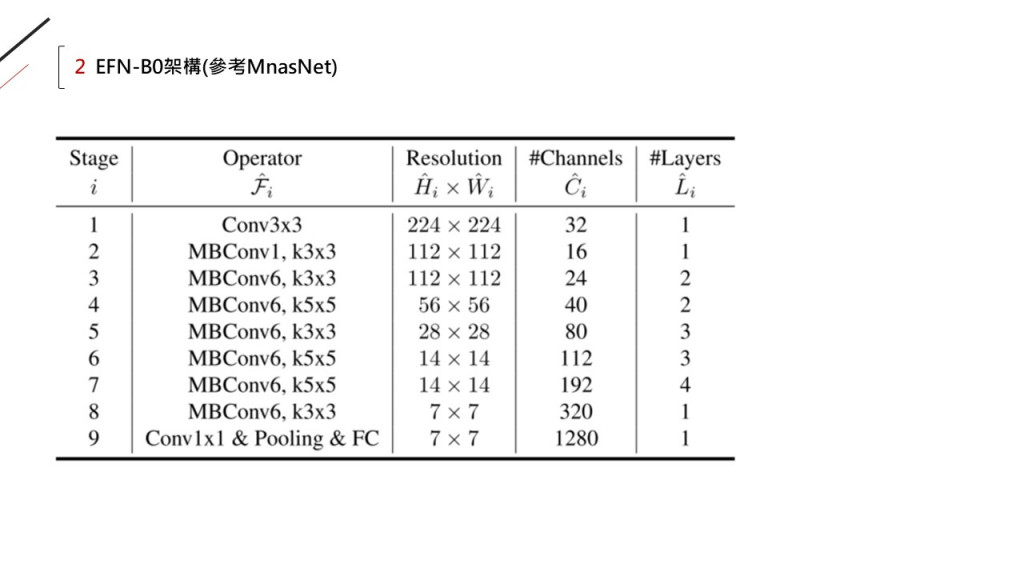
其中的MBConv6就是這個結構(如右圖):
"6"代表的是擴張通道數"6"倍。
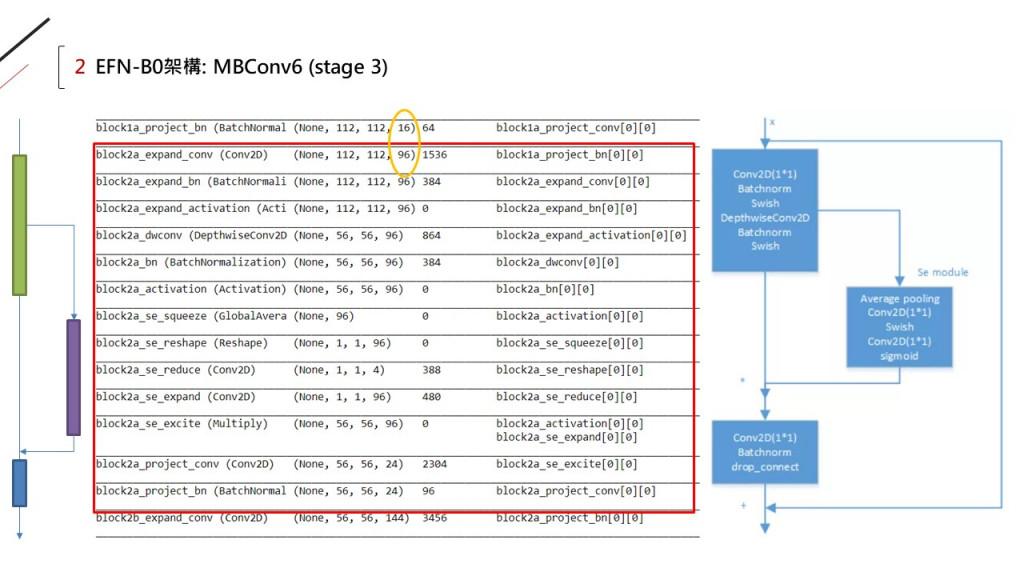
從MBConv的結構可以看出它參考了深度可分離卷積和直連通路的設計,
其實就是「M」o「B」ileNetV2的基礎架構啦:
有三種方向做模型縮放:
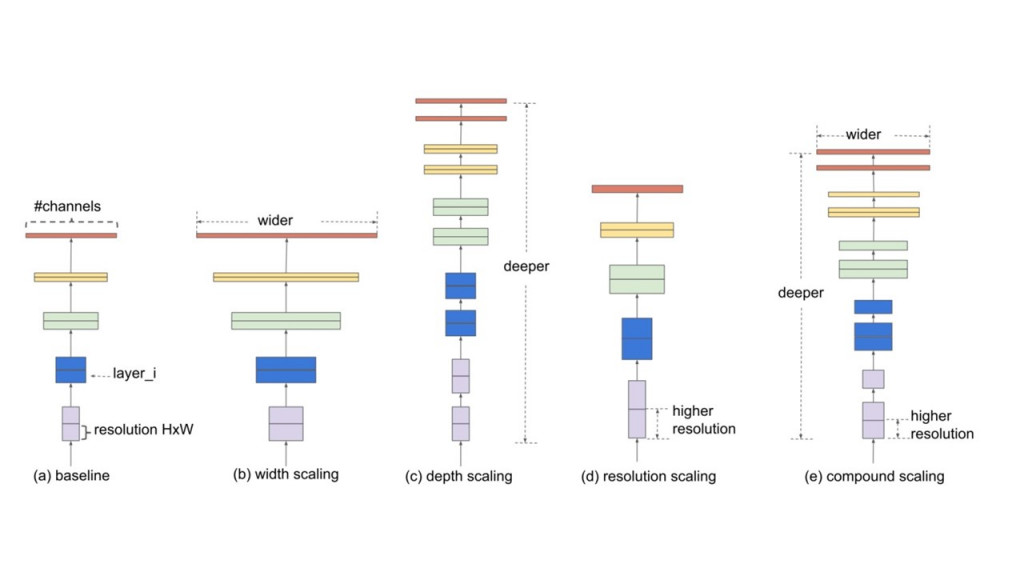
此論文提出一個方程式,
由4個參數組成:alpha, beta, gamma, phi,
分別代表depth, width, resolution和指數。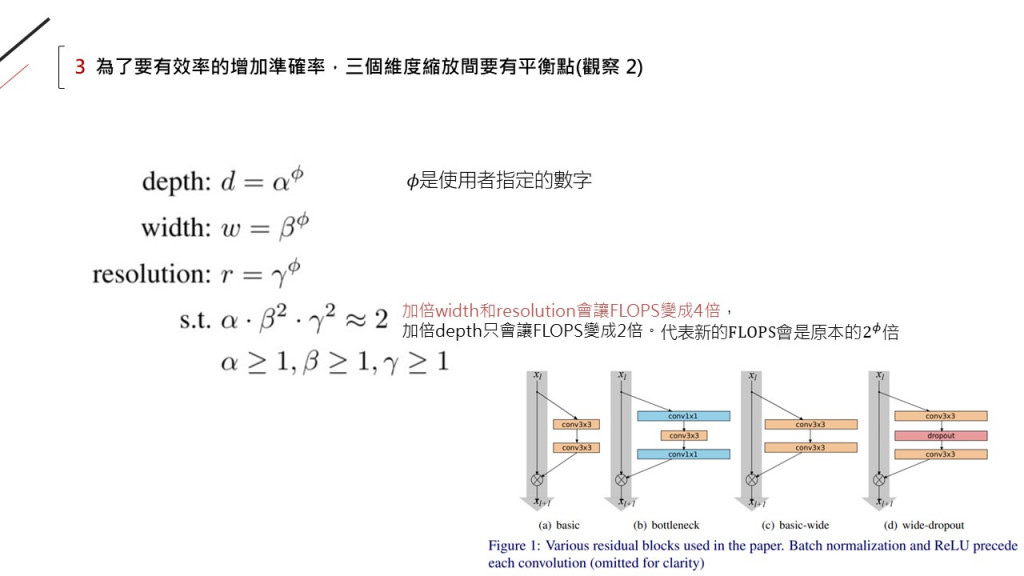
換句話說: 此方程式限制了三方向縮放的比例,
根據這個比例縮放的模型,
是最高效率的縮放方式!

OS:
限制縮放比例也蠻合理的,
假如寬度、深度和解析度分別代表人類的頭、身體和腳掌,
那我們從小長到大絕對不會只長大一個部位,
如果我們頭大身體小,那一定很不健康。
但是以前的模型真的就是在深度上往死裡加大 XD
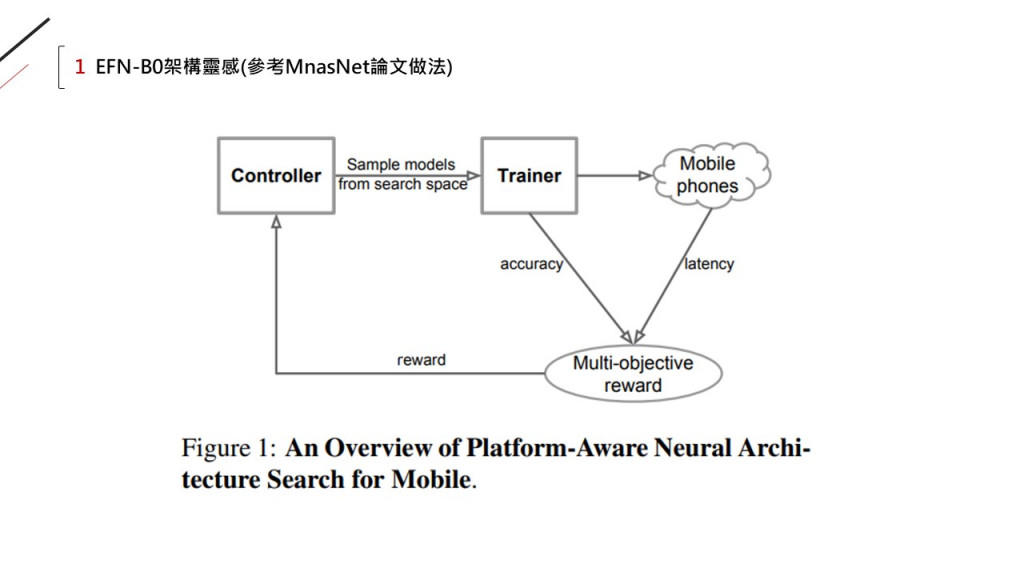
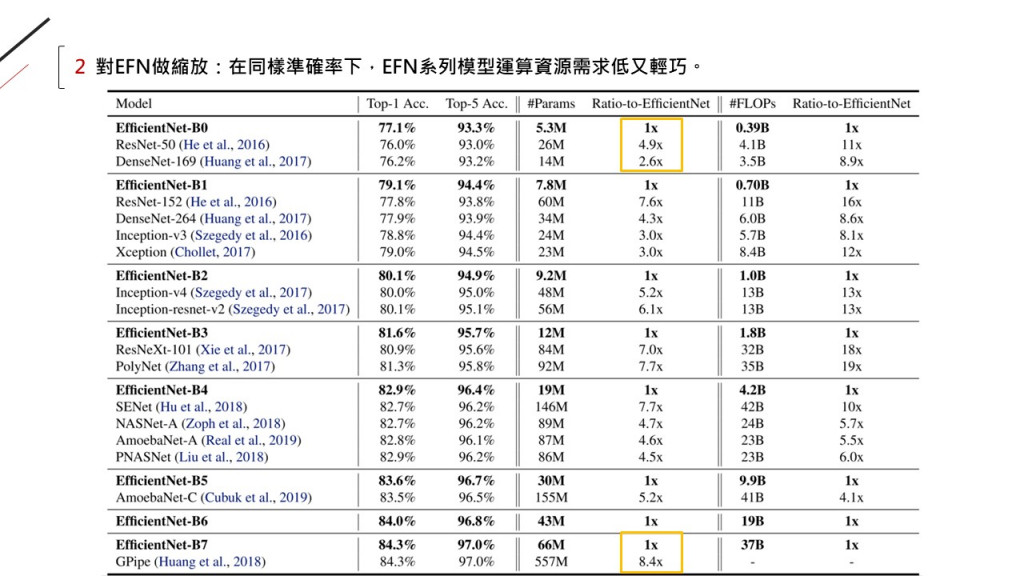
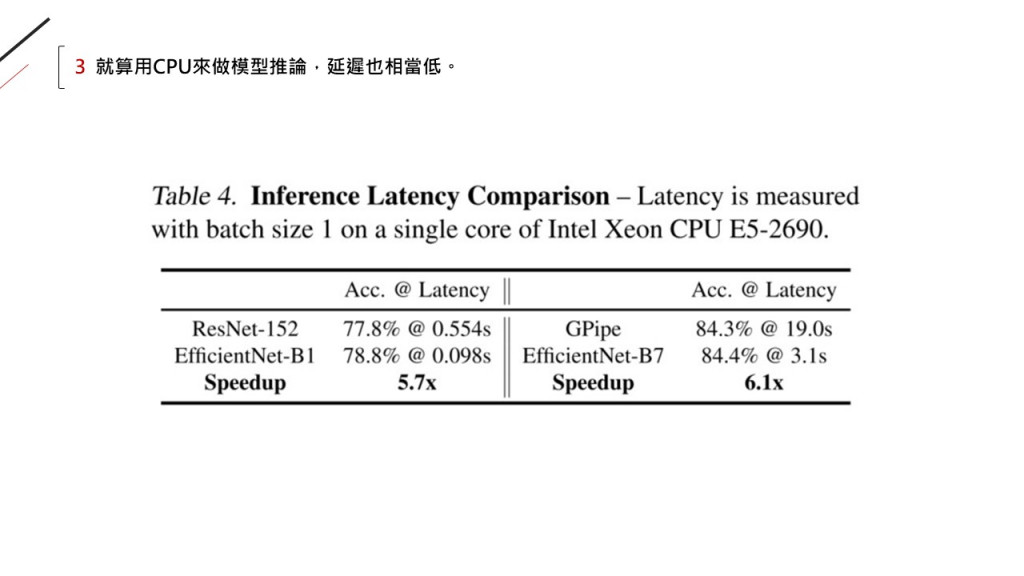
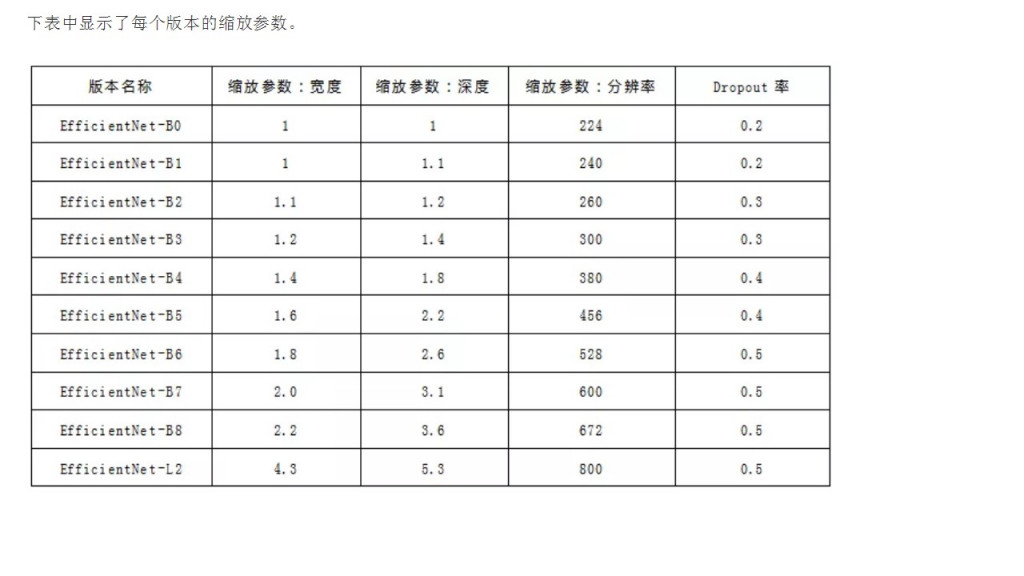
因為被拿來放大的模型(B0),
本身是在最佳化問題下用NAS找到的:

圖片來源:https://www.jianshu.com/p/5449ce4de7cc
