今日要介紹Node事件循環的概念,前面文章一直提到Node和JavaScipt雖然拖不了太大的關係,但其中與JavaScript的事件循環又有些不一樣。
在JavaScript是單線程,需要由異步加上回調的模式,來避免阻塞,而事件循環是在瀏覽器中實現的。在Node中也是單線程,但能支持高併發,就是靠事件循環,而事件循環是由底層的Libuv所實現。
下圖是Node事件循環流程圖: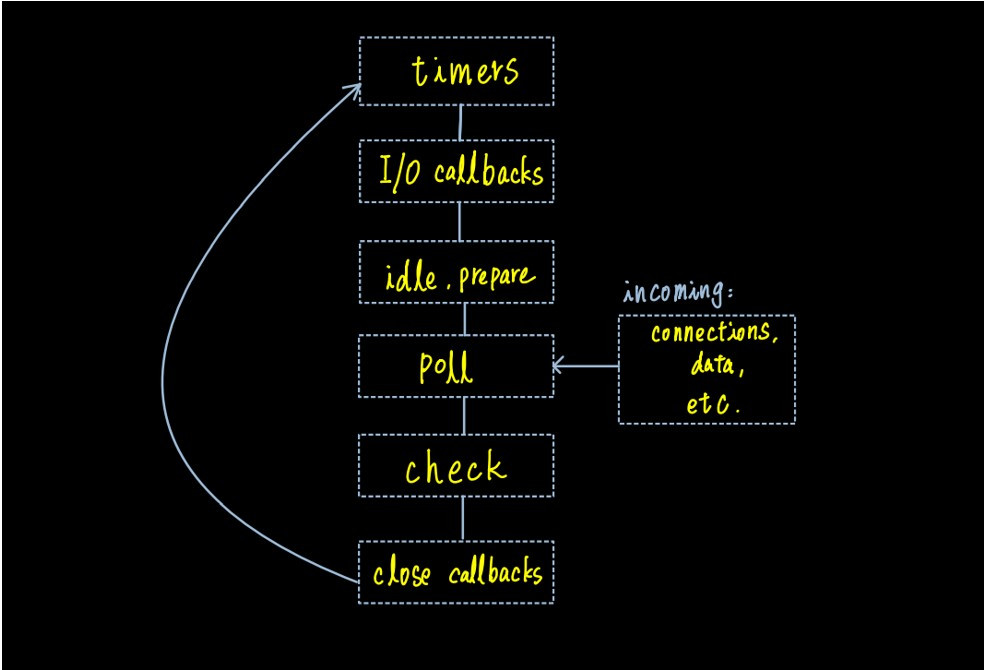
總共有六個不同階段,每個階段都有自己的回調函數,處理著不同的事件。
timers: 用來執行處理setTimeOut()、setInterval()的回調
I/O callbacks: 執行處理系統錯誤的回調。
poll: 不斷來回檢視是否有新的I/O事件發生,這裡也是也可能產生阻塞的階段。
idle,prepare: 僅於node內部使用,不須理會。
Check: 處理setImmediate() 的回調。
Close callbacks: c lose在此發出事件。
可參考官網資料,解釋得更詳細:
https://nodejs.org/en/docs/guides/event-loop-timers-and-nexttick/
充分了解後,實際操作例子:
//事件循環
var fs=require('fs');
var timeoutScheduled=Date.now();
setTimeout(function()
{
var delay=Date.now()-timeoutScheduled;
console.log('A total of '+delay+' seconds was wasted after execution!By Nicole!!');
},100);
fs.readFile('/path/to/file',function(err,data)
{
var startCallback=Date.now();
while (Date.now()-startCallback<10){//用while迴圈阻塞10毫秒
;//表示不做任何動作
}
});
程式碼改編官方網站與參考書 李鍇<新時期的Node.js入門>。
執行結果:
利用上面這段程式碼來解釋事件循環(配合Node事件循環流程圖)。
假設讀取文件需要95毫秒。
當開始執行事件循環後,timers階段到2000毫秒後才會發生,接著到poll階段,檢查有沒有新的事件,而目前尚未有新事件發生,因上面沒有定義setImmediate(),所以事件循環就一直在poll階段無法進入到check階段。
到了95毫秒後readFile讀取完畢後,產生新事件,而poll階段接收到後,事件循環開始執行回調函數,而readFile回調只是阻塞的了10毫秒。而總阻塞的時間是95+10=105(可能多一點也可能少一點),但都會大於100毫秒。
多執行幾次出來的秒數也不一定一樣,但都大於100毫秒。

可以做個小實驗修改上面的豪秒數,出來結果的時間都一定大於你設定的毫秒數。
補充:
上面一開始有提到Node的高併發,有跟併發字面上很相似的並行,我在理解的時候,也容易混淆,下面以生活化的例子做解釋。
大家都有去買速食店的經驗吧!假設目前人手短缺,只有開放一個櫃台,現在分成兩排隊伍,
第一排是現場點餐的,第二排是拿餐的。那麼……
併發:為了兩排人的公平起見,第一排的一個人先前往櫃台點餐,完畢後,接著第二排的一個人在前往櫃台取餐!
也就是說櫃台一次要做兩件不同的事,要點餐又要取餐,而我兩排的隊伍皆有在移動(只是移動的速度極慢),可以想更簡單一點,就是壓榨櫃台員工要身兼多職,還要確保不同隊伍都有被處理。
並行:現在人手變多了!我再開放一個櫃台(現在共有兩個櫃台在運作),一個櫃台負責第一排,另一個櫃台負責第二排。如此一來,流動率就提高,效率就高了!
總結:
今天的事件循環感覺有點難,自己也理解了很久…,若有解釋得比較簡陋的部分或是有錯誤的部分,再請指點。
參考資料:
這部影片包含了JavaScript的事件循環介紹,個人覺得解說得很仔細。
https://www.youtube.com/watch?v=8aGhZQkoFbQ
Node官網事件循環解說:
https://nodejs.org/en/docs/guides/event-loop-timers-and-nexttick/
前輩您好:
想請問:
"假設讀取文件需要95毫秒。
當開始執行事件循環後,timers階段到2000毫秒後才會發生,接著到poll階段,檢查有沒有新的事件,而目前尚未有新事件發生,因上面沒有定義setImmediate(),所以事件循環就一直在poll階段無法進入到check階段。"
為什麼timer階段到2000毫秒後才會發生?(粗體部份),不是100毫秒? 謝謝您.


