可以先看看Autoencoders的構造,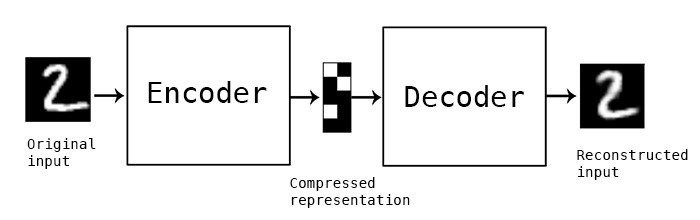
將原始的numpy array 或是tensor(可能是圖片、音樂或是一串數字特徵),
利用編碼器層轉換成降維的壓縮資訊,
再利用解碼器擴展成原來的維度。
參考頁面:
https://www.tensorflow.org/tutorials/generative/autoencoder?hl=zh_tw
官網的攻略主要有三個範例,
可以由第一個範例發現,通過了Autoencoders之後,
圖片會變得比較模糊。
而第二個範例是說明如何來使用Autoencoders去噪。
這裡是看到三個範例的用法,
利用心電圖資料集來建立區分正常的心電圖及異常的心電圖。
載入資料集,可以發現140的欄位為label,1代表正常的心電圖,
0代表異常,而前面欄位的特徵是由心電圖轉換而來的: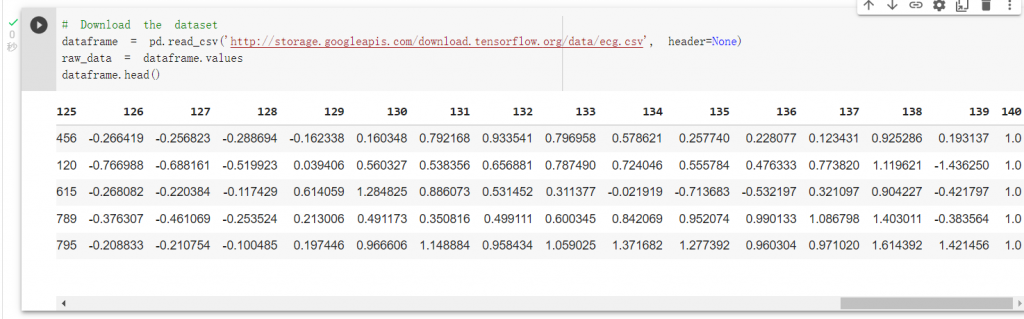
切分訓練集 及 測試集,以及各自的標籤:
將訓練集 及 測試集進行正規化,特徵都介於0-1之間:
我們之後只拿正常的心電圖來訓練,
所以重點在normal_train_data、normal_test_data那兩行:
我們可以先查看一張正常的心電圖: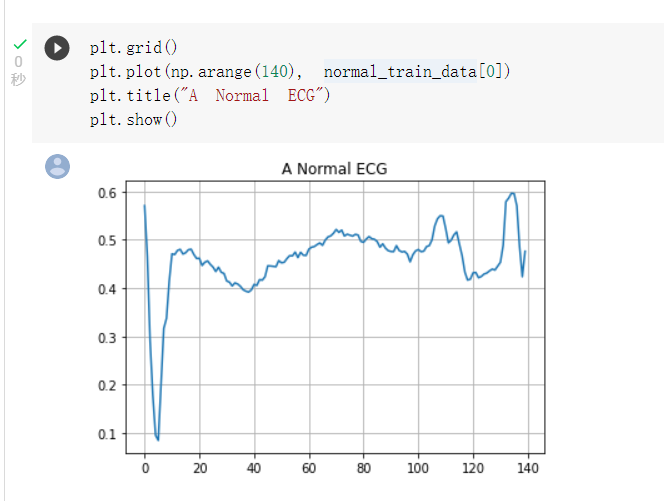
以及一張異常的心電圖: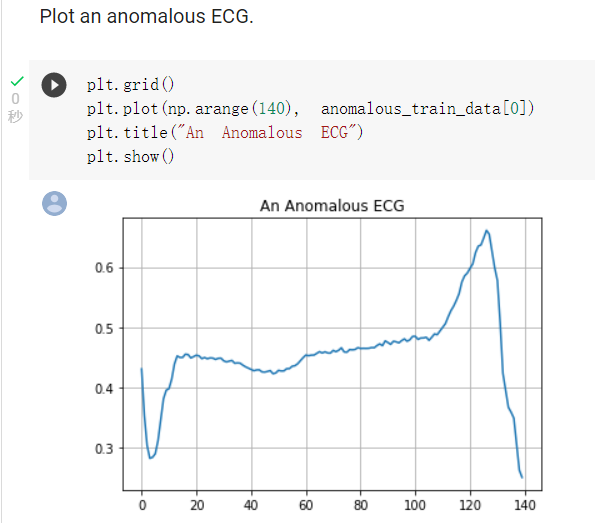
搭建 Autoencoders,
優化器用adam,損失函數用mae: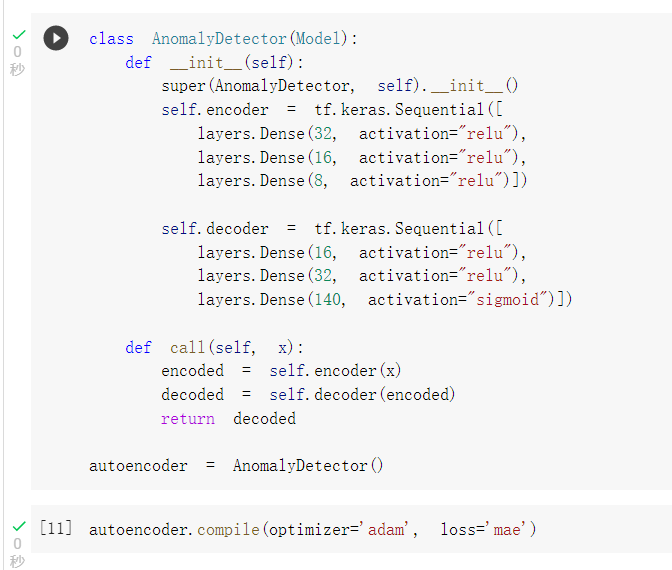
進行訓練: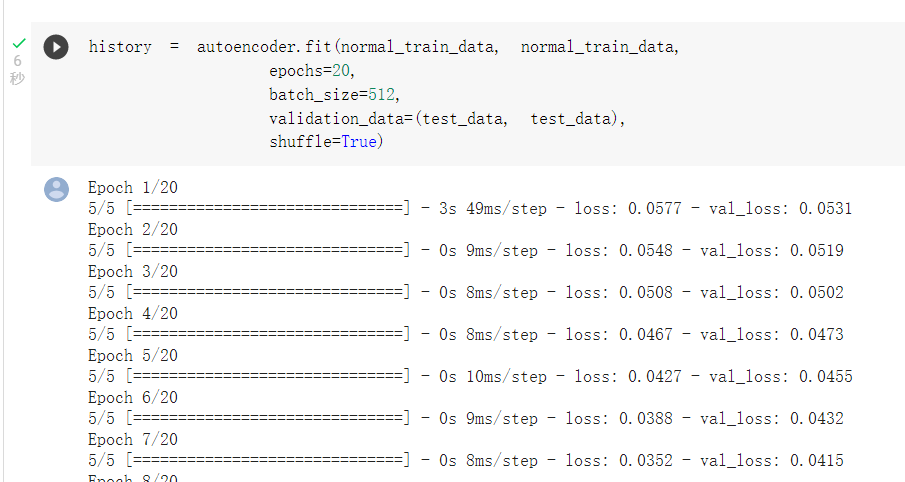
將損失函數作圖: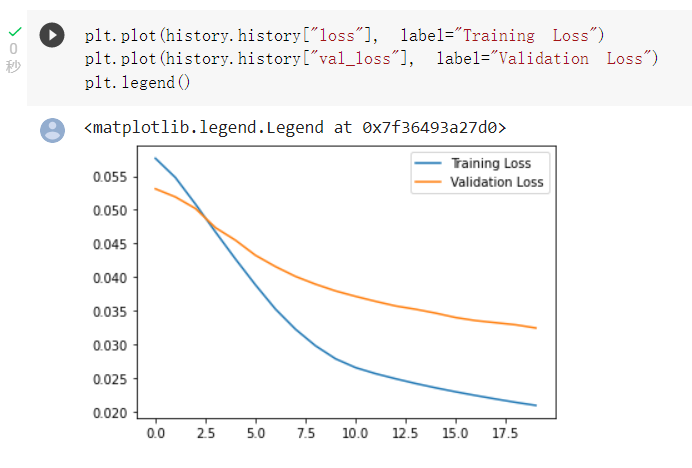
以預測值及正常心電圖的平均絕對誤差作圖: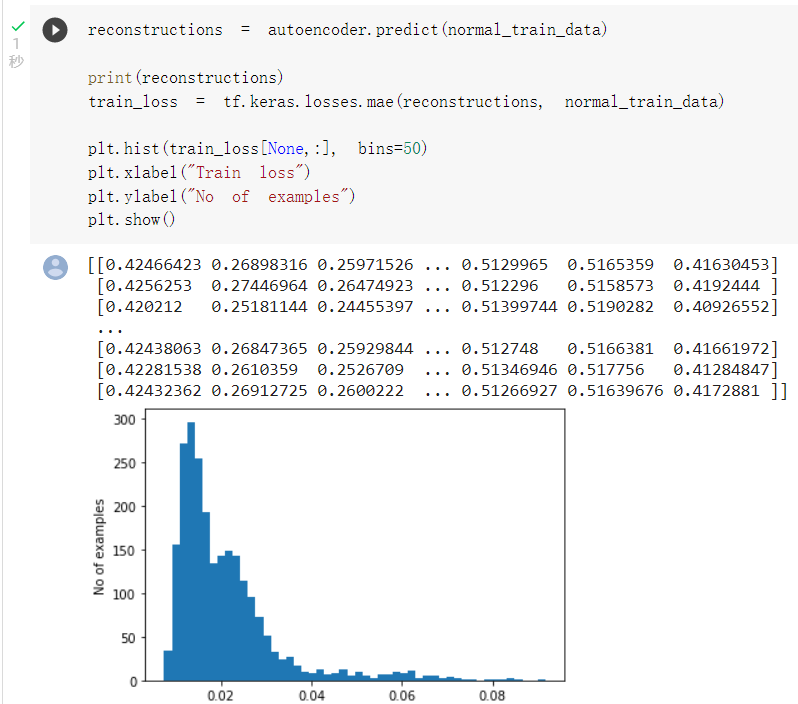
以平均絕對誤差的平均值加上平均絕對誤差的標準差當作判斷心電圖是否正常的閾值:
(選定標準可以自己建立,我是認為如果用p value說不定也可以用來建立判斷標準)
那我們可以預測心電圖是否異常:
查看模型準確度: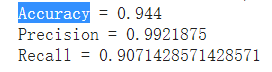
參考資料:
https://blog.keras.io/building-autoencoders-in-keras.html

