
走過了資料分析、演算法選擇後,
我們得知了有些可以改善模型的方向:
我用嘗試調整類別權重(class weight)解決資料不平衡的問題
但是在介紹學習率之前,
我想先解決一個經典的問題: over fitting
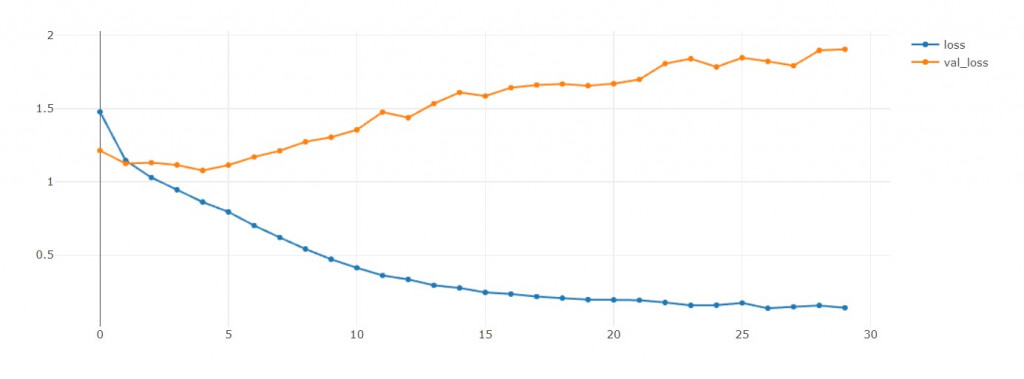
因為在EFN_base當中,
loss和val loss在訓練初期就開始往不同方向成長了,
我非常傷心
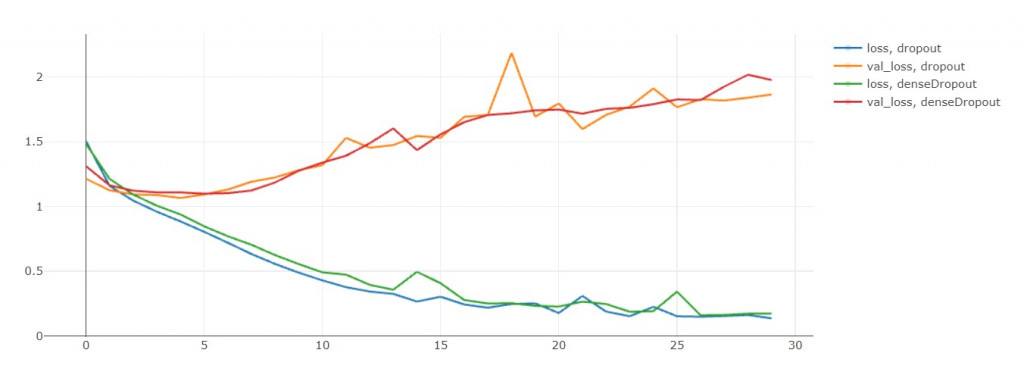
我根據EFN_base的結構,在不同層度上插入dropout layer。
先說一下甚麼是Global Max Pooling(GMP),
就是把每個feature map用最大值取代。
(從"面"變成"點",aka 降維)
假設我最後一層Conv layer有18個feature maps,
那經過GMP後,我就有一層長度為18的網路層。
簡單來說就是取代傳統Flatten + Dense layer的作法,
來大量地減少參數量,所以可以緩和過擬合問題。
因為GMP本身沒有參數,
所以我個人猜想...


一樣是訓練30輪,來看看誰能夠幫我解決EFN_base的過擬合問題
可以看出加上drop對於overfitting沒甚麼太大的幫助= =
訓練初期(第3輪開始)就val loss就和loss分道揚鑣了,
模型 | 訓練時長(秒) | acc | loss | val_acc | val_loss
------------- | ------------- | ------------- | -------------
EFN_drop | 2471 | 0.953(勝) | 0.136(勝) | 0.635(勝) | 1.865(勝)
EFN_densedrop | 2478 | 0.942 | 0.172 | 0.611 | 1.977
EFN_base | 2004 | 0.952 | 0.139 | 0.617 | 1.905
看來是EFN_drop在各方面輾壓般的勝利,
但這是一個警訊,
即使加了dropout也會過擬合的非常嚴重,
除了dropout之外,normalization也能減小過擬合問題。
未來我在訓練完整模型時,絕對會用到它!

 iThome鐵人賽
iThome鐵人賽