為什麼需要用到這兩個東西呢?
因為我們在訓練資料時
如果每次輸入的資料都是一整個一樣的資料,表示每次微分的結果都會一模一樣
只是一直往同一個方向做梯度下降,這樣的訓練結果並不理想,而且可能也會遇上Local Minima跳不出來
如果我們能每次都是從一整群資料裡取出不同群來做微分,這樣每次計算的結果都不一樣
這樣更有利於我們訓練資料,DataLoader即能為我們做到此效果
這裡我會用鳶尾花資料集來做操作示範
載入資料集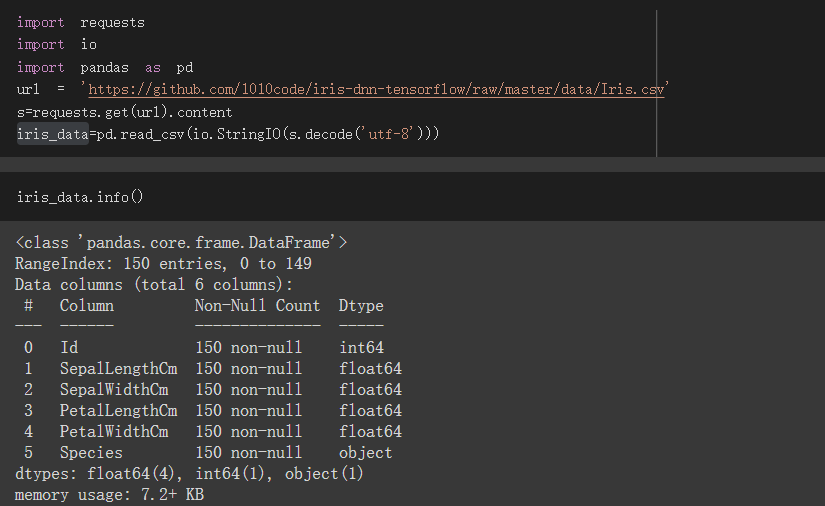
id 只是資料編號,等一下不會拿來用
SepalLengthCm、SepalWidthCm、PetalLengthCm、PetalWidthCm為特徵值
Species為訓練目標
資料轉為np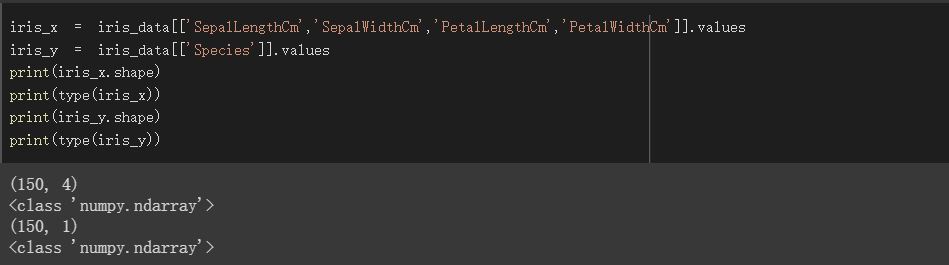
分別將特徵欄位及訓練目標欄位透過屬性values得到numpy形式的值
import Dataset、DataLoader
from torch.utils.data import Dataset,DataLoader
設置Dataset
在__init__後方傳入x(特徵值)、y(訓練目標)
設置self.x(特徵值), self.y(訓練目標), self.n_sample(資料個數)這三種屬性
__getitem__需有index參數,最後__len__就是回傳資料個數
dataset設置完後傳入剛剛的資料train_set = dataset(iris_x,iris_y)
設置DataLoader
將剛剛設置好的train_set傳入DataLoader後方dataset參數
batch_size設置每次要一起處理幾筆資料
shuffle為Ture會不規則的取出資料,可使每次微分結果不同,要訓練資料時都會設為Ture
DataLoaer為一種迭代物件,根據我們設置的batch_size會決定它的長度
上面範例我設batch_size為20,而我們種共有150筆資料
所以DataLoader的長度為8
因150/20取整數為7,餘數10,剩下的10筆資料也須成為1組,7+1為八組
設n_batch為dataloader的長度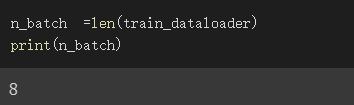
Dataset、DataLoader就寫到這裡
明天我會以iris資料集為範例寫出一個完整的訓練過程,
送上colab連結,可自行在上面多做點練習更加熟悉pytorch
https://colab.research.google.com/drive/1yBz68LIIYFQEZNHDjHeBvyEVsDR8ulTQ?usp=sharing


 iThome鐵人賽
iThome鐵人賽