KNN簡單說明
為一種監督學習的方法,其原理就好像物以類聚一樣,相同的東西會聚在一起
我們可以設定一個參數叫n_neighbors,假如我今天填入的數字是3
它就會將我的資料依據周圍3個最近的資料來作分類
舉例說明:
今天我們要將資料做分類,分為紅色圈圈或黃色圈圈
圖中的黑色圈圈為未分類資料,而我將n_neighbors設為3
所以它會觀察離它最近的的三個點,為一個黃色圈圈、兩個紅色圈圈
因為紅色圈圈比較多,所以它被分為了紅色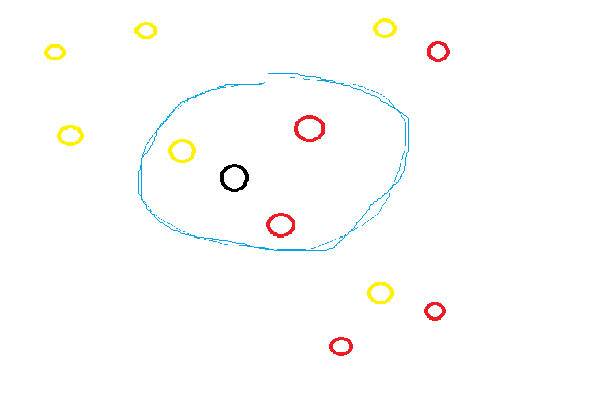
這樣說起來,你可能會問KNN是在train什麼?不就是依據原本資料的分布狀況來做分類嗎?
是的!沒錯~也就只是根據有label的資料分布來計算沒有label的資料該麼分群而已
所以它沒有實際train這個動作,只是對數據做一些運算
使用方法
這邊我使用的資料集為Titanic
前處理我直接跟Day24、25、26的一樣,如果想了解可以去看前面的文章
import KNN
Classifier:
from sklearn.neighbors import KNeighborsClassifier
Regression:
from sklearn.neighbors import KNeighborsRegressor
自己先設一個變數,此變數為你的model名稱,並將KNeighborsClassifier()指派給它
訓練model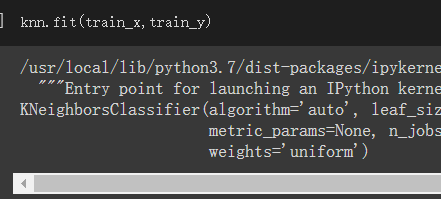
查看訓練結果的成績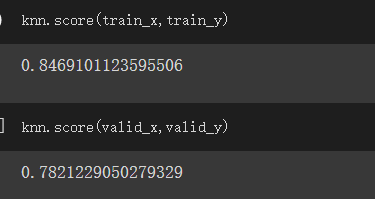
使用model預測結果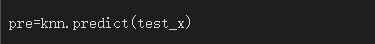
繳交結果
IT_submission 為DNN的訓練結果(前面文章有寫)
SVM_submission 為SVM的訓練結果(前面文章有寫)
KNN_submission 為KNN的訓練結果 (就是本文章的結果)
Kmeans_submission 為Kmeans的訓練結果(後面文章會寫)
此全部都用相同的資料前處理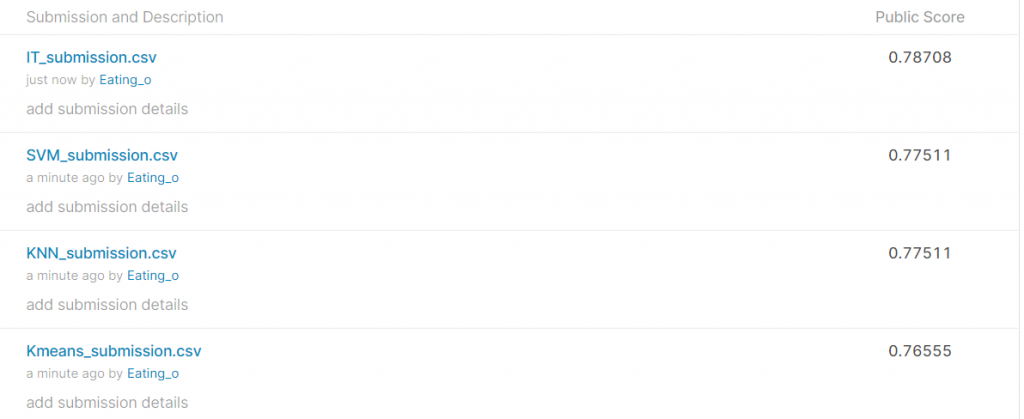
附上程式碼,程式碼我有分過目錄,你可以直接跳到KNN
https://colab.research.google.com/drive/16jTbu8jIDWEaast4eMPRKUBLlUBOLffT?usp=sharing
你可能會想說:靠!這不是跟昨天講的SVM使用方法根本一模一樣
對,就是一模一樣,我也差不多彈盡糧絕了,不知道要說什麼


 iThome鐵人賽
iThome鐵人賽