
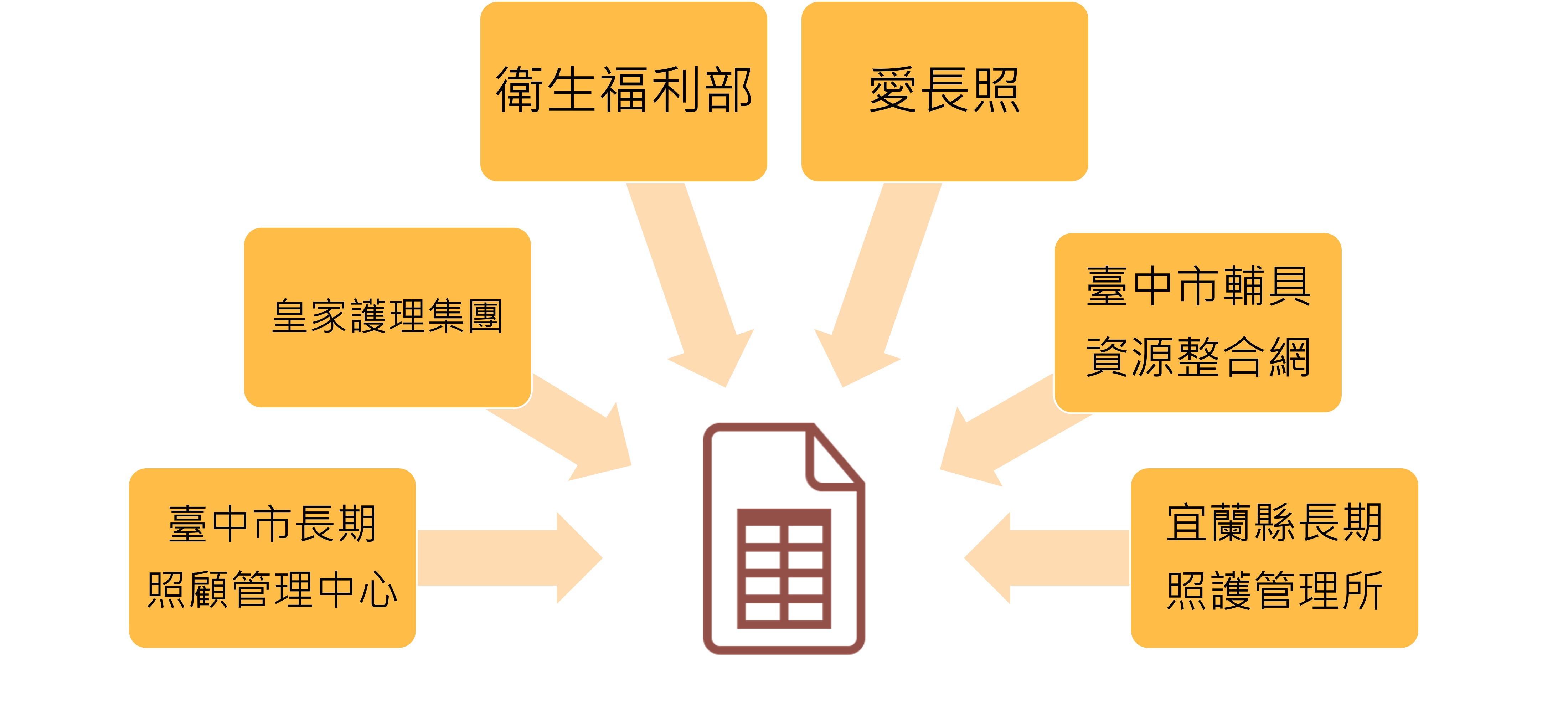
撰寫 Python 程式碼蒐集網路上的長照相關問答資訊,相比使用人工蒐集的方式,程式自動化蒐集方便又快速,也比較不會有缺漏。本研究將程式蒐集到的資料彙整成 CSV 格式,問答集來源包括:愛長照(愛長照編輯團隊,2017)、臺中市長期照顧管理中心(臺中市長期照顧管理中心,2020)、皇家護理集團(皇家護理集團,2019)、臺中市輔具資源整合網(臺中市輔具資源整合網,2015)、衛生福利部(衛生福利部,2017、2020)、宜蘭縣長期照護管理所(宜蘭縣長期照護管理所,2019),共六個來源。
如果不想在自己電腦安裝 Pytnon 環境,或裝一些有的沒的套件,很推薦使用 Google 提供的 Colab。我真的覺得這個工具是佛心來著,可以免費使用 Google 的 GPU、TPU。程式又可以分段執行,也很適合用來 debug。
不過我用 Colab 的最大原因是,因為爬蟲的過程會需要大量發送請求(request),我很怕實驗室 IP 被學校計中或衛福部 ban 掉。
進入正題!
今天選擇爬衛福部的資料做為範例,完整的程式碼可以參考: https://github.com/dreambo4/MOHW-QandA
首先載入等下要用的 Library
from bs4 import BeautifulSoup
import requests
import csv
今天的目標是: https://1966.gov.tw/LTC/np-3972-201.html
我們要取得這 7 個分類裡的所有 Q&A。因為只有 7 個分類,所以我只讓程式從每個分類的第一頁開始爬,而不是列出所有分類的這頁。也就是說,以下的這個動作要做 7 次。
可以發現網址的前半段都是相同的,因此 7 個 URL 可以寫成
baseUrl = "https://1966.gov.tw/LTC/"
url = baseUrl + "lp-3977-201.html"
主要的程式是這樣的
qaList = []
while True:
soup = getContent(url)
questions = soup.find("div", class_="List").find_all("a")
for q in questions:
qa = {}
answerUrl = q.get("href")
qa['url'] = answerUrl
qa['q'] = q.get("title")
qa['a'] = getAnswer(answerUrl)
print(qa)
qaList.append(qa)
nextPageUrl = getNextPage(soup)
if nextPageUrl is False:
break
url = baseUrl + nextPageUrl
首先 getContent() 取得該頁的完整內容。找到網頁中的內容,我們要的就是這個 class="List" 的 div,並取得所有的 <a></a>,當中有我們需要的問題列表。
在 BeautifulSoup,要取得 Html tag 有兩種方式: find、find_all,並且可以搭配使用
- find: 取得第一個標籤
- fing_all: 取得所有標籤
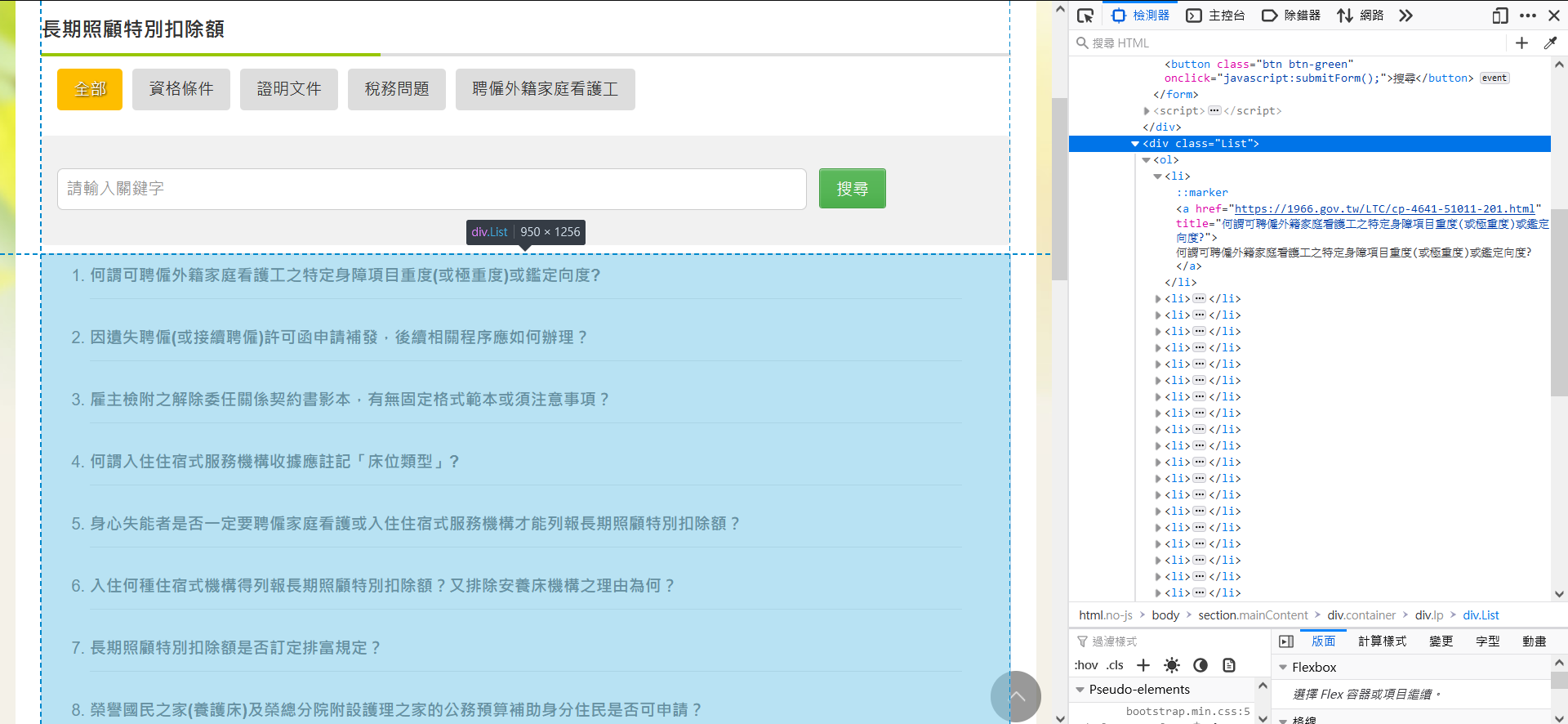
得到的問題列表(questions)大概會長這樣,此時把 href 拿出來,便等於取得答案頁的 URL。
[<a href="https://1966.gov.tw/LTC/cp-3977-42249-201.html" title="台灣的失智症長照服務資源量能?">台灣的失智症長照服務資源量能?</a>, <a href="https://1966.gov.tw/LTC/cp-3977-42248-201.html" title="「高齡政策白皮書」與「人口白皮書」,這兩者的關係為何?何者應優先適用?">「高齡政策白皮書」與「人口白皮書」,這兩者的關係為何?何者應優先適用?</a>, <a href="https://1966.gov.tw/LTC/cp-3977-42245-201.html" title="長照基金獎助之申請程序?">長照基金獎助之申請程序?</a>, <a href="https://1966.gov.tw/LTC/cp-3977-42244-201.html" title="有關長照服務資源不足地區的定義,建議重新檢討及訂定檢討年限?">有關長照服務資源不足地區的定義,建議重新檢討及訂定檢討年限?</a>]
但是裡面還是有太多我們不需要的東西,因此再用個迴圈整理一下,把一個個的 <a> 變成 dict 的資料結構。
BeautifulSoup 中取得 Html tag 中的內容,使用
get()
q.get("href") 可取得 "https://1966.gov.tw/LTC/cp-3977-42249-201.html"。這是此問題的回答頁的連結,需要用getAnswer()再爬一次這個回答頁的內容,來解析內容。q.get("title") 可取得 "台灣的失智症長照服務資源量能?"
做成一個一個的 dict
{'url': 'https://1966.gov.tw/LTC/cp-3977-42249-201.html', 'q': '台灣的失智症長照服務資源量能?', 'a': '一、為因應我國快速增加的老年及失智人口,延緩及減輕失智症對社會及家庭的衝擊,並提供失智症及其家庭所需的醫療及照護需求,本部於102年8月公布「失智症防治照護政策網領」,訂定兩大目標及七大面向,以作為我國失智症照護發展方向。並結合跨部會機關依據政策綱領七大面向提出行動方案32項,並依各工作項目之效益指標達成目標,以完善失智症照護防治體系。\n二、為提升失智症社區服務普及性,擴增失智症長照服務量能,已推動措施如下:\n(一)97年起失智者已納入長照十年計畫,失智症長者可經一般失能之基本日常生活活動能力(ADL)或臨床失智評估量表(CDR)評估,判定失能或失智程度,核定補助時數,按老人之需求,提供失智老人適切長照服務。長照服務個案中失智症患者約占9.7%,截至104年5月底,提供失智症長照服務個案約1萬5千多人。\n(二)完善社區照護網絡-多元、在地服務及家庭照顧者:\n1.已完成185個多元日照服務單位(日照中心159個、日托據點26個),預計105年完成「一鄉鎮一日照」。\r\n2.失智專責服務:已設置日間照顧服務(17縣市共25處)、老人團體家屋(10個單位/83床) 、瑞智學堂(19縣市/60處)、失智症社區服務據點(28據點)、有失智症專區之機構 (41家,計1,317床;另規劃中7家239床)。\r\n3.建構家庭照顧者服務支持網絡:已設置失智症諮詢關懷專線,針對長照十年個案高風險家庭提供諮詢服務(1,141人/年);提供家庭照顧者照顧訓練(908/場;17,137人次/年),及建立失智症互助家庭(2,451人次)。\n(三)充足長照服務人力:已完成醫事長照專業三個階段培訓課程並展開訓練,至104年8月已訓練約30,000人次;又為讓在地人照顧在地人,擴大培養在地長照人力,100-104年8月止約訓練3200人次。\n(四) 提升民眾對失智症防治及照護的認知:\n1.全民教育:拍攝紀錄片如「被遺忘的時光」、「昨日的記憶」、憶起愛相隨」、「照顧者心情故事-居家服務」、製作失智症衛教手冊、認識失智症單張;辦理學校、職場宣導講座等進行教育宣導。\r\n2.社區健康促進網絡如結合社區關懷據點(1,978個) 辦理老人健康促進活動(6,359場;超過10萬人)。\r\n3.建構高齡友善機構及城市方面:通過認證機構,醫院有105家、長照機構有3家及1家衛生所;並於22縣市全面推動高齡友善城市,讓 280萬之長者受惠。\n三、未來規劃:\n(一) 104年5月已完成長期照顧服務法立法,可依法設置長照基金,發展服務及人力資源。\r\n(二) 整合原有之長照十年計畫與長照服務網基礎,推動長期照顧服務量能提升計畫。'}
{'url': 'https://1966.gov.tw/LTC/cp-3977-42248-201.html', 'q': '「高齡政策白皮書」與「人口白皮書」,這兩者的關係為何?何者應優先適用?', 'a': '(一) 人口政策白皮書所關注的人口議題包含了少子女化、高齡化、移民,高齡社會白皮書主要針對高齡者及未來高齡社會提出四大願景與相關具體行動措施。雖兩者皆有針對高齡化提出相關對策,但為因應人口老化迅速、家庭與生活型態改變與社會價值變遷的挑戰,我國必須針對當今社會之高齡多元需求,同時參考國際經驗與趨勢,必須即早提出更前瞻且整體性的政策規劃,以滿足我國高齡者能夠享有健康生活、幸福家庭、活力社會與友善環境,達到延長國人健康年數、減少失能老年人口的目標,並且整體提升高齡者生活幸福感。\r\n\xa0(二) 人口政策白皮書與高齡社會白皮書兩者並無衝突與適用之優先順序,高齡社會白皮書亦有融合人口政策白皮書之理念,並特別針對未來高齡人口需求延伸提出高齡政策之前瞻性架構與規劃,以共同實踐政府政策之願景。'}
{'url': 'https://1966.gov.tw/LTC/cp-3977-42245-201.html', 'q': '長照基金獎助之申請程序?', 'a': '1.本部長照十年計畫2.0-106年度補助計畫,106年部分,本部社家署已於106年1月12日以衛授家字第1060800004號函送本部「106年度運用社會福利基金辦理長照十年計畫2.0補助項目及基準」,將補助案件分為主軸計畫、整合型計畫及專案計畫等三類,可依該三類之補助項目、基準、作業程序辦理。\r\n2.107年(含)以後及非屬上開長照十年計畫2.0-106年度補助計畫經費之申請程序與相關作業規範,本部將另訂長照基金獎助作業要點。'}
{'url': 'https://1966.gov.tw/LTC/cp-3977-42244-201.html', 'q': '有關長照服務資源不足地區的定義,建議重新檢討及訂定檢討年限?', 'a': '1.現行長照服務資源不足地區,係依本部99年及103年辦理長照服務資源盤點所規劃之長照服務網區域劃分。\r\n2.本辦法第三條已明定「至少每五年辦理長照服務資源供需之調查」。\r\n3.將依前項辦理之調查結果,定期檢討長照服務資源不足地區之定義。'}
好了,這頁讀完了,下一頁怎麼辦,總不會還要再改網址重跑吧?
當然不是,下方可以看到有下一頁的按鈕,我們需要做的是,取得下一頁的 URL,一樣取得問題列表,直到最後一頁(沒有下一頁)。

根據 URL,取得該頁的完整 Html。
def getContent(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
return soup
大概的意思是,一直找有沒有下一頁的箭頭,有的話就取得下一頁的連結。沒有箭頭,就表示沒有下一頁,回傳 False。
def getNextPage(htmlContent):
if htmlContent.find('a', class_="icon-angle-right") is not None:
return htmlContent.find('a', class_="icon-angle-right").get("href")
else:
return False

根據前面取得問題列表時得到的答案頁 URL,再爬蟲一次,取得相應的答案。
BeautifulSoup 中
get_text()可以取得標籤中間的文字(不含標籤)
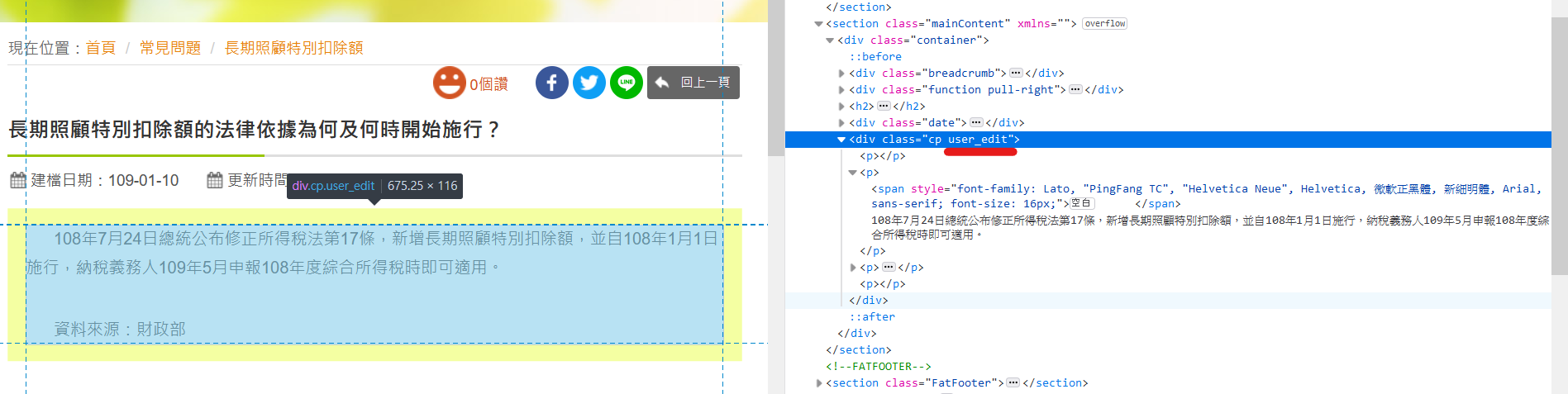
def getAnswer(answerUrl):
answerSoup = getContent(answerUrl)
answer = answerSoup.find("div", class_="user_edit").find("p")
return answer.get_text()
我最後用來建模型的 CSV 是還有經過整理的,使用 Excel 或 LibreOffice Calc 可以方便的去除重複資料和編號。
| 欄位 | 說明 |
|---|---|
| id | 流水號 |
| Intent ID | [已棄用] 這個欄位可以略過,這是之前與 Zenbo DDE 對應用的 |
| Q | 問題 |
| A | 答案 |
| url | 問答組合的出處 |
| category | 紀錄問答組合屬於何種類別,編號對應會在之後的文章介紹 |
今天就到這,謝謝大家。明天的主題是有關於,將這些爬下來的內容存成 CSV 檔,方便後續使用。明天見!
