輕巧有彈性的Lambda能解決轉檔、壓縮等簡單的處理運算,然而在AWS上如果要建立基本完整的ETL流程更適合的服務是AWS Glue。Glue是個無伺服器的資料整合服務,它提供分散式的 ETL 運算,且設計有相較於直接編寫程式碼更直覺的視覺化編寫介面讓使用者可以有效率的將自己的處理邏輯轉換成對應程式碼來執行資料整合工作。
Glue的常見的處理流程大概是:
建立Crawler爬蟲程式/編目程式來抓資料同時辨識資料格式,並替從資料源抓取下的資料建立記錄metadata 中繼資料的Data Catalog目錄以利之後查詢使用。這個流程可以隨需執行,也可以將其自動化方便管理大規模的資料整合工作。
Glue的基本元件有:
Classifier:分類器,可以選用預設資料格式(Grok/XML/JSON/CSV),功能是在爬取時判斷檔案是否是能處理的格式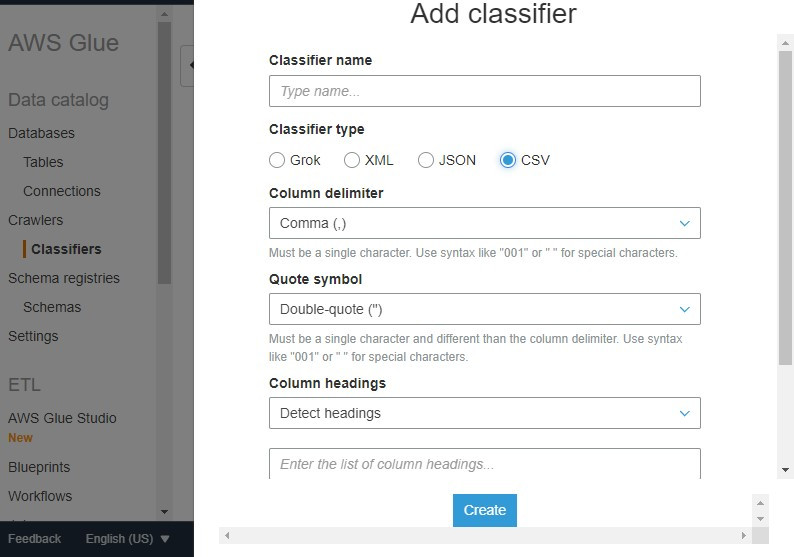
Crawler:編目程式,可以帶著分類器續爬取資料源,建立虛擬資料表,資料源的中繼資料存在資料庫
在左方工具欄找到Crawler分頁後即可建立新的編目程式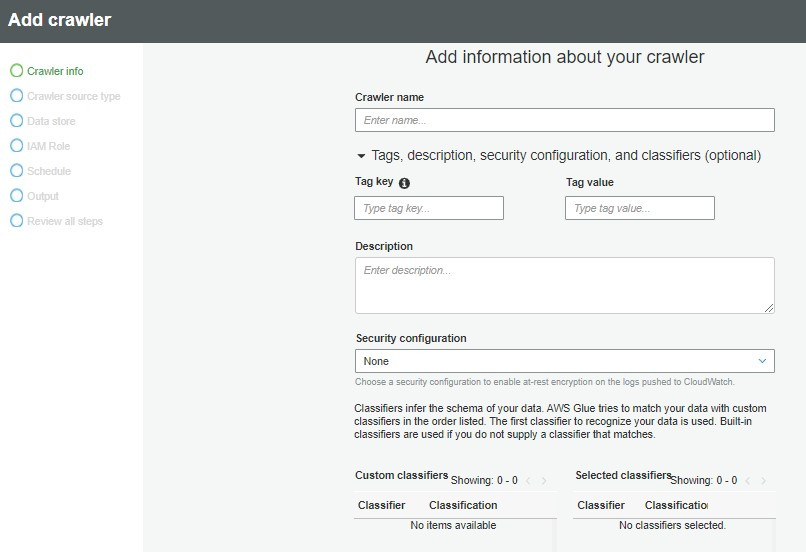
設定資料源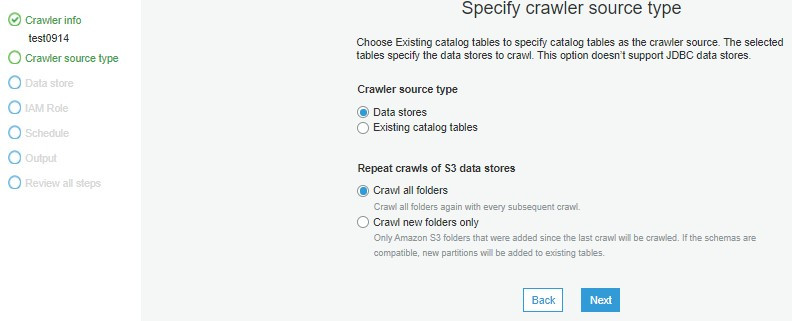
在第三步指定要使用的分類器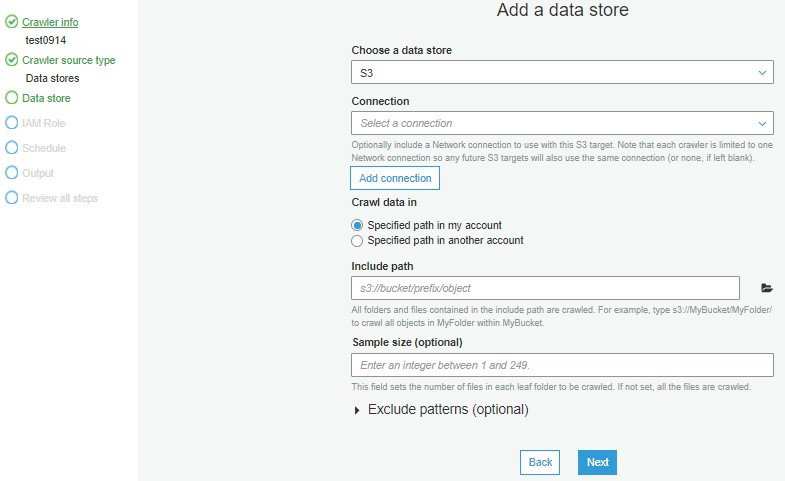
如果有多個資料源選yes
可以在這部直接新增的Role,或是提前先建立好擁有適當權限的Role(可至AWS IAM預建立)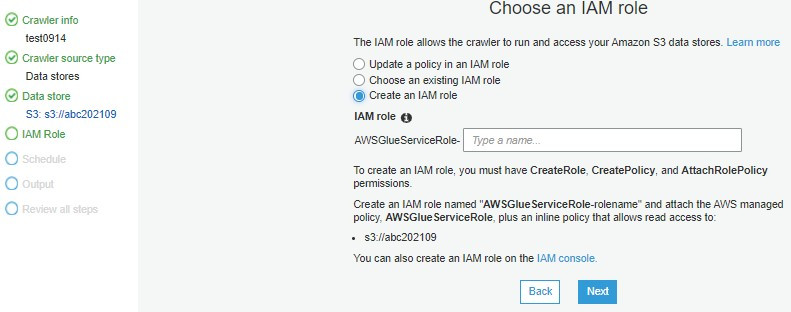
設定排程,測試的話就留著預設的on demand即可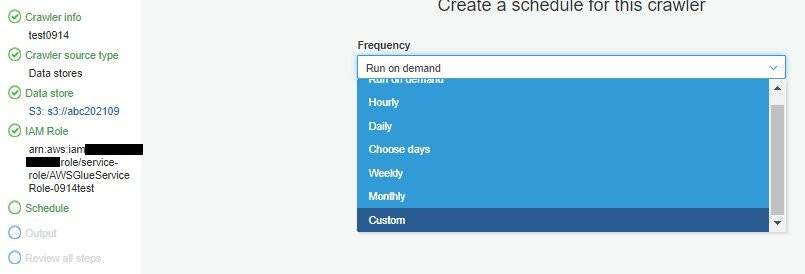
設定存放目的地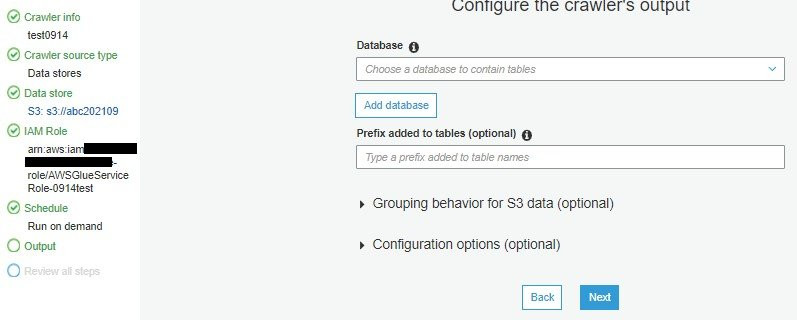
最後可以檢查所有的設定值後點選建立就完成
要執行可以回到Crawler分頁,要先勾選要執行的編目程式,再點選Action後選擇執行