接續基本元件介紹:Glue ETL功能欄中的可以建立ETL Job、Workflow和Blueprint
ETL Jobl:可以在Jobs分頁中建立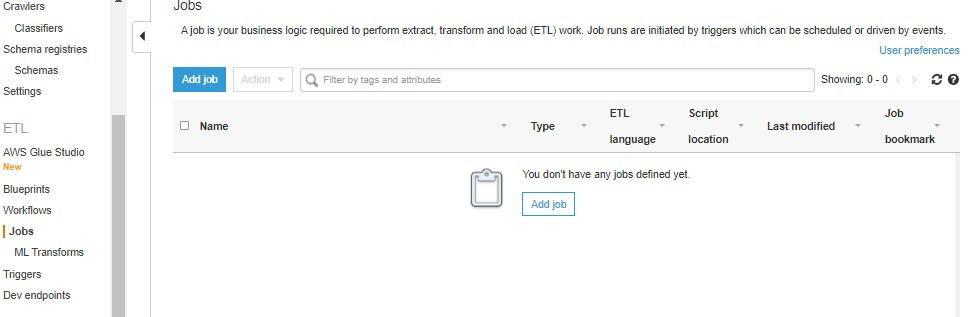
有三種Job工作類別可以選擇
Python Shell: 可以執行預存的Python Script,底層並不是分散式運算的計算量,算是資料量介於Lambda和分散式Spark job之間的工具選擇,也適合較簡單的處理流程但比起lambda它沒有執行時間的限制。
Spark*: 可執行pySpark或Scala所撰寫的分散式處理工作,有版本可以選擇
Spark Streaming:可執行pySpark或Scala所撰寫的分散式處理工作,適用針對串流資料的應用場景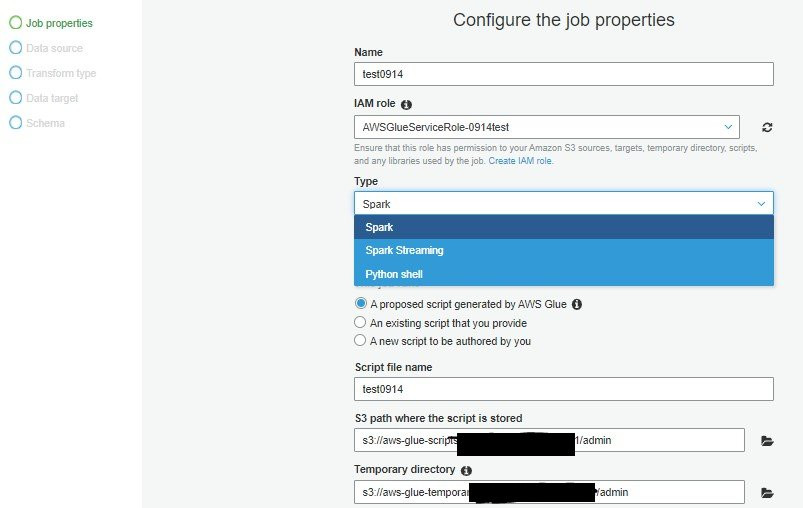
設定時需要指定script的存放地與資料處理的暫存地,預設會在S3
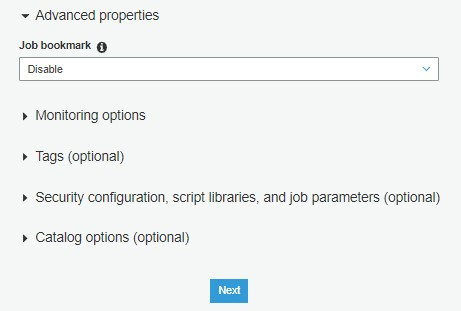
值得一提的功能是Job bookmark,適用資料源需要更新CDC的應用場景,可以在第一步開啟
設定資料源
設定建立資料架構類型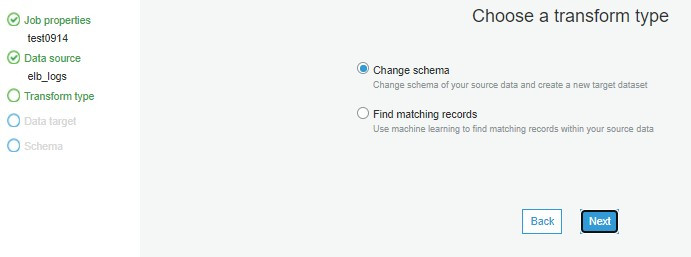
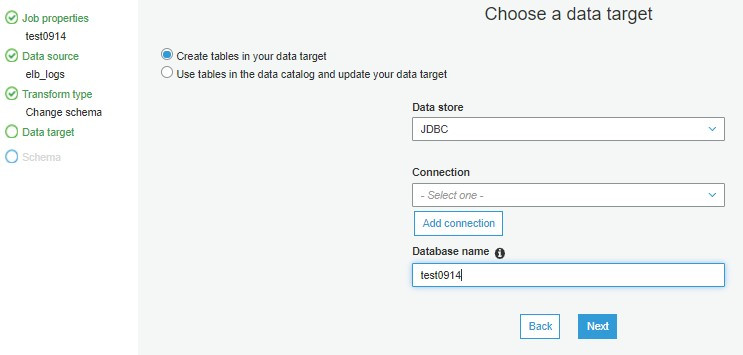
設定存放目的地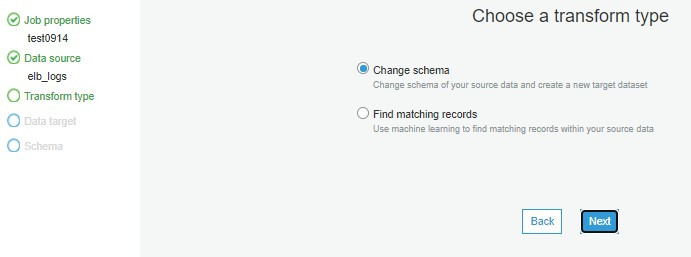
最後設定欄位的映射,如果要修改資料格式可以在這裡調整或是拿掉不需要的欄位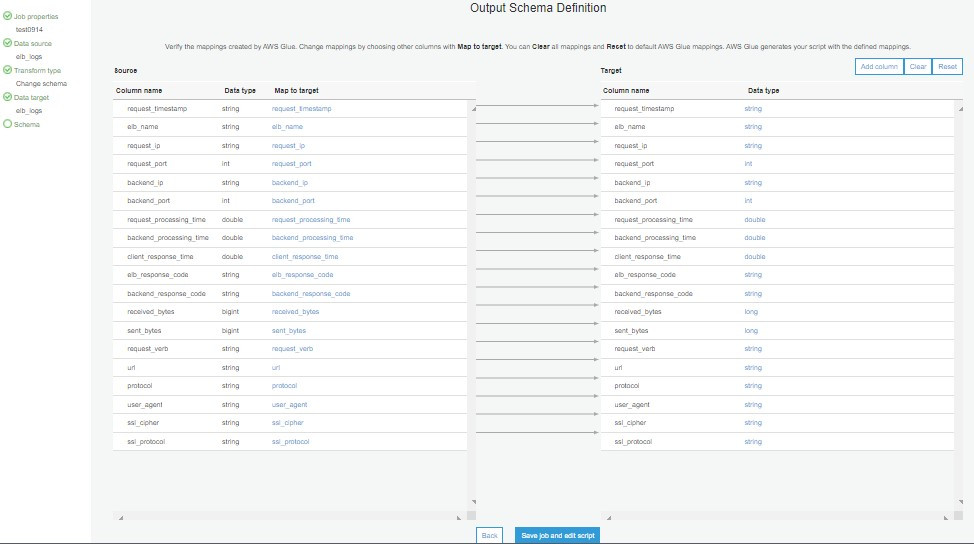
確定後可以進入編寫程式碼的頁面
經過剛剛的設定Glue會產出對應程式碼,在左方可以看見程式碼邏輯的視覺化流程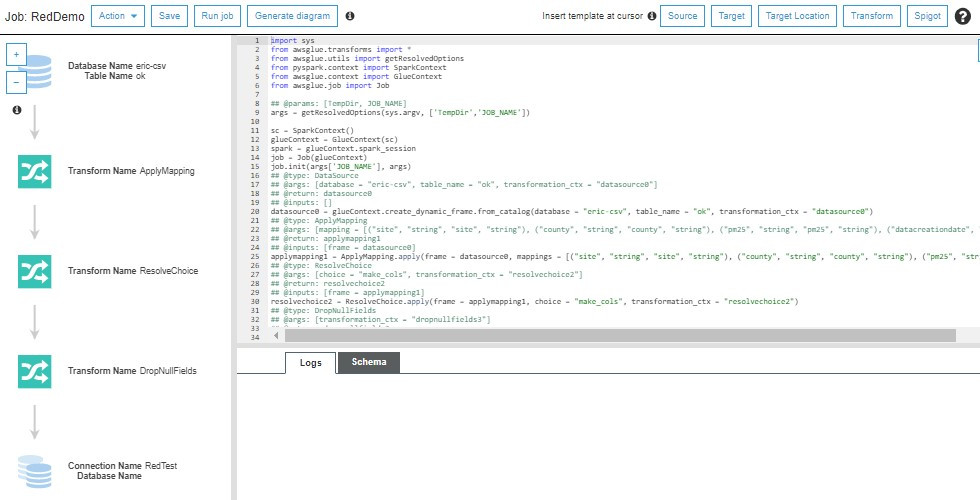
儲存後可以回到Job分頁中 勾選要執行的Job後點選上方Action下拉選單來查執行與查詢指標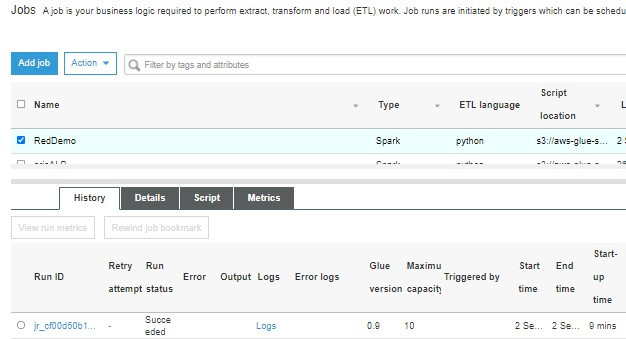
Trigger:觸發器,可以讓所建立的Job的排程或是讓它能夠被事件趨動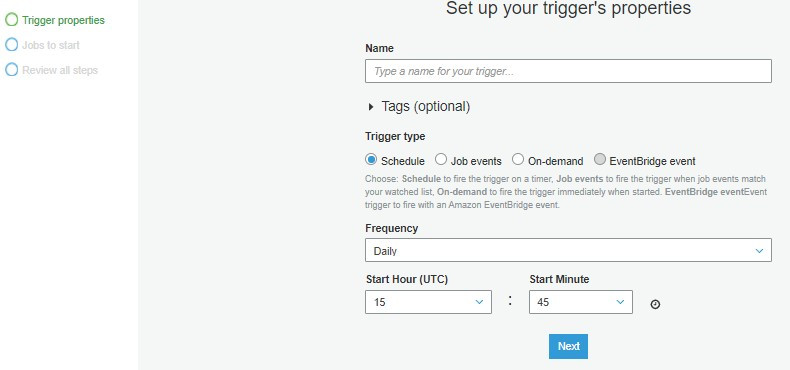
要設定較複雜的ETL流程可以用以下兩個功能:
Workflows : 可以圖形化拖拉設定自動化的ETL工作安排,方便管理有順序性的任務集合,進而同時觸發多個工作。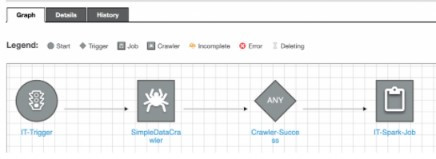
Blueprint:可以將參數指定給workflow與安排不同的workflow來處理類似的ETL專案。
*Spark ( https://zh.wikipedia.org/wiki/Apache_Spark )

