這篇原本是要在25號發的,因為一些因素,只好延遲到這一天了。
全部的監控項目內容會過於龐大且不是主軸,於是放一些付費的監控指標,免費的功能就讓各位自己上去體驗了(官網的說明文件很詳盡)。
可以看到付費等級的監控服務和免費版的 Filter UI 是一樣的,但是時間區間就無法改日期,只有當天。

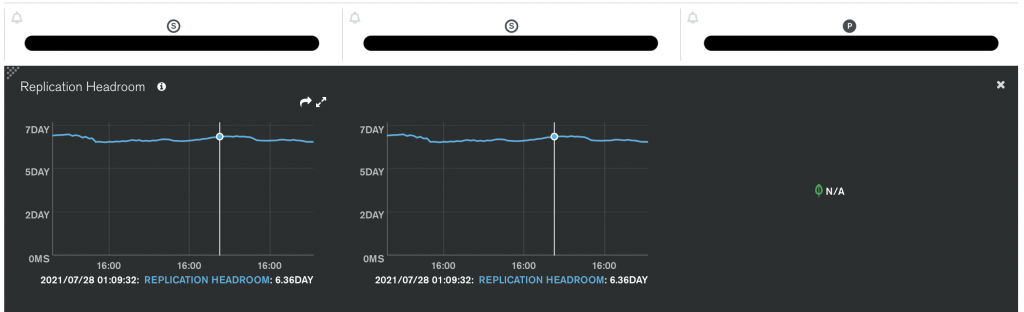
這張圖直接完整揭露付費的監控指標(官網完整說明),在免費版只能看到少數幾個,在前面有提到了。這個部分想特別提的是 replication 的監控,在 Atlas 中請特別注意這些項目:
顧名思義就是主節點 Oplog 每小時產生的 GB 數,降低此值能夠有效減緩其他圖表的警告。簡單來說就是把源頭降低,就不會衍伸出其他問題,這邊不是要我們一昧地降低,而是做必要性降低,特別是 schema 設計以及情境設計。
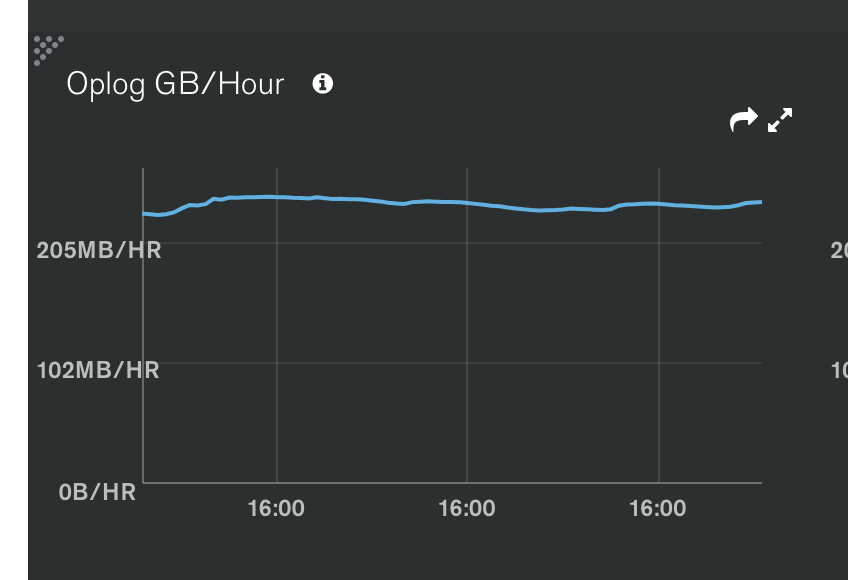
Replication Lag 表示你的次節點資料複製落後主節點多久,時間越長表示資料同步差異越大,如果時間不斷地變長,可能要考慮一下讀寫頻率是否太多以及必要性,導致次節點抄寫來不及。這個在之前 Oplog 相關文章有提到一些建議,可以回頭參考。
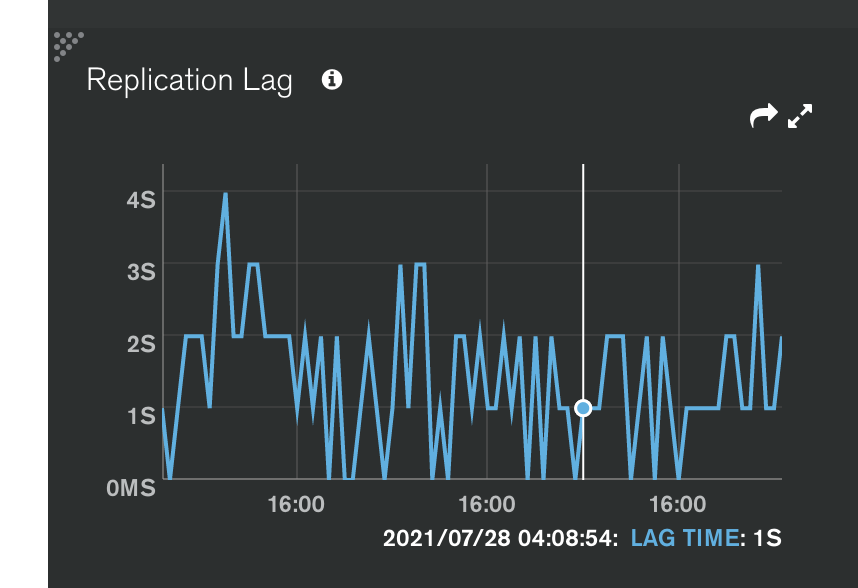
這個圖是按照當前 Oplog 寫入的速度來推算,系統 Oplog 還有多久會寫滿。配合上面的資訊,如果當前預估剩下 1 hour 寫滿,而次節點已經落後 1 hour 以上,就會出發次節點的 full resync 動作,強制讓次節點優先同步主節點資料。
提高 oplog 的大小可以提升剩餘時間,畢竟你的緩衝就越大,但還是要去查看這麼大量個修改是否有其必要。至於剩下多少時間是合理的,要看服務的內容以及各位的心臟強度,沒有一定的值是安全的。
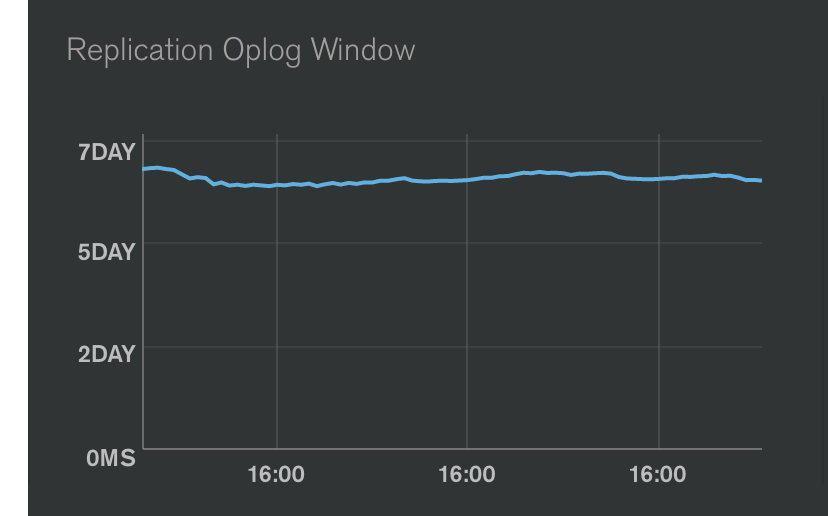
這個項目跟 Replication Oplog Window 很相似,是主節點 Oplog 剩餘量 與 次節點延遲的時間,當此值降為 0 時,就會觸發次節點進入 Recovering 狀態,也就是在做 full resync。這個指標已經建立在其他指標之上,所以進行快速監控時,挑選某一些即可,定期再去掃其他指標,監看 MongoDB 狀態是否正常。
每秒鐘於主節點執行了多少次操作,其中這些操作包含了 query, insert, update, delete, getMore, command。通常可以分析哪些時刻是高峰期,是否可以將這些分散在各個時間點。而每個高峰時刻又是哪些操作居多,是不是可以進一步優化。
同上,只是圖表顯示的是次節點。
可以從實際監控中看到兩種指標的差異。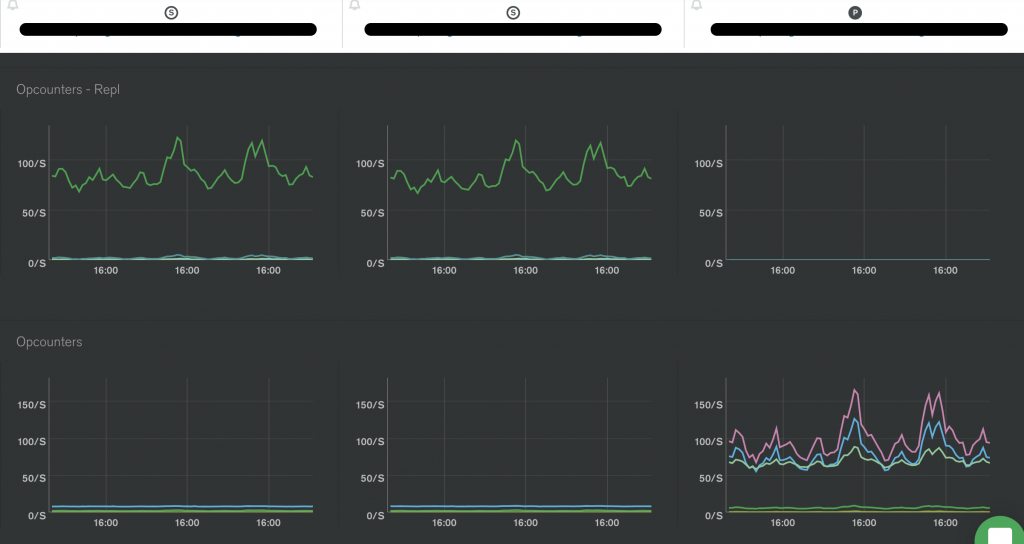
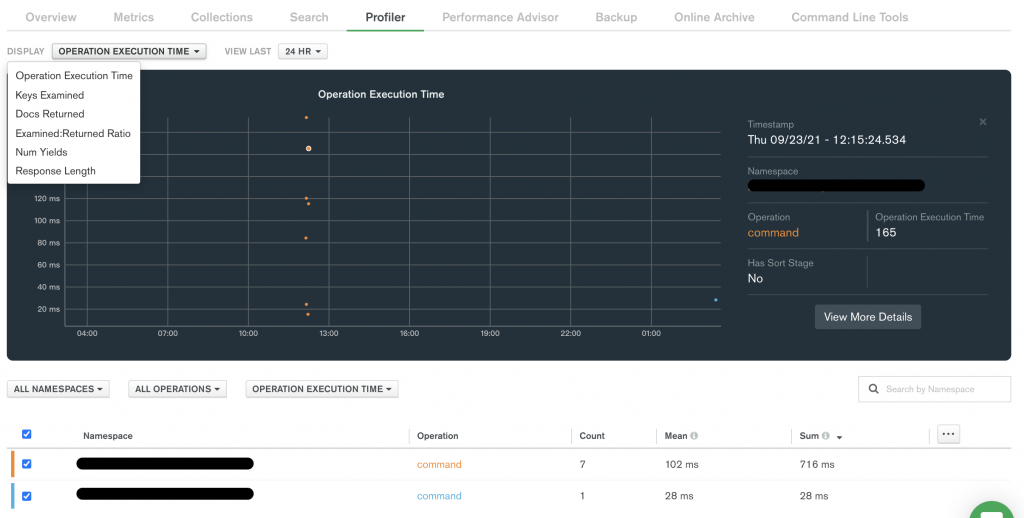
Profiler 部分左上角是所有項目,下方會列出所有指令操作, 次數和平均時間,讓你可以知道哪些操作平均花費時間高。回頭來想其實透過對 profiler 集合進行 aggregation 操作也是能辦到的(or mongostat),當然就是比較麻煩,少了畫面的拖拉,但整合各個操作的圖表呈現就沒辦法了,整體來說這個項目上線初期會很常使用。
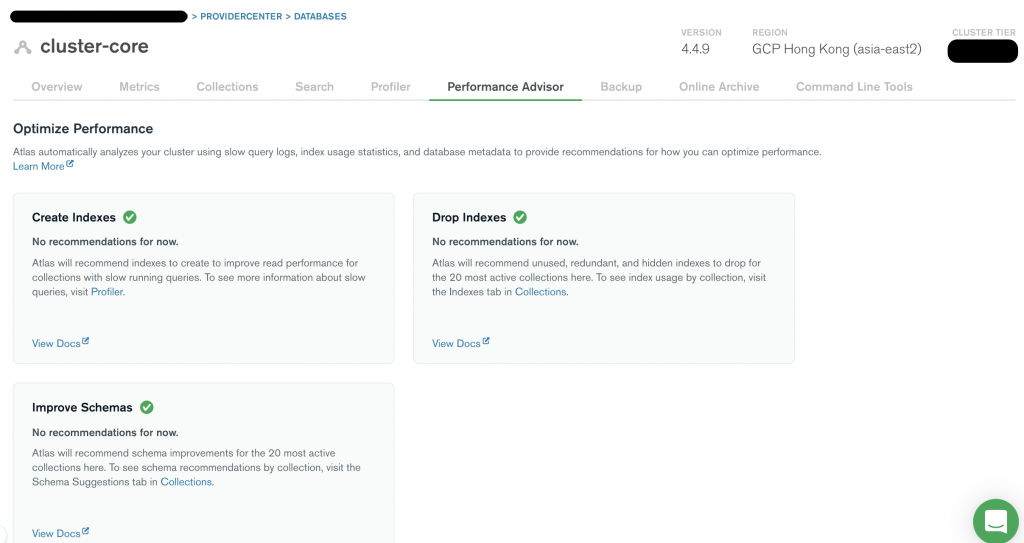
這個功能會針對目前 MongoDB 運行的狀況給予建議,主要是
長時間未使用的索引
如果有索引長時間沒有被使用,這個功能會建議你查看這個索引是否還有需要。
效能低落的索引
有些索引可能評估錯,或是需求面修改了,但忘記重新檢驗索引設計,導致索引效能不彰,系統會挑出來建議給你。
Collection Scan 語法
系統會自動幫你記錄是否有 Collection scan 的產生,有的話會告訴你詳細資訊並提出警告。
這三種不是完全對應到上圖的三個項目,但是都包含在內。
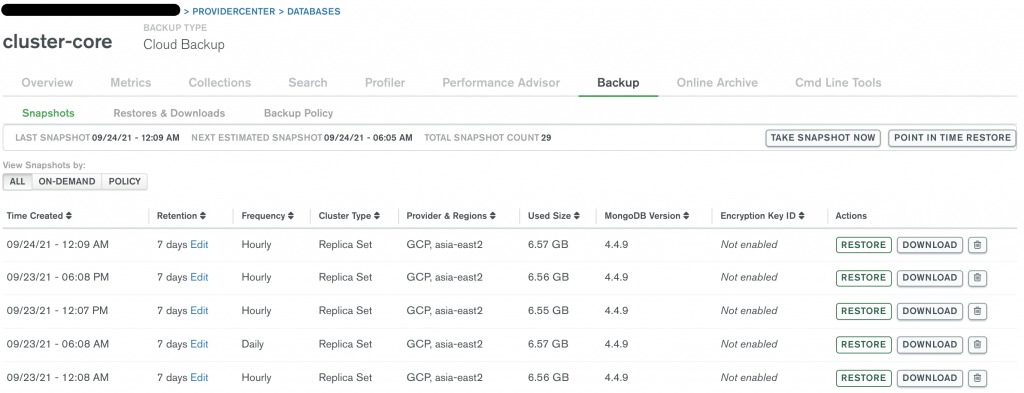
即時的備份機制。可以看到頻率設定上有每小時或是每天,也有 retention 時間,讓你在需要回復備份時,可以直接進行操作。
會想要寫這篇的原因是覺得 Atlas 很可惜,這些功能在免費版看不到,所以蠻多維運的人不知道 Atlas 的強大與方便(也許可以建議官方提供一些 fixed sample 來幫助推廣)。不知道大家都怎麼做 MongoDB 的監控呢?
本系列文章會同步發表於我個人的部落格 Pie Note

