在前面的日誌介紹中,可以透過slow log紀錄去找到有問題執行時間久的SQL語句,那有了資料後該如何去改善優化?
在查詢SQL前加上(EXPLAIN指令)返回的資訊能幫助你分析這句SQL執行的方式,判斷資料表中建立的索引有沒有如預期的去使用到該組合,提升查詢效率。
以熟悉的例子來用,先看以下表結構XD 
CREATE TABLE `act` (
`actives_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`status` tinyint(4) NOT NULL,
`start_time` int(11) unsigned NOT NULL,
`end_time` int(11) unsigned NOT NULL,
`platform_id` bigint(20) NOT NULL,
`updated_at` int(11) unsigned NOT NULL,
`created_at` int(11) unsigned NOT NULL,
PRIMARY KEY (`actives_id`),
KEY `pid_status` (`platform_id`,`status`)
)
CREATE TABLE `act_name` (
`actives_id` bigint(20) NOT NULL COMMENT 'ID',
`actives_name` varchar(40) NOT NULL,
`language` varchar(40) NOT NULL,
`created_at` int(11) unsigned NOT NULL,
PRIMARY KEY (`actives_id`,`language`)
)
CREATE TABLE `act_game` (
`actives_id` bigint(20) NOT NULL COMMENT 'ID',
`game_name` varchar(40) NOT NULL,
`support_rules` text NOT NULL,
`type` tinyint(4) NOT NULL,
`created_at` int(11) unsigned NOT NULL,
PRIMARY KEY (`actives_id`,`game_name`),
KEY `game` (`game_name`)
)
mysql> select * from act;
+------------+--------+------------+------------+----------------+------------+------------+
| actives_id | status | start_time | end_time | platform_id | updated_at | created_at |
+------------+--------+------------+------------+----------------+------------+------------+
| 1 | 1 | 1611504000 | 1632931200 | 10868213102191 | 1632499200 | 1632499200 |
+------------+--------+------------+------------+----------------+------------+------------+
1 row in set (0.00 sec)
mysql> select * from act_game;
+------------+-----------------+-------------------------------+------+------------+
| actives_id | game_name | support_rules | type | created_at |
+------------+-----------------+-------------------------------+------+------------+
| 1 | INVEST-ITHOME21 | ["w102","w103","q200","z920"] | 7 | 1632499200 |
| 2 | INVEST-ITHOME99 | ["z920"] | 5 | 1632499200 |
+------------+-----------------+-------------------------------+------+------------+
2 rows in set (0.00 sec)
mysql> select * from act_name;
+------------+--------------+----------+------------+
| actives_id | actives_name | language | created_at |
+------------+--------------+----------+------------+
| 1 | test2 | ch | 1632499205 |
| 1 | test1 | en | 1632499200 |
| 1 | test3 | jp | 1632499209 |
| 3 | test01 | ch | 1632499220 |
| 3 | test02 | en | 1632499225 |
| 3 | test03 | jp | 1632499230 |
+------------+--------------+----------+------------+
6 rows in set (0.00 sec)
(分析) Example: 搜尋活動ID=1資料SQL
explain select * from act where actives_id = 1;
在該表結構中actives_id為我們的PK,在此搜尋條件下的分析中確實使用到的index就是PRIMARY。
看到分析中的Key欄位部分,顯示了mysql實際採用哪個索引來優化對該表的訪問,如果SQL沒有使用到任何索引值會是NULL。
認識EXPLAIN分析中各欄位值意義
id
查詢標示符。
注意:
一句查詢中可能根據條件子查詢等可能會有多筆執行分析。
ID大小: id值越大,優先度高也代表越先執行。
ID相同: 代表相同的優先度,執行順序可以由上往下看就好。
Example:
Example: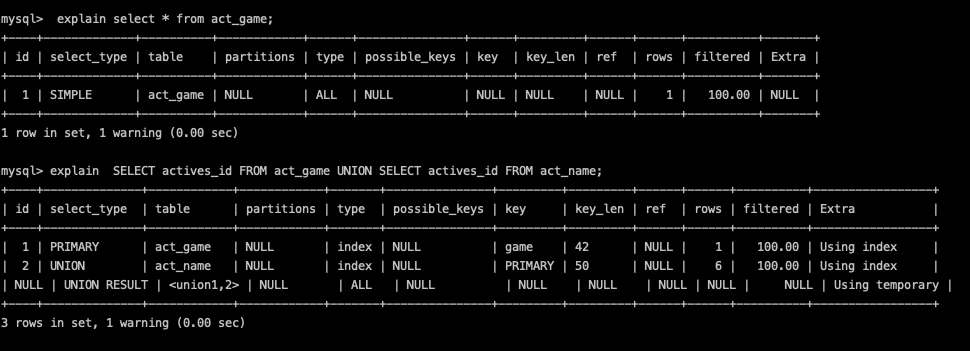
table
顯示查詢使用的表名。
partitions
顯示此查詢命中了有做資料表分區的哪些分區。

type -重要-
顯示連接使用的類型,可以用來判斷該語句執行效能好壞。這邊對幾個常見的做範例~
類型分類排序(最優 -> 差)
System : const type的特殊情況。
const : 查詢使用主鍵或唯一索引時,表返回僅有一行。
eq_ref : 在連結表查詢中使用PK或唯一索引作為關聯條件時,返回的資料對於前表的每個結果都只能匹配到後表的一行結果。
透過下面舉例看這段話的意思比較一下差異~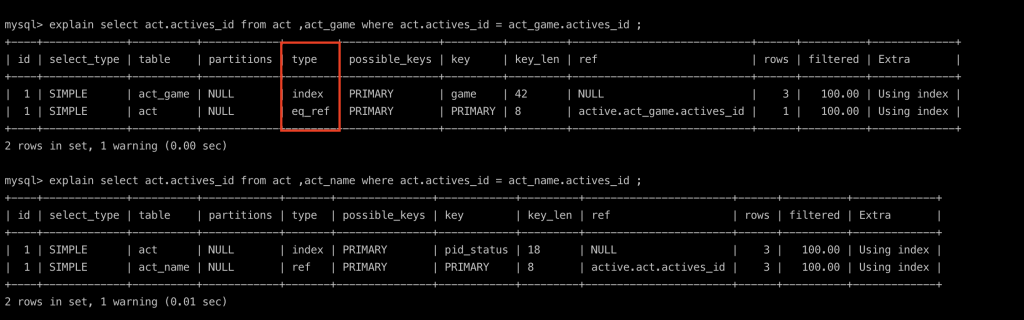
ref : 一般針對於使用非唯一索引的查詢,或普通索引查詢的條件滿足索引的最左匹配原則(不知道的回去看幾篇文章有提到複合索引的最左匹配原則)。
Example. 在act表中有一組索引: pid_status(platform_id,status)
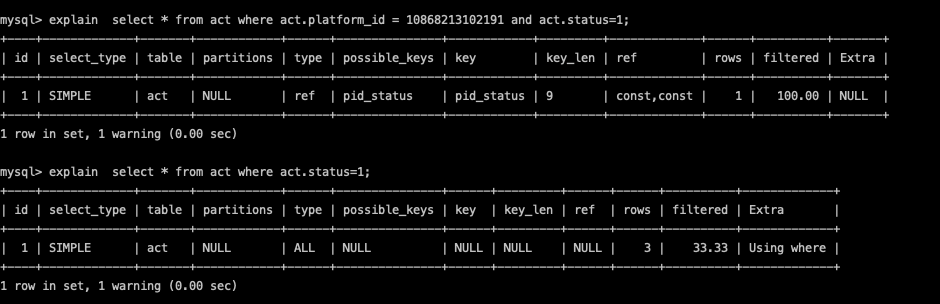
fulltext : 使用到全文索引。 MYSQL 全文索引
ref_or_null : 類似於ref,差別在於條件中對NULL資料的額外查詢。
因為我們的表結構關係,這樣設定會吃不到所以做一下調整。
1.PK 改成actives_id讓 is null 判斷條件觸發。
2.新增一組普通索引 game (game_name)。
CREATE TABLE `act_test` (
`actives_id` bigint(20) NOT NULL COMMENT 'ID',
`game_name` varchar(40) DEFAULT NULL,
`support_rules` text NOT NULL,
`type` tinyint(4) NOT NULL,
`created_at` int(11) unsigned NOT NULL,
PRIMARY KEY (`actives_id`) USING BTREE,
KEY `game` (`game_name`)
)

index_merge : 一個查詢中使用到索引合併優化觸發。
range : 使用到索引的範圍查詢。ex.(between , <= ...)
index : 全索引掃描。和ALL差別在於index是針對index tree掃描,ALL則是全表數據都掃。
ALL : 全表掃描。
當資料量大時在實務上的查詢,分析出來是這個代表該優化囉XD
possible_keys
可能使用到的索引。
key -重要-
實際查詢使用到的索引。
key_len
顯示查詢使用的索引長度。
(基本上越短越好,至於不同型態的長度計算規則有興趣可以去看看~)
ref
顯示哪些列or常量與指定索引的比較。
ex.常見的const: 使用常量等值查询,null...
rows -重要-
執行本次查詢找到結果估計需要讀取的數據行數。
(就是說你這句查詢需要掃描的行數,所以理想狀態是越少越好。)
filtered
顯示查詢返回後的數據在過濾後剩下滿足條件的紀錄數比例。
Extra -重要-
顯示如何解析此查詢的附加訊息。
(這裡的輔助資訊很重要!能幫助你針對語法的缺點做對應優化)
Example常見的
Using where: 有通過where的條件去過濾需要的內容。
Using temporary: 有使用到臨時表。
Using index: 使用到覆蓋索引。(不知道的回前2天文章看有提到~)
Using filesort: 查詢的內容需做额外的排序,無法透過索引的順序達到排序。 (欠優化)
....
到這裡對優化的訊息有了基本的認識,不過說真的實際去做語法優化又是另一回事,能給你方向但不代表index照著敘述規則設定一定會得到對應資訊吃到index,可能會因為其他因素導致,重點還是在於經驗的累積。 
參考文件:
MYSQL EXPLAIN官方文件
https://database.51cto.com/art/202005/617071.htm


 iThome鐵人賽
iThome鐵人賽